 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTG-SSOD: Dense Teacher Guidance for Semi-Supervised Object Detection
Jul 12, 2022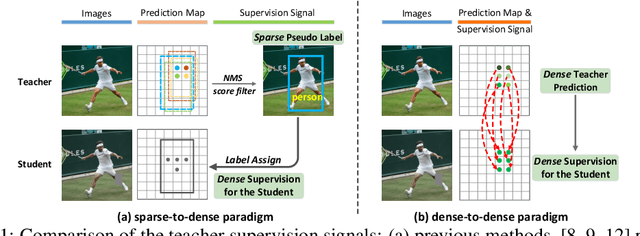
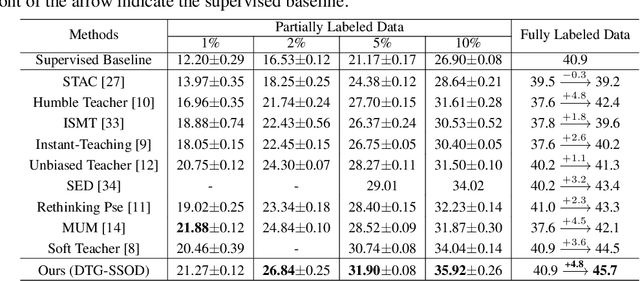
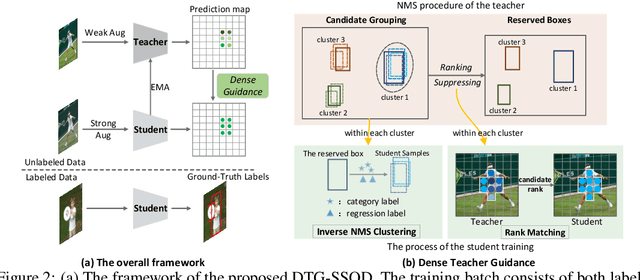
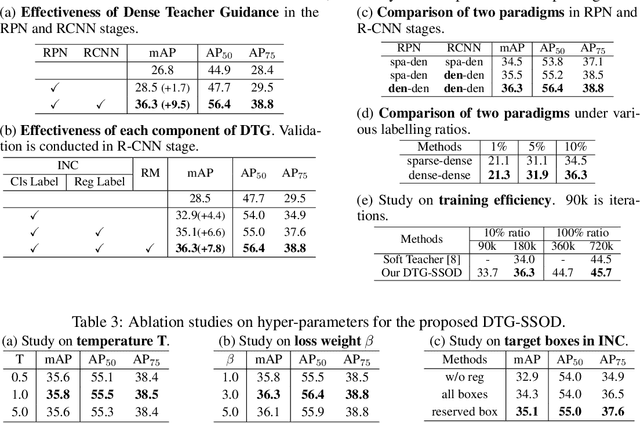
The Mean-Teacher (MT) scheme is widely adopted in semi-supervised object detection (SSOD). In MT, the sparse pseudo labels, offered by the final predictions of the teacher (e.g., after Non Maximum Suppression (NMS) post-processing), are adopted for the dense supervision for the student via hand-crafted label assignment. However, the sparse-to-dense paradigm complicates the pipeline of SSOD, and simultaneously neglects the powerful direct, dense teacher supervision. In this paper, we attempt to directly leverage the dense guidance of teacher to supervise student training, i.e., the dense-to-dense paradigm. Specifically, we propose the Inverse NMS Clustering (INC) and Rank Matching (RM) to instantiate the dense supervision, without the widely used, conventional sparse pseudo labels. INC leads the student to group candidate boxes into clusters in NMS as the teacher does, which is implemented by learning grouping information revealed in NMS procedure of the teacher. After obtaining the same grouping scheme as the teacher via INC, the student further imitates the rank distribution of the teacher over clustered candidates through Rank Matching. With the proposed INC and RM, we integrate Dense Teacher Guidance into Semi-Supervised Object Detection (termed DTG-SSOD), successfully abandoning sparse pseudo labels and enabling more informative learning on unlabeled data. On COCO benchmark, our DTG-SSOD achieves state-of-the-art performance under various labelling ratios. For example, under 10% labelling ratio, DTG-SSOD improves the supervised baseline from 26.9 to 35.9 mAP, outperforming the previous best method Soft Teacher by 1.9 points.
