 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Joint Space Model-Predictive Control for Reactive Manipulation
Apr 28, 2021
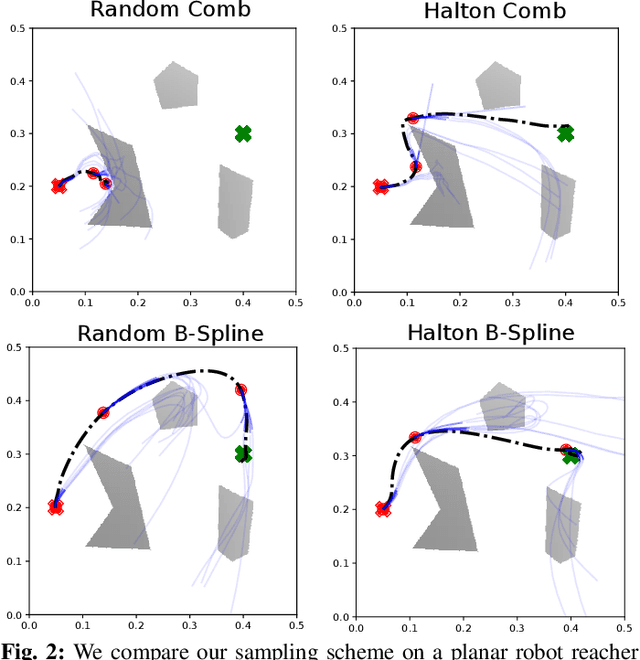
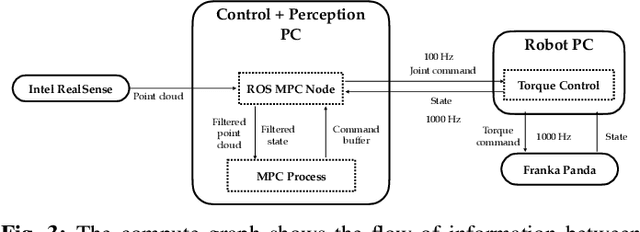
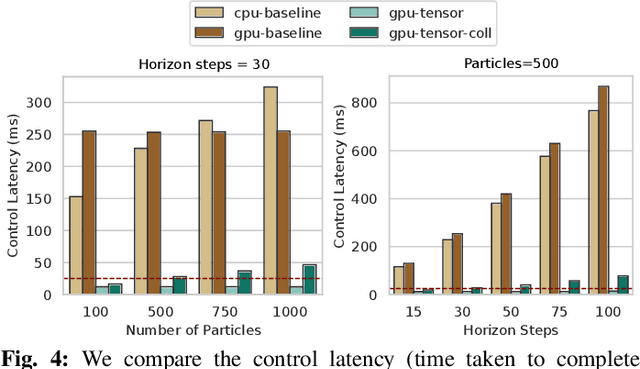
Sampling-based model predictive control (MPC) is a promising tool for feedback control of robots with complex and non-smooth dynamics and cost functions. The computationally demanding nature of sampling-based MPC algorithms is a key bottleneck in their application to high-dimensional robotic manipulation problems. Previous methods have addressed this issue by running MPC in the task space while relying on a low-level operational space controller for joint control. However, by not using the joint space of the robot in the MPC formulation, existing methods cannot directly account for non-task space related constraints such as avoiding joint limits, singular configurations, and link collisions. In this paper, we develop a joint space sampling-based MPC for manipulators that can be efficiently parallelized using GPUs. Our approach can handle task and joint space constraints while taking less than 0.02 seconds (50Hz) to compute the next control command. Further, our method can integrate perception into the control problem by utilizing learned cost functions from raw sensor data. We validate our approach by deploying it on a Franka Panda robot for a variety of common manipulation tasks. We study the effect of different cost formulations and MPC parameters on the synthesized behavior and provide key insights that pave the way for the application of sampling-based MPC for manipulators in a principled manner. Videos of experiments can be found at: https://sites.google.com/view/manipulation-mppi.
