 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe nextAI Solution to the NeurIPS 2023 LLM Efficiency Challenge
Apr 10, 2026The rapid evolution of Large Language Models (LLMs) has significantly impacted the field of natural language processing, but their growing complexity raises concerns about resource usage and transparency. Addressing these challenges, we participated in the NeurIPS LLM Efficiency Challenge, aiming to fine-tune a foundation model within stringent constraints. Our focus was the LLaMa2 70 billion model, optimized on a single A100 40GB GPU within a 24-hour limit. Our methodology hinged on a custom dataset, carefully assembled from diverse open-source resources and benchmark tests, aligned with the challenge's open-source ethos. Our approach leveraged Quantized-Low Rank Adaptation (QLoRA) Fine tuning, integrated with advanced attention mechanisms like Flash Attention 2. We experimented with various configurations of the LoRA technique, optimizing the balance between computational efficiency and model accuracy. Our fine-tuning strategy was underpinned by the creation and iterative testing of multiple dataset compositions, leading to the selection of a version that demonstrated robust performance across diverse tasks and benchmarks. The culmination of our efforts was an efficiently fine-tuned LLaMa2 70B model that operated within the constraints of a single GPU, showcasing not only a significant reduction in resource utilization but also high accuracy across a range of QA benchmarks. Our study serves as a testament to the feasibility of optimizing large-scale models in resource-constrained environments, emphasizing the potential of LLMs in real-world applications.
NexusSum: Hierarchical LLM Agents for Long-Form Narrative Summarization
May 30, 2025Summarizing long-form narratives--such as books, movies, and TV scripts--requires capturing intricate plotlines, character interactions, and thematic coherence, a task that remains challenging for existing LLMs. We introduce NexusSum, a multi-agent LLM framework for narrative summarization that processes long-form text through a structured, sequential pipeline--without requiring fine-tuning. Our approach introduces two key innovations: (1) Dialogue-to-Description Transformation: A narrative-specific preprocessing method that standardizes character dialogue and descriptive text into a unified format, improving coherence. (2) Hierarchical Multi-LLM Summarization: A structured summarization pipeline that optimizes chunk processing and controls output length for accurate, high-quality summaries. Our method establishes a new state-of-the-art in narrative summarization, achieving up to a 30.0% improvement in BERTScore (F1) across books, movies, and TV scripts. These results demonstrate the effectiveness of multi-agent LLMs in handling long-form content, offering a scalable approach for structured summarization in diverse storytelling domains.
CREFT: Sequential Multi-Agent LLM for Character Relation Extraction
May 30, 2025Understanding complex character relations is crucial for narrative analysis and efficient script evaluation, yet existing extraction methods often fail to handle long-form narratives with nuanced interactions. To address this challenge, we present CREFT, a novel sequential framework leveraging specialized Large Language Model (LLM) agents. First, CREFT builds a base character graph through knowledge distillation, then iteratively refines character composition, relation extraction, role identification, and group assignments. Experiments on a curated Korean drama dataset demonstrate that CREFT significantly outperforms single-agent LLM baselines in both accuracy and completeness. By systematically visualizing character networks, CREFT streamlines narrative comprehension and accelerates script review -- offering substantial benefits to the entertainment, publishing, and educational sectors.
Agent-as-Judge for Factual Summarization of Long Narratives
Jan 17, 2025



Large Language Models (LLMs) have demonstrated near-human performance in summarization tasks based on traditional metrics such as ROUGE and BERTScore. However, these metrics do not adequately capture critical aspects of summarization quality, such as factual accuracy, particularly for long narratives (>100K tokens). Recent advances, such as LLM-as-a-Judge, address the limitations of metrics based on lexical similarity but still exhibit factual inconsistencies, especially in understanding character relationships and states. In this work, we introduce NarrativeFactScore, a novel "Agent-as-a-Judge" framework for evaluating and refining summaries. By leveraging a Character Knowledge Graph (CKG) extracted from input and generated summaries, NarrativeFactScore assesses the factual consistency and provides actionable guidance for refinement, such as identifying missing or erroneous facts. We demonstrate the effectiveness of NarrativeFactScore through a detailed workflow illustration and extensive validation on widely adopted benchmarks, achieving superior performance compared to competitive methods. Our results highlight the potential of agent-driven evaluation systems to improve the factual reliability of LLM-generated summaries.
Multimodal Representation Learning of Cardiovascular Magnetic Resonance Imaging
Apr 16, 2023Self-supervised learning is crucial for clinical imaging applications, given the lack of explicit labels in healthcare. However, conventional approaches that rely on precise vision-language alignment are not always feasible in complex clinical imaging modalities, such as cardiac magnetic resonance (CMR). CMR provides a comprehensive visualization of cardiac anatomy, physiology, and microstructure, making it challenging to interpret. Additionally, CMR reports require synthesizing information from sequences of images and different views, resulting in potentially weak alignment between the study and diagnosis report pair. To overcome these challenges, we propose \textbf{CMRformer}, a multimodal learning framework to jointly learn sequences of CMR images and associated cardiologist's reports. Moreover, one of the major obstacles to improving CMR study is the lack of large, publicly available datasets. To bridge this gap, we collected a large \textbf{CMR dataset}, which consists of 13,787 studies from clinical cases. By utilizing our proposed CMRformer and our collected dataset, we achieved remarkable performance in real-world clinical tasks, such as CMR image retrieval and diagnosis report retrieval. Furthermore, the learned representations are evaluated to be practically helpful for downstream applications, such as disease classification. Our work could potentially expedite progress in the CMR study and lead to more accurate and effective diagnosis and treatment.