Learning Locality and Isotropy in Dialogue Modeling
May 29, 2022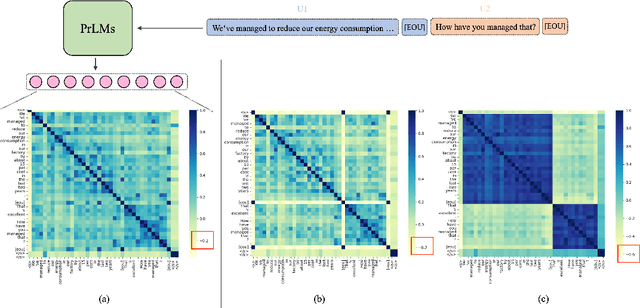
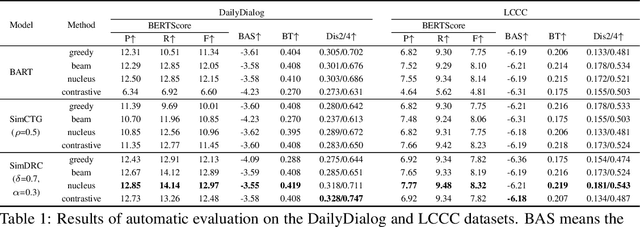
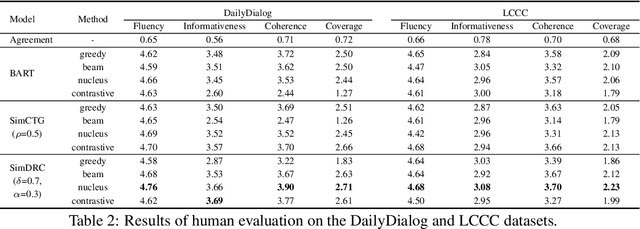
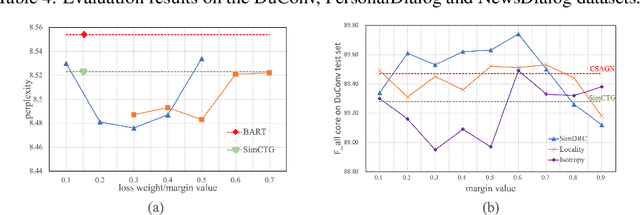
Existing dialogue modeling methods have achieved promising performance on various dialogue tasks with the aid of Transformer and the large-scale pre-trained language models. However, some recent studies revealed that the context representations produced by these methods suffer the problem of anisotropy. In this paper, we find that the generated representations are also not conversational, losing the conversation structure information during the context modeling stage. To this end, we identify two properties in dialogue modeling, i.e., locality and isotropy, and present a simple method for dialogue representation calibration, namely SimDRC, to build isotropic and conversational feature spaces. Experimental results show that our approach significantly outperforms the current state-of-the-art models on three dialogue tasks across the automatic and human evaluation metrics. More in-depth analyses further confirm the effectiveness of our proposed approach.
CoupleFace: Relation Matters for Face Recognition Distillation
Apr 12, 2022Knowledge distillation is an effective method to improve the performance of a lightweight neural network (i.e., student model) by transferring the knowledge of a well-performed neural network (i.e., teacher model), which has been widely applied in many computer vision tasks, including face recognition. Nevertheless, the current face recognition distillation methods usually utilize the Feature Consistency Distillation (FCD) (e.g., L2 distance) on the learned embeddings extracted by the teacher and student models for each sample, which is not able to fully transfer the knowledge from the teacher to the student for face recognition. In this work, we observe that mutual relation knowledge between samples is also important to improve the discriminative ability of the learned representation of the student model, and propose an effective face recognition distillation method called CoupleFace by additionally introducing the Mutual Relation Distillation (MRD) into existing distillation framework. Specifically, in MRD, we first propose to mine the informative mutual relations, and then introduce the Relation-Aware Distillation (RAD) loss to transfer the mutual relation knowledge of the teacher model to the student model. Extensive experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed CoupleFace for face recognition. Moreover, based on our proposed CoupleFace, we have won the first place in the ICCV21 Masked Face Recognition Challenge (MS1M track).
PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection
Mar 30, 2022
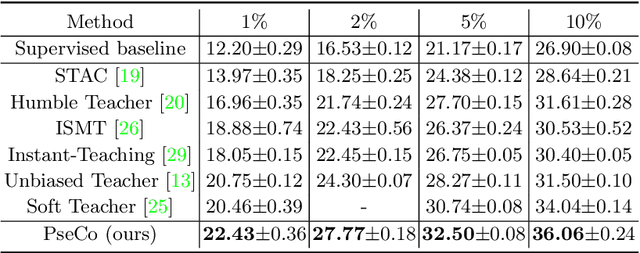
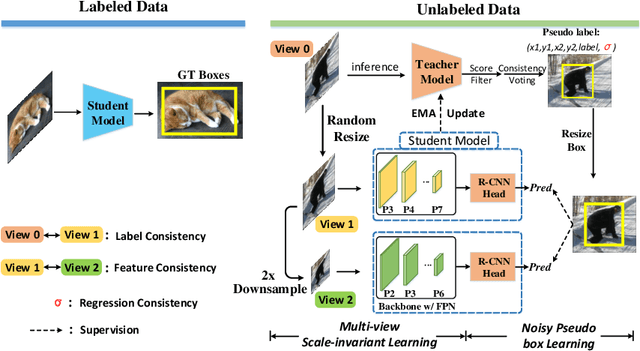
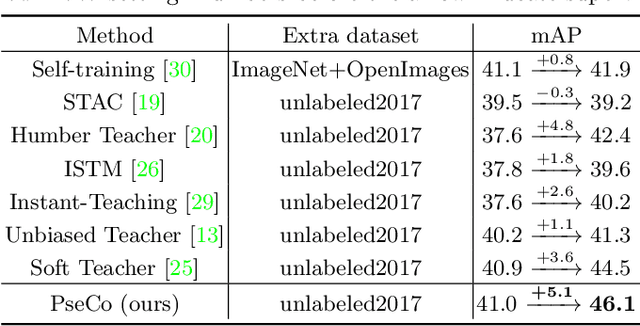
In this paper, we delve into two key techniques in Semi-Supervised Object Detection (SSOD), namely pseudo labeling and consistency training. We observe that these two techniques currently neglect some important properties of object detection, hindering efficient learning on unlabeled data. Specifically, for pseudo labeling, existing works only focus on the classification score yet fail to guarantee the localization precision of pseudo boxes; For consistency training, the widely adopted random-resize training only considers the label-level consistency but misses the feature-level one, which also plays an important role in ensuring the scale invariance. To address the problems incurred by noisy pseudo boxes, we design Noisy Pseudo box Learning (NPL) that includes Prediction-guided Label Assignment (PLA) and Positive-proposal Consistency Voting (PCV). PLA relies on model predictions to assign labels and makes it robust to even coarse pseudo boxes; while PCV leverages the regression consistency of positive proposals to reflect the localization quality of pseudo boxes. Furthermore, in consistency training, we propose Multi-view Scale-invariant Learning (MSL) that includes mechanisms of both label- and feature-level consistency, where feature consistency is achieved by aligning shifted feature pyramids between two images with identical content but varied scales. On COCO benchmark, our method, termed PSEudo labeling and COnsistency training (PseCo), outperforms the SOTA (Soft Teacher) by 2.0, 1.8, 2.0 points under 1%, 5%, and 10% labelling ratios, respectively. It also significantly improves the learning efficiency for SSOD, e.g., PseCo halves the training time of the SOTA approach but achieves even better performance.
Knowledge Distillation for Object Detection via Rank Mimicking and Prediction-guided Feature Imitation
Dec 09, 2021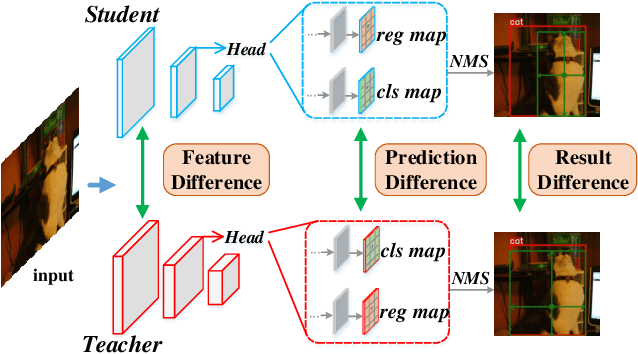
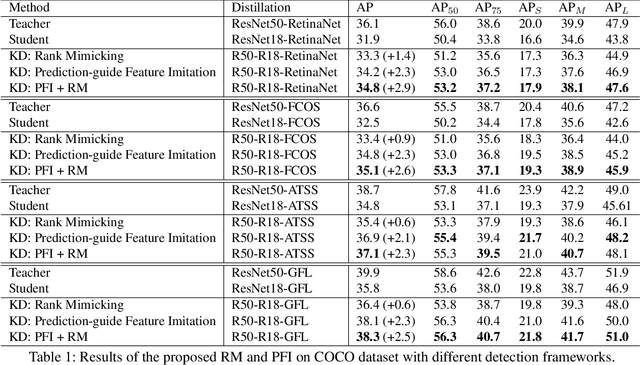
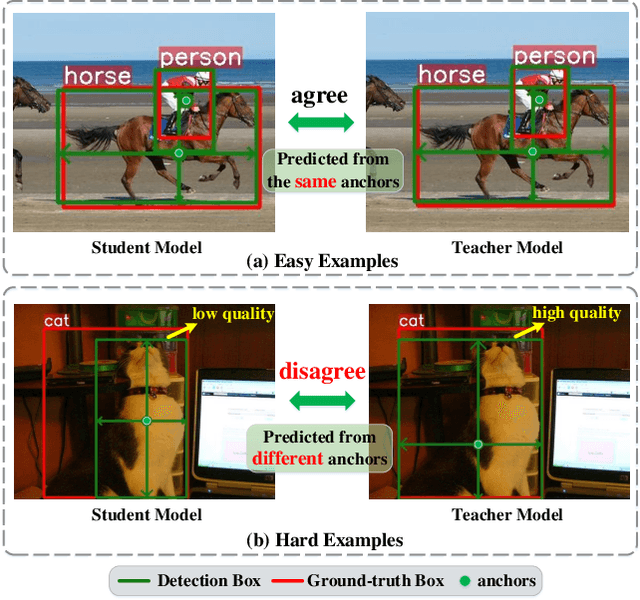
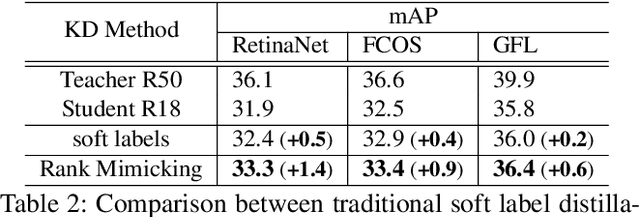