DexYCB: A Benchmark for Capturing Hand Grasping of Objects
Apr 09, 2021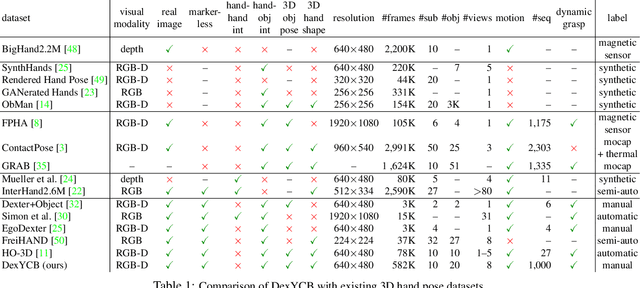

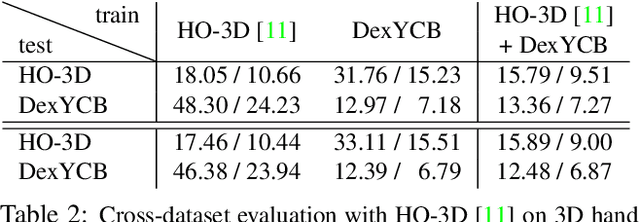

We introduce DexYCB, a new dataset for capturing hand grasping of objects. We first compare DexYCB with a related one through cross-dataset evaluation. We then present a thorough benchmark of state-of-the-art approaches on three relevant tasks: 2D object and keypoint detection, 6D object pose estimation, and 3D hand pose estimation. Finally, we evaluate a new robotics-relevant task: generating safe robot grasps in human-to-robot object handover. Dataset and code are available at https://dex-ycb.github.io.
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Apr 01, 2021
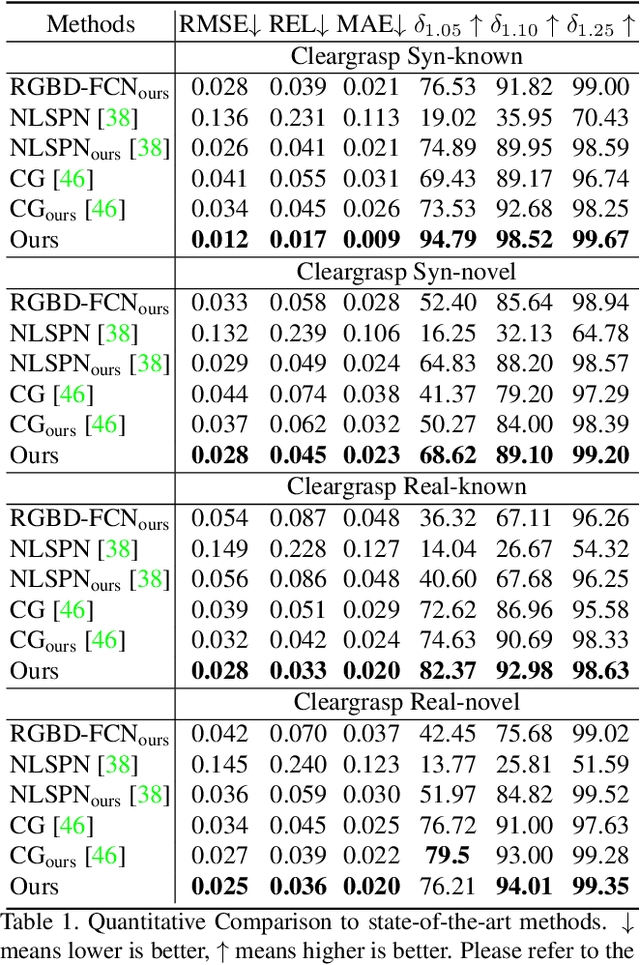


Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this paper, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed. Based on this representation, we present a novel framework that can complete missing depth given noisy RGB-D input. We further improve the depth estimation iteratively using a self-correcting refinement model. To train the whole pipeline, we build a large scale synthetic dataset with transparent objects. Experiments demonstrate that our method performs significantly better than the current state-of-the-art methods on both synthetic and real world data. In addition, our approach improves the inference speed by a factor of 20 compared to the previous best method, ClearGrasp. Code and dataset will be released at https://research.nvidia.com/publication/2021-03_RGB-D-Local-Implicit.