RegCLR: A Self-Supervised Framework for Tabular Representation Learning in the Wild
Nov 02, 2022Recent advances in self-supervised learning (SSL) using large models to learn visual representations from natural images are rapidly closing the gap between the results produced by fully supervised learning and those produced by SSL on downstream vision tasks. Inspired by this advancement and primarily motivated by the emergence of tabular and structured document image applications, we investigate which self-supervised pretraining objectives, architectures, and fine-tuning strategies are most effective. To address these questions, we introduce RegCLR, a new self-supervised framework that combines contrastive and regularized methods and is compatible with the standard Vision Transformer architecture. Then, RegCLR is instantiated by integrating masked autoencoders as a representative example of a contrastive method and enhanced Barlow Twins as a representative example of a regularized method with configurable input image augmentations in both branches. Several real-world table recognition scenarios (e.g., extracting tables from document images), ranging from standard Word and Latex documents to even more challenging electronic health records (EHR) computer screen images, have been shown to benefit greatly from the representations learned from this new framework, with detection average-precision (AP) improving relatively by 4.8% for Table, 11.8% for Column, and 11.1% for GUI objects over a previous fully supervised baseline on real-world EHR screen images.
Medical Codes Prediction from Clinical Notes: From Human Coders to Machines
Oct 30, 2022Prediction of medical codes from clinical notes is a practical and essential need for every healthcare delivery organization within current medical systems. Automating annotation will save significant time and excessive effort that human coders spend today. However, the biggest challenge is directly identifying appropriate medical codes from several thousands of high-dimensional codes from unstructured free-text clinical notes. This complex medical codes prediction problem from clinical notes has received substantial interest in the NLP community, and several recent studies have shown the state-of-the-art code prediction results of full-fledged deep learning-based methods. This progress raises the fundamental question of how far automated machine learning systems are from human coders' working performance, as well as the important question of how well current explainability methods apply to advanced neural network models such as transformers. This is to predict correct codes and present references in clinical notes that support code prediction, as this level of explainability and accuracy of the prediction outcomes is critical to gaining trust from professional medical coders.
Can Current Explainability Help Provide References in Clinical Notes to Support Humans Annotate Medical Codes?
Oct 28, 2022


The medical codes prediction problem from clinical notes has received substantial interest in the NLP community, and several recent studies have shown the state-of-the-art (SOTA) code prediction results of full-fledged deep learning-based methods. However, most previous SOTA works based on deep learning are still in early stages in terms of providing textual references and explanations of the predicted codes, despite the fact that this level of explainability of the prediction outcomes is critical to gaining trust from professional medical coders. This raises the important question of how well current explainability methods apply to advanced neural network models such as transformers to predict correct codes and present references in clinical notes that support code prediction. First, we present an explainable Read, Attend, and Code (xRAC) framework and assess two approaches, attention score-based xRAC-ATTN and model-agnostic knowledge-distillation-based xRAC-KD, through simplified but thorough human-grounded evaluations with SOTA transformer-based model, RAC. We find that the supporting evidence text highlighted by xRAC-ATTN is of higher quality than xRAC-KD whereas xRAC-KD has potential advantages in production deployment scenarios. More importantly, we show for the first time that, given the current state of explainability methodologies, using the SOTA medical codes prediction system still requires the expertise and competencies of professional coders, even though its prediction accuracy is superior to that of human coders. This, we believe, is a very meaningful step toward developing explainable and accurate machine learning systems for fully autonomous medical code prediction from clinical notes.