Knowledge Distillation (KD) is a widely-used technology to inherit information from cumbersome teacher models to compact student models, consequently realizing model compression and acceleration. Compared with image classification, object detection is a more complex task, and designing specific KD methods for object detection is non-trivial. In this work, we elaborately study the behaviour difference between the teacher and student detection models, and obtain two intriguing observations: First, the teacher and student rank their detected candidate boxes quite differently, which results in their precision discrepancy. Second, there is a considerable gap between the feature response differences and prediction differences between teacher and student, indicating that equally imitating all the feature maps of the teacher is the sub-optimal choice for improving the student's accuracy. Based on the two observations, we propose Rank Mimicking (RM) and Prediction-guided Feature Imitation (PFI) for distilling one-stage detectors, respectively. RM takes the rank of candidate boxes from teachers as a new form of knowledge to distill, which consistently outperforms the traditional soft label distillation. PFI attempts to correlate feature differences with prediction differences, making feature imitation directly help to improve the student's accuracy. On MS COCO and PASCAL VOC benchmarks, extensive experiments are conducted on various detectors with different backbones to validate the effectiveness of our method. Specifically, RetinaNet with ResNet50 achieves 40.4% mAP in MS COCO, which is 3.5% higher than its baseline, and also outperforms previous KD methods.
One to Transfer All: A Universal Transfer Framework for Vision Foundation Model with Few Data
Nov 24, 2021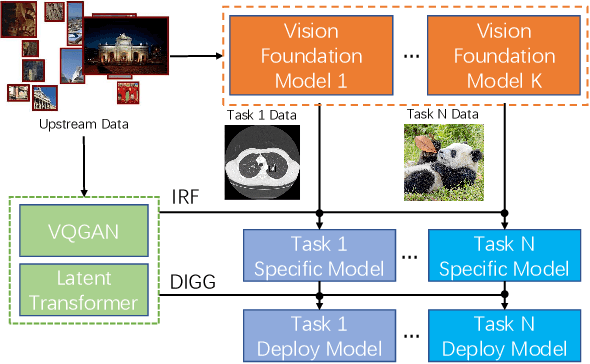
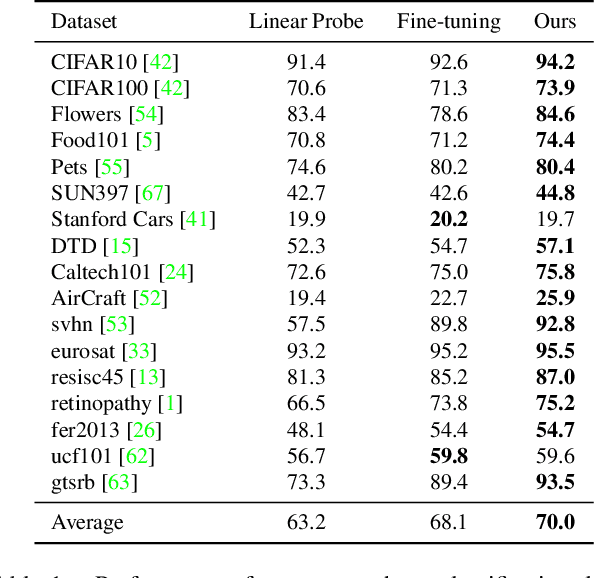

The foundation model is not the last chapter of the model production pipeline. Transferring with few data in a general way to thousands of downstream tasks is becoming a trend of the foundation model's application. In this paper, we proposed a universal transfer framework: One to Transfer All (OTA) to transfer any Vision Foundation Model (VFM) to any downstream tasks with few downstream data. We first transfer a VFM to a task-specific model by Image Re-representation Fine-tuning (IRF) then distilling knowledge from a task-specific model to a deployed model with data produced by Downstream Image-Guided Generation (DIGG). OTA has no dependency on upstream data, VFM, and downstream tasks when transferring. It also provides a way for VFM researchers to release their upstream information for better transferring but not leaking data due to privacy requirements. Massive experiments validate the effectiveness and superiority of our methods in few data setting. Our code will be released.