Sim-to-Real for Robotic Tactile Sensing via Physics-Based Simulation and Learned Latent Projections
Mar 31, 2021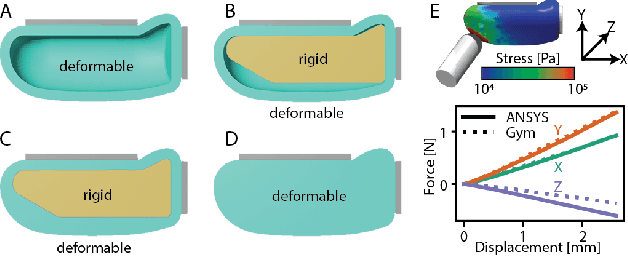
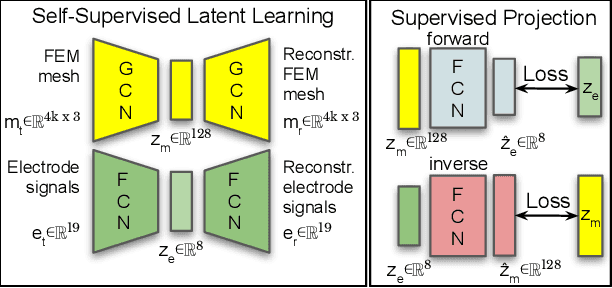

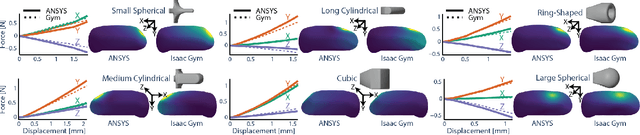
Tactile sensing is critical for robotic grasping and manipulation of objects under visual occlusion. However, in contrast to simulations of robot arms and cameras, current simulations of tactile sensors have limited accuracy, speed, and utility. In this work, we develop an efficient 3D finite element method (FEM) model of the SynTouch BioTac sensor using an open-access, GPU-based robotics simulator. Our simulations closely reproduce results from an experimentally-validated model in an industry-standard, CPU-based simulator, but at 75x the speed. We then learn latent representations for simulated BioTac deformations and real-world electrical output through self-supervision, as well as projections between the latent spaces using a small supervised dataset. Using these learned latent projections, we accurately synthesize real-world BioTac electrical output and estimate contact patches, both for unseen contact interactions. This work contributes an efficient, freely-accessible FEM model of the BioTac and comprises one of the first efforts to combine self-supervision, cross-modal transfer, and sim-to-real transfer for tactile sensors.
Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes
Mar 25, 2021
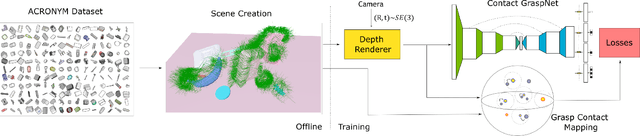
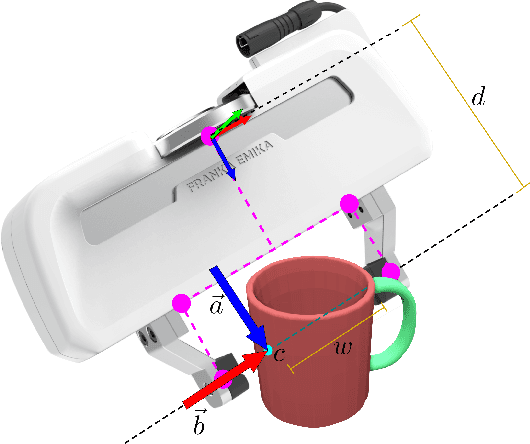
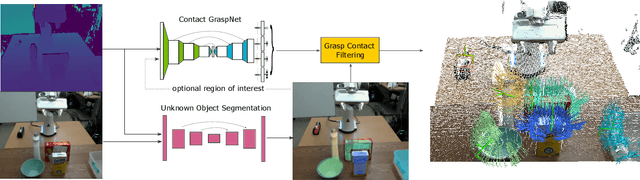
Grasping unseen objects in unconstrained, cluttered environments is an essential skill for autonomous robotic manipulation. Despite recent progress in full 6-DoF grasp learning, existing approaches often consist of complex sequential pipelines that possess several potential failure points and run-times unsuitable for closed-loop