 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRearrangement: A Challenge for Embodied AI
Nov 03, 2020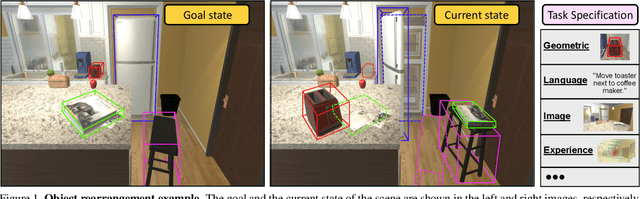
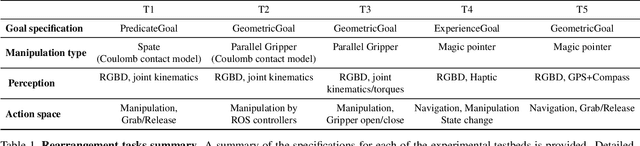


We describe a framework for research and evaluation in Embodied AI. Our proposal is based on a canonical task: Rearrangement. A standard task can focus the development of new techniques and serve as a source of trained models that can be transferred to other settings. In the rearrangement task, the goal is to bring a given physical environment into a specified state. The goal state can be specified by object poses, by images, by a description in language, or by letting the agent experience the environment in the goal state. We characterize rearrangement scenarios along different axes and describe metrics for benchmarking rearrangement performance. To facilitate research and exploration, we present experimental testbeds of rearrangement scenarios in four different simulation environments. We anticipate that other datasets will be released and new simulation platforms will be built to support training of rearrangement agents and their deployment on physical systems.
SOrT-ing VQA Models : Contrastive Gradient Learning for Improved Consistency
Oct 20, 2020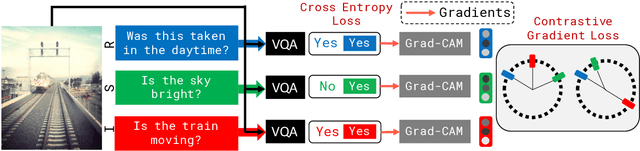



Recent research in Visual Question Answering (VQA) has revealed state-of-the-art models to be inconsistent in their understanding of the world -- they answer seemingly difficult questions requiring reasoning correctly but get simpler associated sub-questions wrong. These sub-questions pertain to lower level visual concepts in the image that models ideally should understand to be able to answer the higher level question correctly. To address this, we first present a gradient-based interpretability approach to determine the questions most strongly correlated with the reasoning question on an image, and use this to evaluate VQA models on their ability to identify the relevant sub-questions needed to answer a reasoning question. Next, we propose a contrastive gradient learning based approach called Sub-question Oriented Tuning (SOrT) which encourages models to rank relevant sub-questions higher than irrelevant questions for an <$image, reasoning-question$> pair. We show that SOrT improves model consistency by upto 6.5% points over existing baselines, while also improving visual grounding.