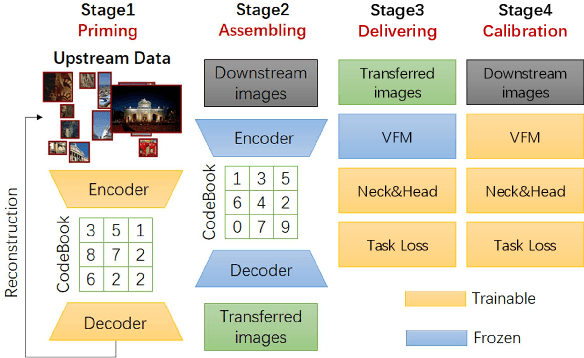
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021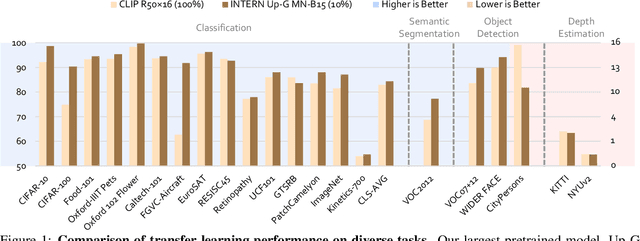
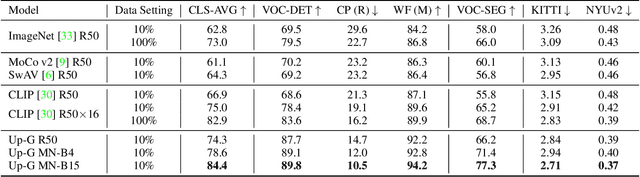
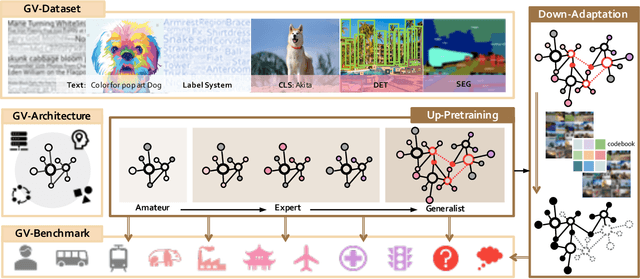
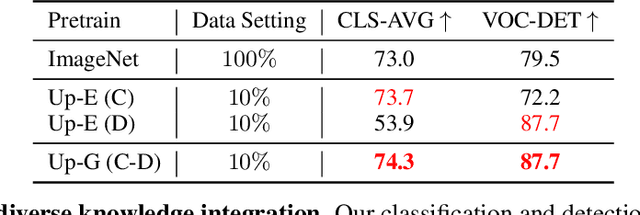
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.