grasping. Therefore, we propose an end-to-end network that efficiently generates a distribution of 6-DoF parallel-jaw grasps directly from a depth recording of a scene. Our novel grasp representation treats 3D points of the recorded point cloud as potential grasp contacts. By rooting the full 6-DoF grasp pose and width in the observed point cloud, we can reduce the dimensionality of our grasp representation to 4-DoF which greatly facilitates the learning process. Our class-agnostic approach is trained on 17 million simulated grasps and generalizes well to real world sensor data. In a robotic grasping study of unseen objects in structured clutter we achieve over 90% success rate, cutting the failure rate in half compared to a recent state-of-the-art method.
Learning Composable Behavior Embeddings for Long-horizon Visual Navigation
Feb 19, 2021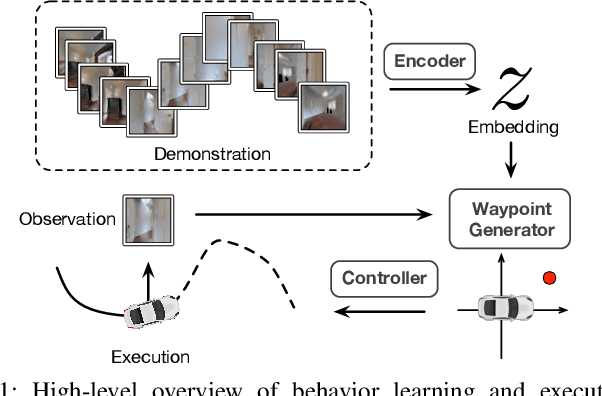
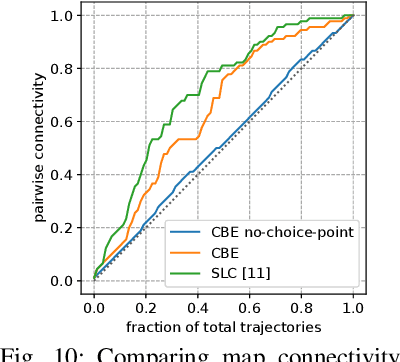
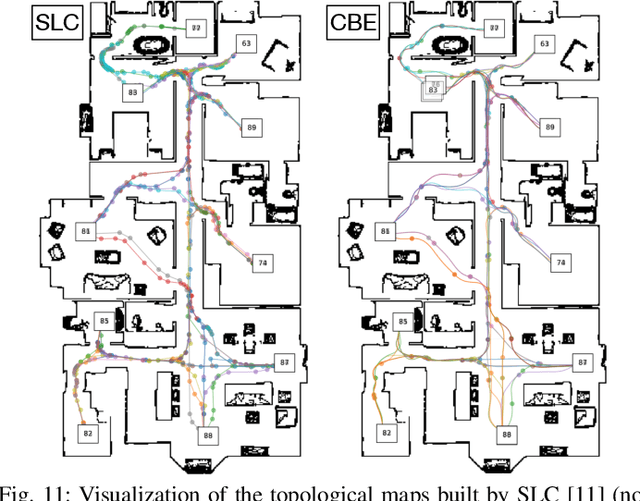
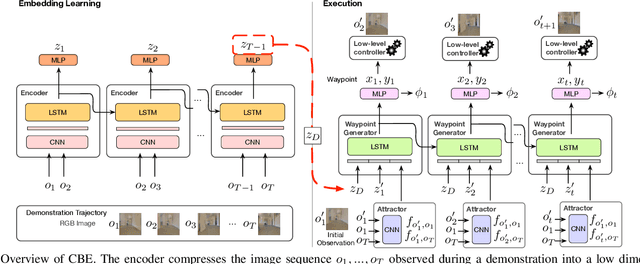
Learning high-level navigation behaviors has important implications: it enables robots to build compact visual memory for repeating demonstrations and to build sparse topological maps for planning in novel environments. Existing approaches only learn discrete, short-horizon behaviors. These standalone behaviors usually assume a discrete action space with simple robot dynamics, thus they cannot capture the intricacy and complexity of real-world trajectories. To this end, we propose Composable Behavior Embedding (CBE), a continuous behavior representation for long-horizon visual navigation. CBE is learned in an end-to-end fashion; it effectively captures path geometry and is robust to unseen obstacles. We show that CBE can be used to performing memory-efficient path following and topological mapping, saving more than an order of magnitude of memory than behavior-less approaches.