Contrast and Classify: Alternate Training for Robust VQA
Oct 13, 2020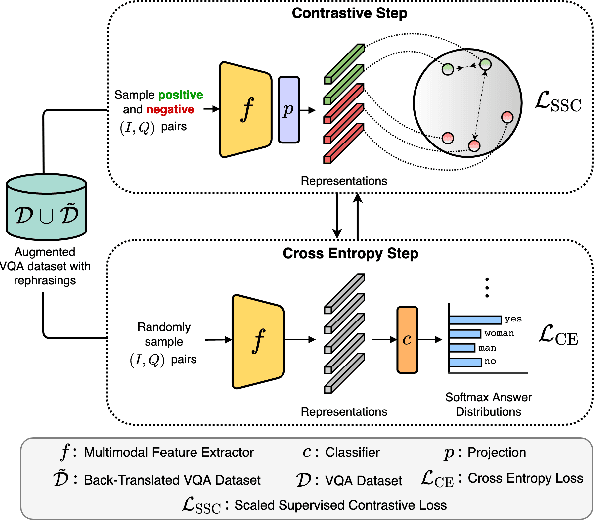
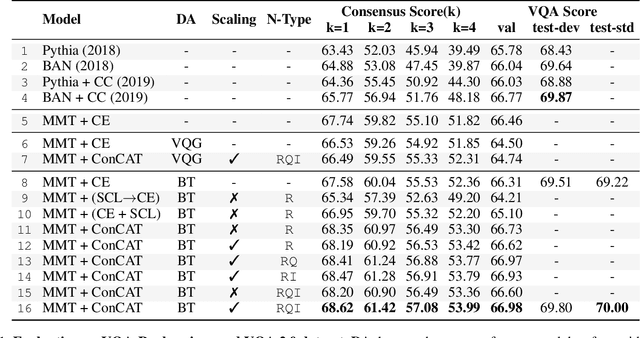
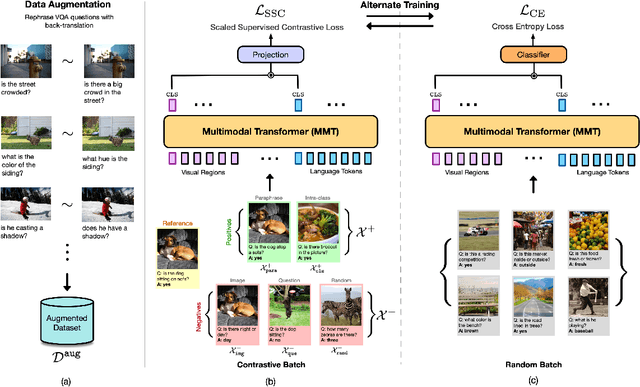
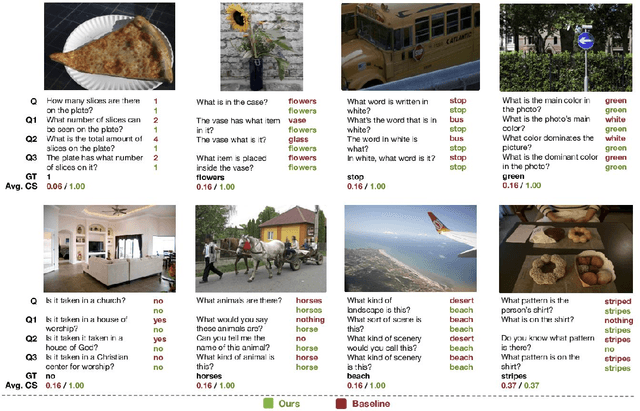
Recent Visual Question Answering (VQA) models have shown impressive performance on the VQA benchmark but remain sensitive to small linguistic variations in input questions. Existing approaches address this by augmenting the dataset with question paraphrases from visual question generation models or adversarial perturbations. These approaches use the combined data to learn an answer classifier by minimizing the standard cross-entropy loss. To more effectively leverage the augmented data, we build on the recent success in contrastive learning. We propose a novel training paradigm (ConCAT) that alternately optimizes cross-entropy and contrastive losses. The contrastive loss encourages representations to be robust to linguistic variations in questions while the cross-entropy loss preserves the discriminative power of the representations for answer classification. We find that alternately optimizing both losses is key to effective training. VQA models trained with ConCAT achieve higher consensus scores on the VQA-Rephrasings dataset as well as higher VQA accuracy on the VQA 2.0 dataset compared to existing approaches across a variety of data augmentation strategies.