CycleMLP: A MLP-like Architecture for Dense Prediction
Jul 21, 2021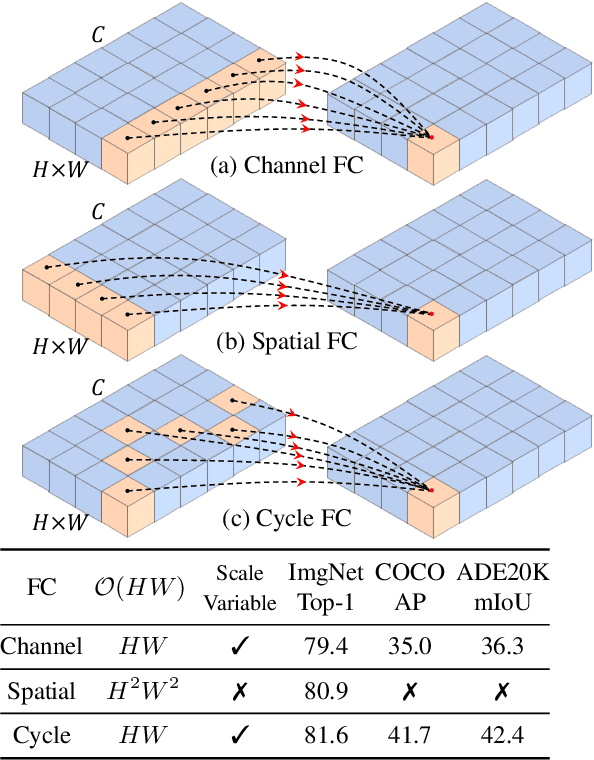
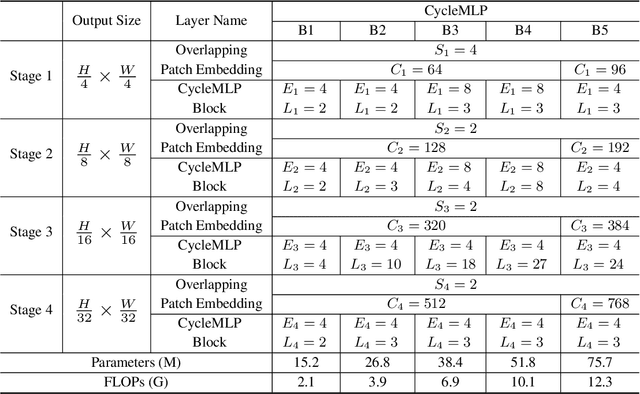
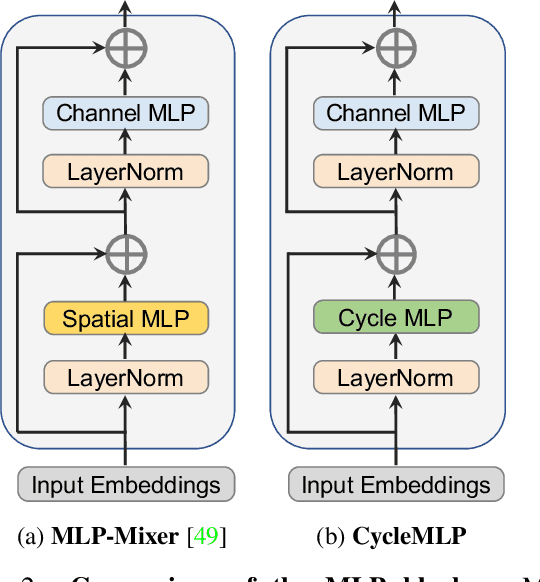
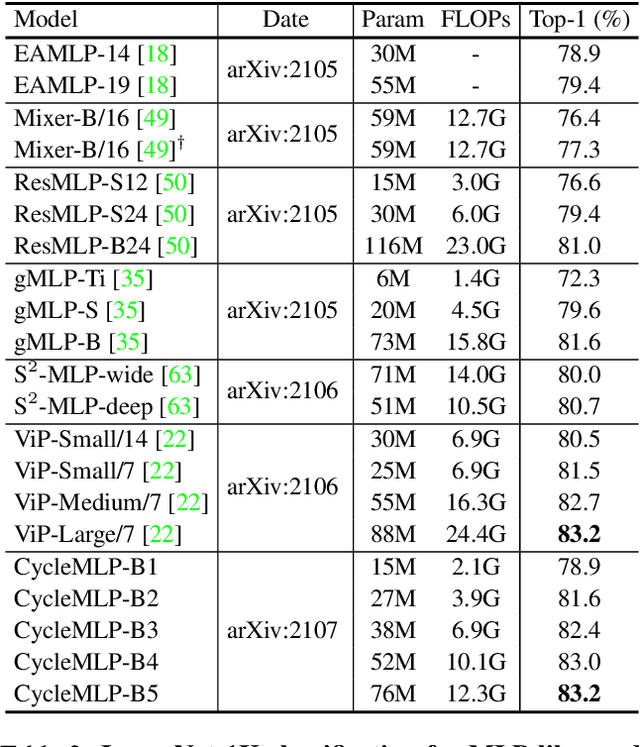
This paper presents a simple MLP-like architecture, CycleMLP, which is a versatile backbone for visual recognition and dense predictions, unlike modern MLP architectures, e.g., MLP-Mixer, ResMLP, and gMLP, whose architectures are correlated to image size and thus are infeasible in object detection and segmentation. CycleMLP has two advantages compared to modern approaches. (1) It can cope with various image sizes. (2) It achieves linear computational complexity to image size by using local windows. In contrast, previous MLPs have quadratic computations because of their fully spatial connections. We build a family of models that surpass existing MLPs and achieve a comparable accuracy (83.2%) on ImageNet-1K classification compared to the state-of-the-art Transformer such as Swin Transformer (83.3%) but using fewer parameters and FLOPs. We expand the MLP-like models' applicability, making them a versatile backbone for dense prediction tasks. CycleMLP aims to provide a competitive baseline on object detection, instance segmentation, and semantic segmentation for MLP models. In particular, CycleMLP achieves 45.1 mIoU on ADE20K val, comparable to Swin (45.2 mIOU). Code is available at \url{https://github.com/ShoufaChen/CycleMLP}.