Interpreting and Predicting Tactile Signals for the SynTouch BioTac
Jan 14, 2021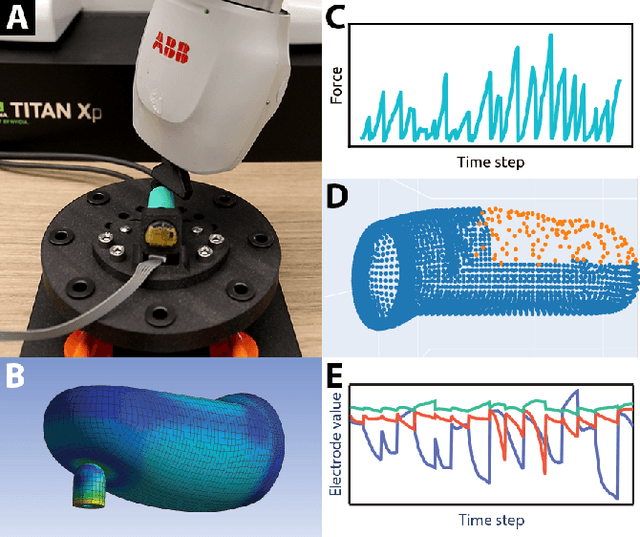
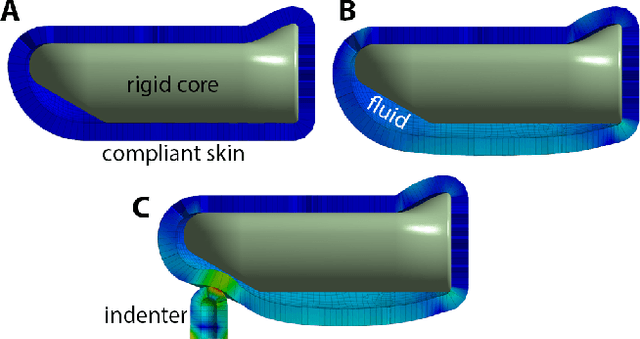

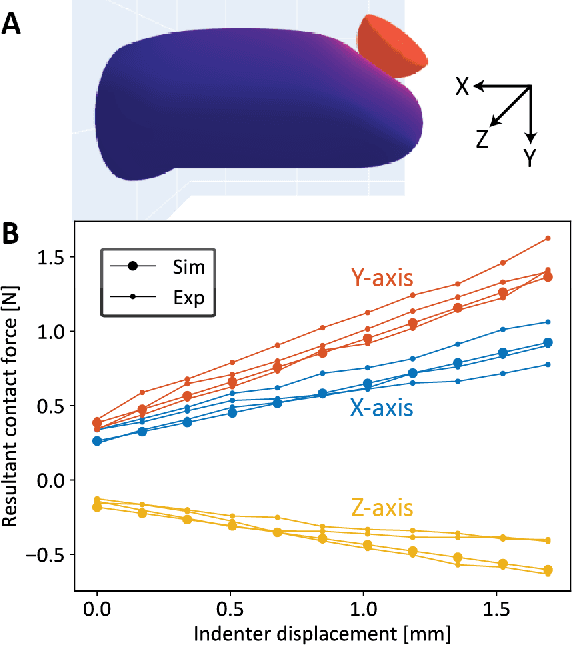
In the human hand, high-density contact information provided by afferent neurons is essential for many human grasping and manipulation capabilities. In contrast, robotic tactile sensors, including the state-of-the-art SynTouch BioTac, are typically used to provide low-density contact information, such as contact location, center of pressure, and net force. Although useful, these data do not convey or leverage the rich information content that some tactile sensors naturally measure. This research extends robotic tactile sensing beyond reduced-order models through 1) the automated creation of a precise experimental tactile dataset for the BioTac over a diverse range of physical interactions, 2) a 3D finite element (FE) model of the BioTac, which complements the experimental dataset with high-density, distributed contact data, 3) neural-network-based mappings from raw BioTac signals to not only low-dimensional experimental data, but also high-density FE deformation fields, and 4) mappings from the FE deformation fields to the raw signals themselves. The high-density data streams can provide a far greater quantity of interpretable information for grasping and manipulation algorithms than previously accessible.