Semantic MapNet: Building Allocentric SemanticMaps and Representations from Egocentric Views
Oct 02, 2020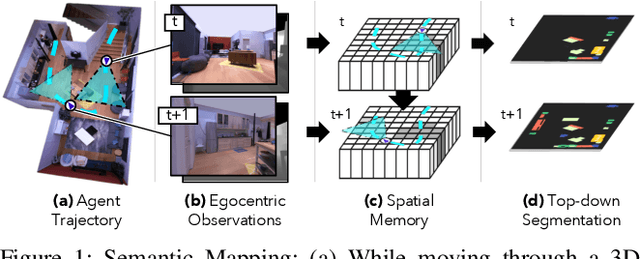

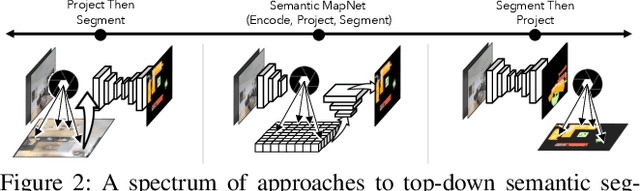

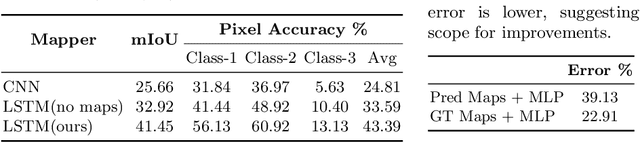
We study the task of semantic mapping - specifically, an embodied agent (a robot or an egocentric AI assistant) is given a tour of a new environment and asked to build an allocentric top-down semantic map ("what is where?") from egocentric observations of an RGB-D camera with known pose (via localization sensors). Towards this goal, we present SemanticMapNet (SMNet), which consists of: (1) an Egocentric Visual Encoder that encodes each egocentric RGB-D frame, (2) a Feature Projector that projects egocentric features to appropriate locations on a floor-plan, (3) a Spatial Memory Tensor of size floor-plan length x width x feature-dims that learns to accumulate projected egocentric features, and (4) a Map Decoder that uses the memory tensor to produce semantic top-down maps. SMNet combines the strengths of (known) projective camera geometry and neural representation learning. On the task of semantic mapping in the Matterport3D dataset, SMNet significantly outperforms competitive baselines by 4.01-16.81% (absolute) on mean-IoU and 3.81-19.69% (absolute) on Boundary-F1 metrics. Moreover, we show how to use the neural episodic memories and spatio-semantic allocentric representations build by SMNet for subsequent tasks in the same space - navigating to objects seen during the tour("Find chair") or answering questions about the space ("How many chairs did you see in the house?").
Integrating Egocentric Localization for More Realistic Point-Goal Navigation Agents
Sep 07, 2020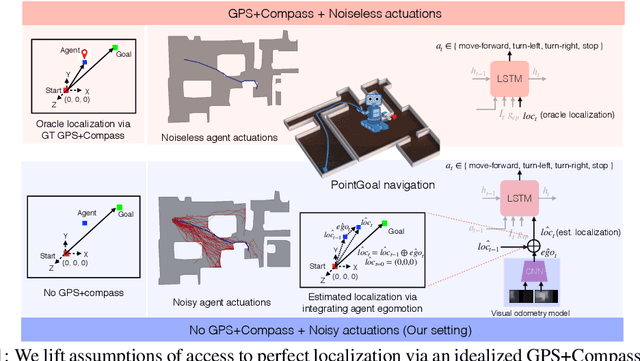
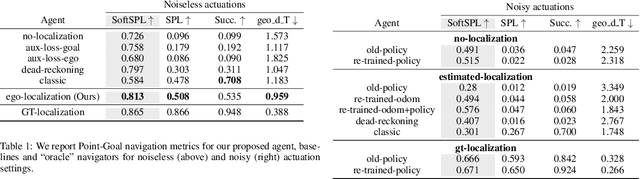
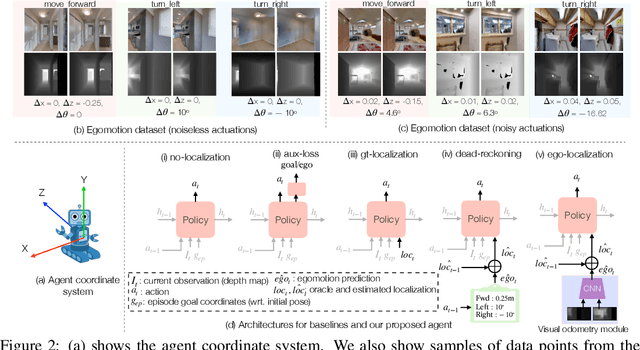
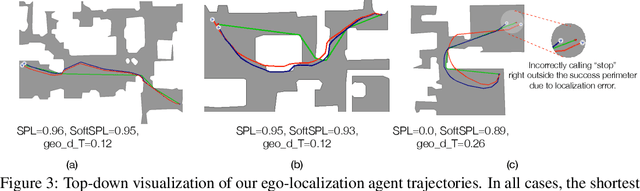