PVTv2: Improved Baselines with Pyramid Vision Transformer
Jul 17, 2021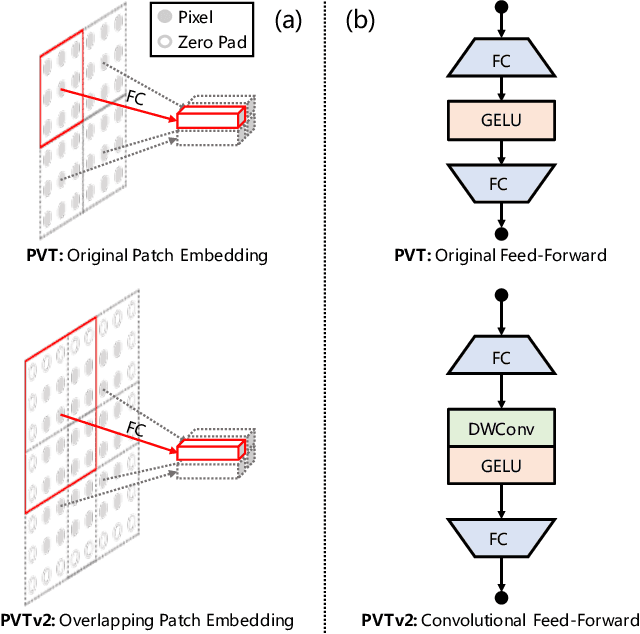
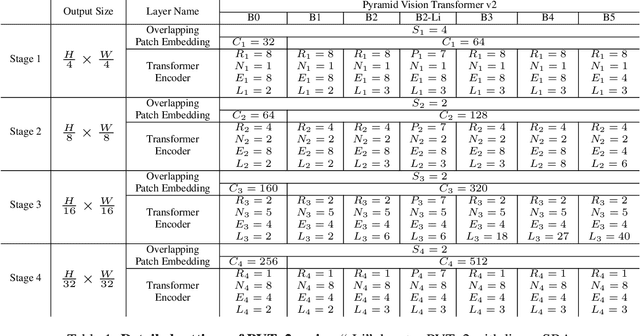
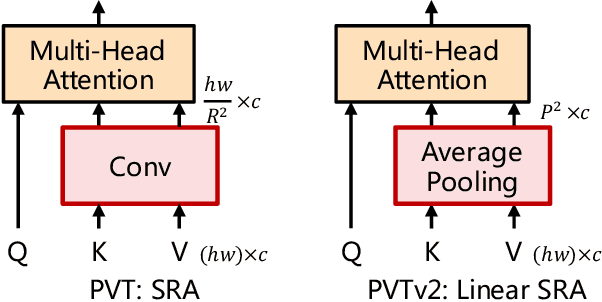
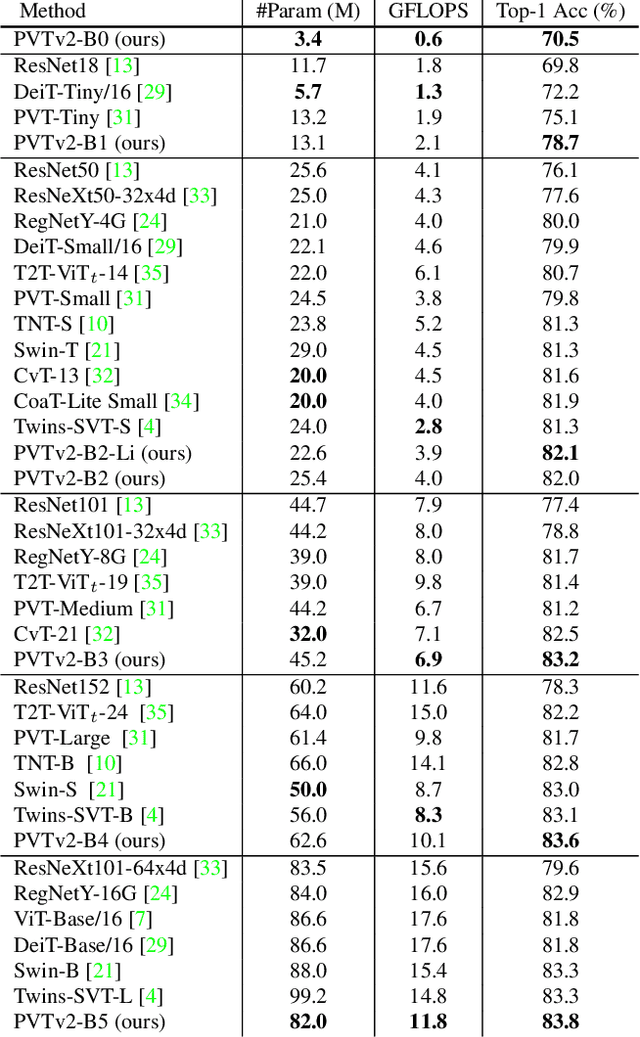
Transformer recently has shown encouraging progresses in computer vision. In this work, we present new baselines by improving the original Pyramid Vision Transformer (abbreviated as PVTv1) by adding three designs, including (1) overlapping patch embedding, (2) convolutional feed-forward networks, and (3) linear complexity attention layers. With these modifications, our PVTv2 significantly improves PVTv1 on three tasks e.g., classification, detection, and segmentation. Moreover, PVTv2 achieves comparable or better performances than recent works such as Swin Transformer. We hope this work will facilitate state-of-the-art Transformer researches in computer vision. Code is available at https://github.com/whai362/PVT .