Alternative Paths Planner (APP) for Provably Fixed-time Manipulation Planning in Semi-structured Environments
Dec 29, 2020
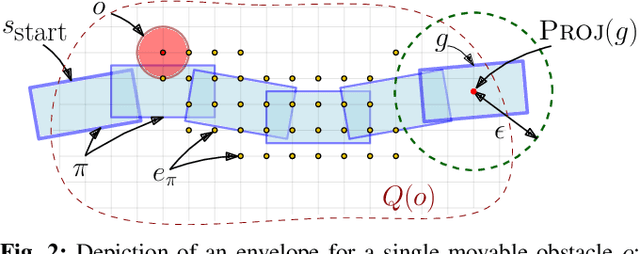
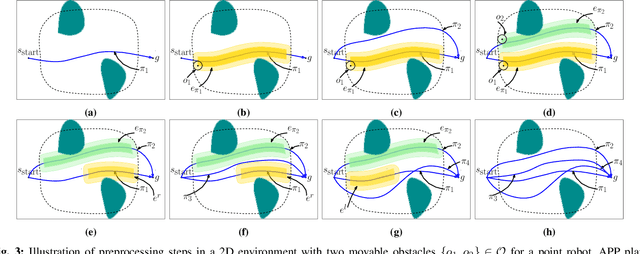
In many applications, including logistics and manufacturing, robot manipulators operate in semi-structured environments alongside humans or other robots. These environments are largely static, but they may contain some movable obstacles that the robot must avoid. Manipulation tasks in these applications are often highly repetitive, but require fast and reliable motion planning capabilities, often under strict time constraints. Existing preprocessing-based approaches are beneficial when the environments are highly-structured, but their performance degrades in the presence of movable obstacles, since these are not modelled a priori. We propose a novel preprocessing-based method called Alternative Paths Planner (APP) that provides provably fixed-time planning guarantees in semi-structured environments. APP plans a set of alternative paths offline such that, for any configuration of the movable obstacles, at least one of the paths from this set is collision-free. During online execution, a collision-free path can be looked up efficiently within a few microseconds. We evaluate APP on a 7 DoF robot arm in semi-structured domains of varying complexity and demonstrate that APP is several orders of magnitude faster than state-of-the-art motion planners for each domain. We further validate this approach with real-time experiments on a robotic manipulator.