Recent work has presented embodied agents that can navigate to point-goal targets in novel indoor environments with near-perfect accuracy. However, these agents are equipped with idealized sensors for localization and take deterministic actions. This setting is practically sterile by comparison to the dirty reality of noisy sensors and actuations in the real world -- wheels can slip, motion sensors have error, actuations can rebound. In this work, we take a step towards this noisy reality, developing point-goal navigation agents that rely on visual estimates of egomotion under noisy action dynamics. We find these agents outperform naive adaptions of current point-goal agents to this setting as well as those incorporating classic localization baselines. Further, our model conceptually divides learning agent dynamics or odometry (where am I?) from task-specific navigation policy (where do I want to go?). This enables a seamless adaption to changing dynamics (a different robot or floor type) by simply re-calibrating the visual odometry model -- circumventing the expense of re-training of the navigation policy. Our agent was the runner-up in the PointNav track of CVPR 2020 Habitat Challenge.
Dialog without Dialog Data: Learning Visual Dialog Agents from VQA Data
Jul 24, 2020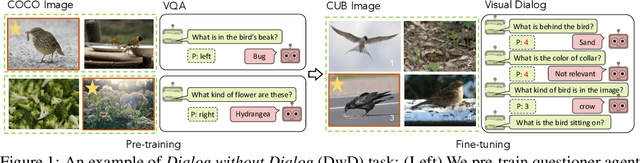
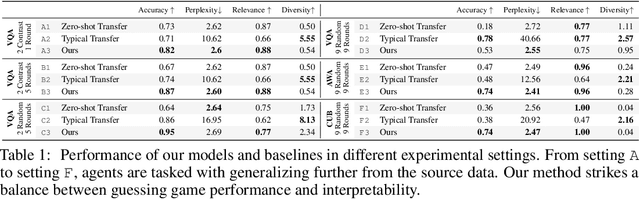
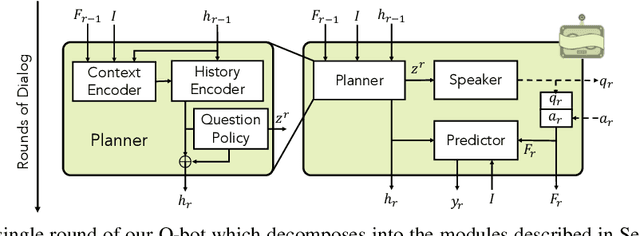
Can we develop visually grounded dialog agents that can efficiently adapt to new tasks without forgetting how to talk to people? Such agents could leverage a larger variety of existing data to generalize to new tasks, minimizing expensive data collection and annotation. In this work, we study a setting we call "Dialog without Dialog", which requires agents to develop visually grounded dialog models that can adapt to new tasks without language level supervision. By factorizing intention and language, our model minimizes linguistic drift after fine-tuning for new tasks. We present