GroupLink: An End-to-end Multitask Method for Word Grouping and Relation Extraction in Form Understanding
May 10, 2021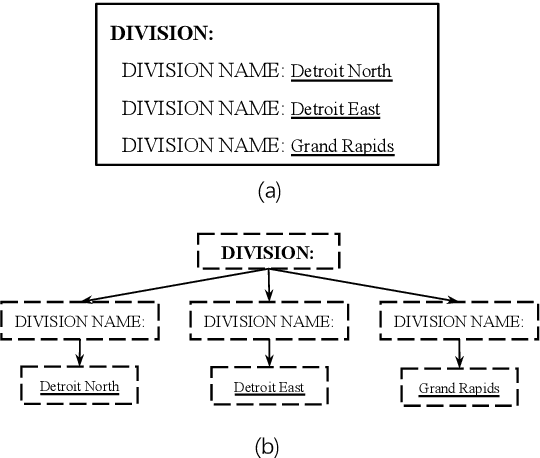
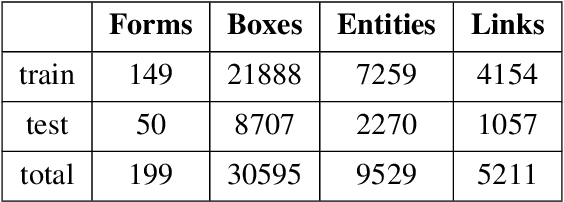
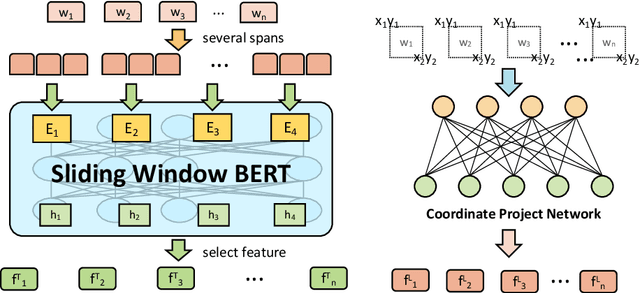
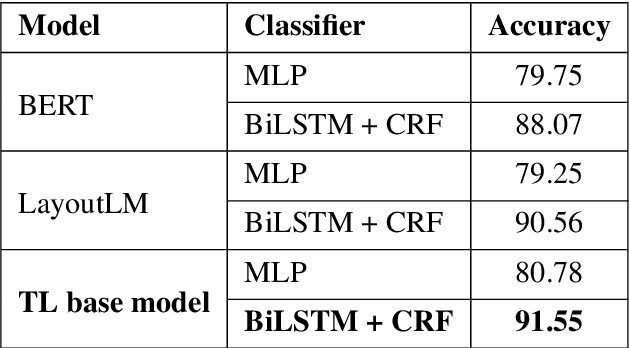
Forms are a common type of document in real life and carry rich information through textual contents and the organizational structure. To realize automatic processing of forms, word grouping and relation extraction are two fundamental and crucial steps after preliminary processing of optical character reader (OCR). Word grouping is to aggregate words that belong to the same semantic entity, and relation extraction is to predict the links between semantic entities. Existing works treat them as two individual tasks, but these two tasks are correlated and can reinforce each other. The grouping process will refine the integrated representation of the corresponding entity, and the linking process will give feedback to the grouping performance. For this purpose, we acquire multimodal features from both textual data and layout information and build an end-to-end model through multitask training to combine word grouping and relation extraction to enhance performance on each task. We validate our proposed method on a real-world, fully-annotated, noisy-scanned benchmark, FUNSD, and extensive experiments demonstrate the effectiveness of our method.