Towards Coordinated Robot Motions: End-to-End Learning of Motion Policies on Transform Trees
Dec 24, 2020
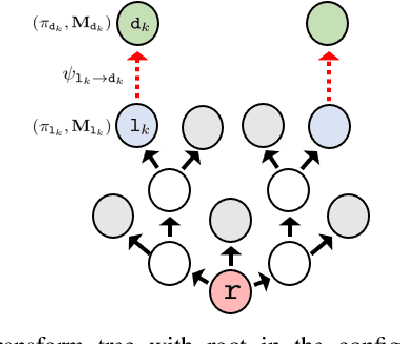
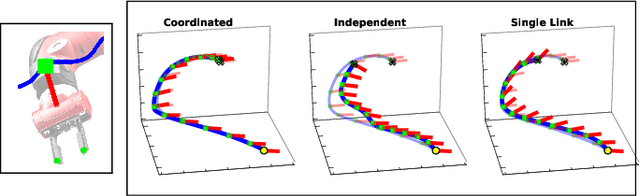
Robotic tasks often require generation of motions that satisfy multiple motion constraints, that may live on different parts of a robot's body. In this paper, we address the challenge of learning motion policies to generate motions for execution of such tasks. Additionally, to encode multiple motion constraints and their synergies, we enforce structure in our motion policy. Specifically, the structure results from decomposing a motion policy into multiple subtask policies, whereby each subtask policy dictates a particular subtask behavior. By learning the subtask policies together in an end-to-end fashion, our formulation not only learns coordination between subtask behaviors, but also learns how to trade them off against default behaviors that may exist. Furthermore, due to our choice of parameterization for the constituting subtask policies, our overall structured motion policy is guaranteed to generate stable motions. To corroborate our theory, we also present qualitative and quantitative evaluations on multiple robotic tasks.
Stein Variational Model Predictive Control
Dec 09, 2020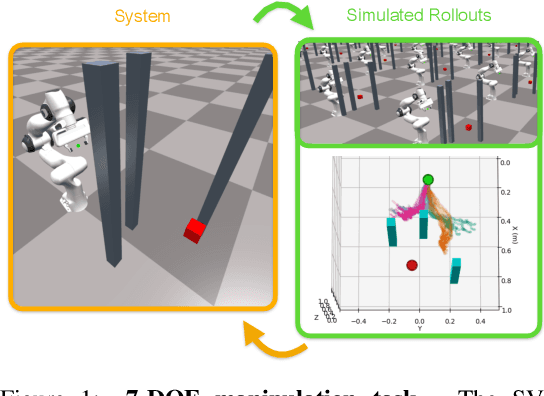

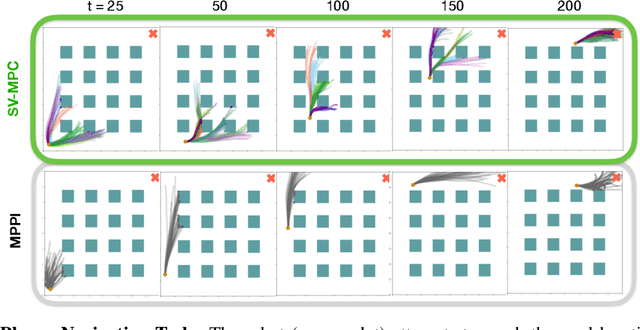
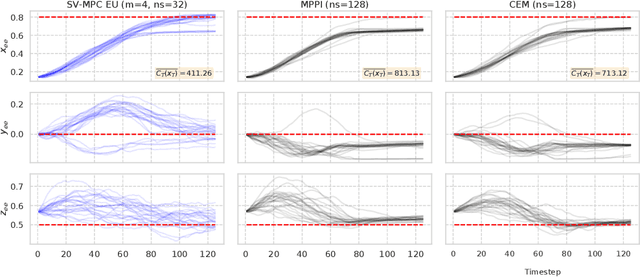
Decision making under uncertainty is critical to real-world, autonomous systems. Model Predictive Control (MPC) methods have demonstrated favorable performance in practice, but remain limited when dealing with complex probability distributions. In this paper, we propose a generalization of MPC that represents a multitude of solutions as posterior distributions. By casting MPC as a Bayesian inference problem, we employ variational methods for posterior computation, naturally encoding the complexity and multi-modality of the decision making problem. We propose a Stein variational gradient descent method to estimate the posterior directly over control parameters, given a cost function and observed state trajectories. We show that this framework leads to successful planning in challenging, non-convex optimal control problems.