Read, Attend, and Code: Pushing the Limits of Medical Codes Prediction from Clinical Notes by Machines
Jul 10, 2021

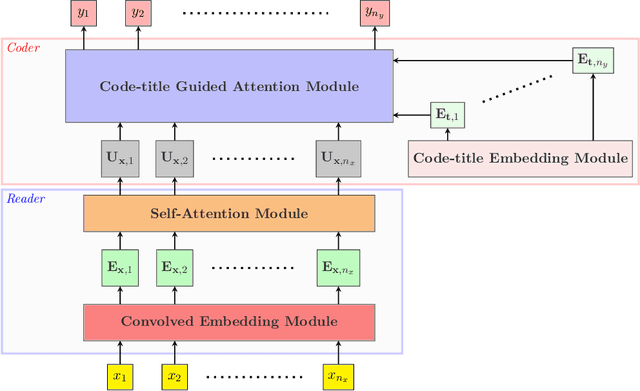
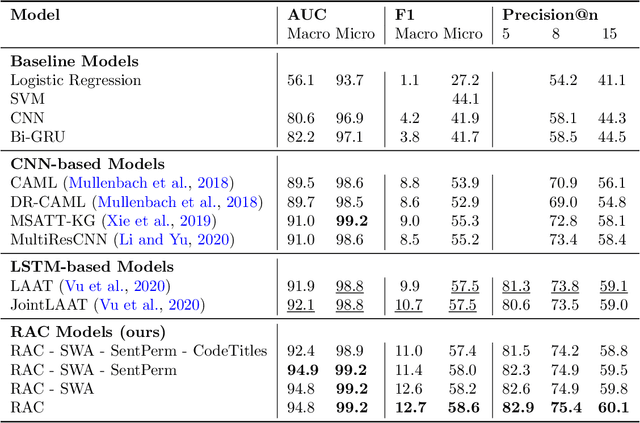
Prediction of medical codes from clinical notes is both a practical and essential need for every healthcare delivery organization within current medical systems. Automating annotation will save significant time and excessive effort spent by human coders today. However, the biggest challenge is directly identifying appropriate medical codes out of several thousands of high-dimensional codes from unstructured free-text clinical notes. In the past three years, with Convolutional Neural Networks (CNN) and Long Short-Term Memory (LTSM) networks, there have been vast improvements in tackling the most challenging benchmark of the MIMIC-III-full-label inpatient clinical notes dataset. This progress raises the fundamental question of how far automated machine learning (ML) systems are from human coders' working performance. We assessed the baseline of human coders' performance on the same subsampled testing set. We also present our Read, Attend, and Code (RAC) model for learning the medical code assignment mappings. By connecting convolved embeddings with self-attention and code-title guided attention modules, combined with sentence permutation-based data augmentations and stochastic weight averaging training, RAC establishes a new state of the art (SOTA), considerably outperforming the current best Macro-F1 by 18.7%, and reaches past the human-level coding baseline. This new milestone marks a meaningful step toward fully autonomous medical coding (AMC) in machines reaching parity with human coders' performance in medical code prediction.
Deep Claim: Payer Response Prediction from Claims Data with Deep Learning
Jul 13, 2020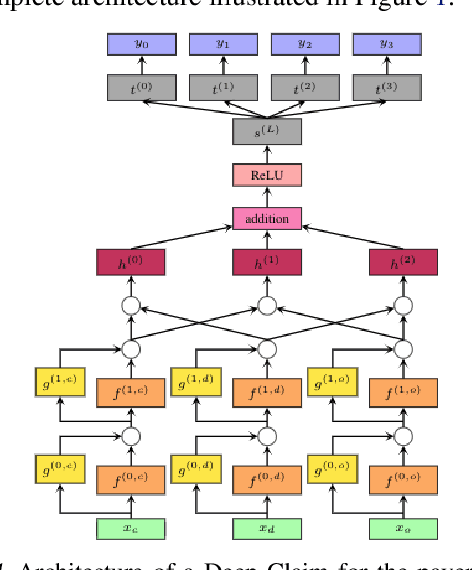


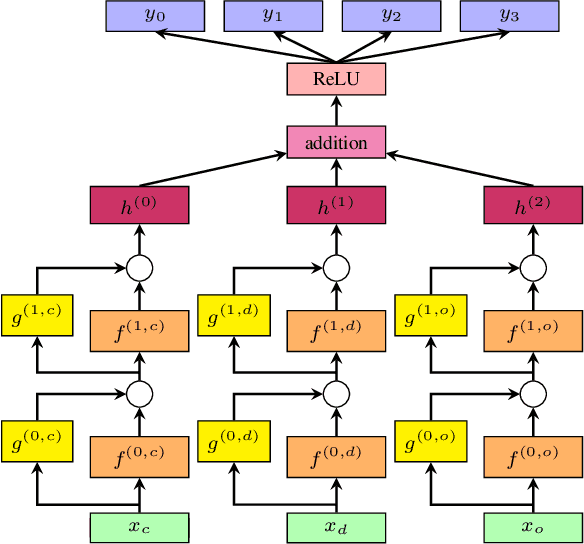
Each year, almost 10% of claims are denied by payers (i.e., health insurance plans). With the cost to recover these denials and underpayments, predicting payer response (likelihood of payment) from claims data with a high degree of accuracy and precision is anticipated to improve healthcare staffs' performance productivity and drive better patient financial experience and satisfaction in the revenue cycle (Barkholz, 2017). However, constructing advanced predictive analytics models has been considered challenging in the last twenty years. That said, we propose a (low-level) context-dependent compact representation of patients' historical claim records by effectively learning complicated dependencies in the (high-level) claim inputs. Built on this new latent representation, we demonstrate that a deep learning-based framework, Deep Claim, can accurately predict various responses from multiple payers using 2,905,026 de-identified claims data from two US health systems. Deep Claim's improvements over carefully chosen baselines in predicting claim denials are most pronounced as 22.21% relative recall gain (at 95% precision) on Health System A, which implies Deep Claim can find 22.21% more denials than the best baseline system.