qualitative results, automated metrics, and human studies that all show our model can adapt to new tasks and maintain language quality. Baselines either fail to perform well at new tasks or experience language drift, becoming unintelligible to humans. Code has been made available at https://github.com/mcogswell/dialog_without_dialog
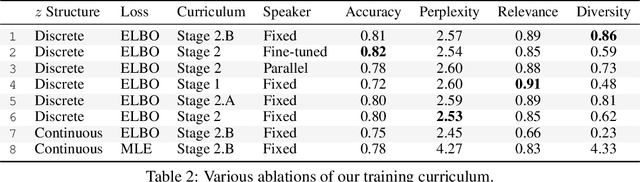
Spatially Aware Multimodal Transformers for TextVQA
Jul 23, 2020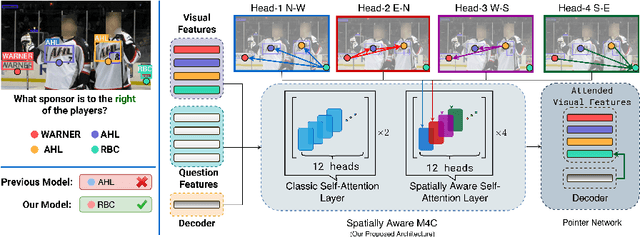
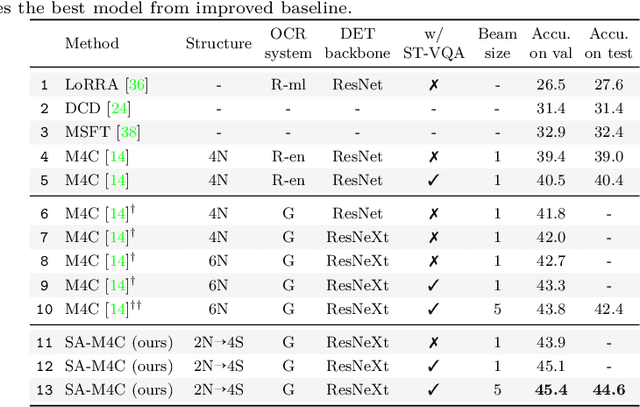
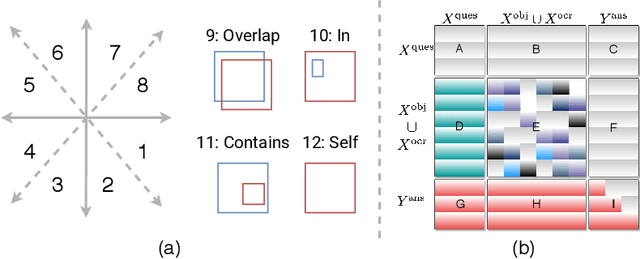
Textual cues are essential for everyday tasks like buying groceries and using public transport. To develop this assistive technology, we study the TextVQA task, i.e., reasoning about text in images to answer a question. Existing approaches are limited in their use of spatial relations and rely on fully-connected transformer-like architectures to implicitly learn the spatial structure of a scene. In contrast, we propose a novel spatially aware self-attention layer such that each visual entity only looks at neighboring entities defined by a spatial graph. Further, each head in our multi-head self-attention layer focuses on a different subset of relations. Our approach has two advantages: (1) each head considers local context instead of dispersing the attention amongst all visual entities; (2) we avoid learning redundant features. We show that our model improves the absolute accuracy of current state-of-the-art methods on TextVQA by 2.2% overall over an improved baseline, and 4.62% on questions that involve spatial reasoning and can be answered correctly using OCR tokens. Similarly on ST-VQA, we improve the absolute accuracy by 4.2%. We further show that spatially aware self-attention improves visual grounding.
Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation
Jul 20, 2020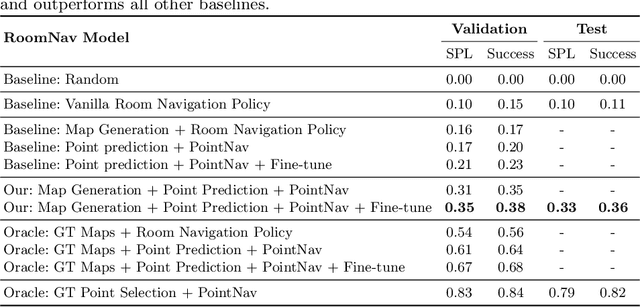
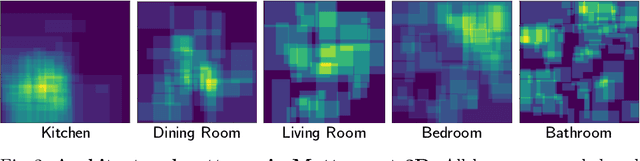
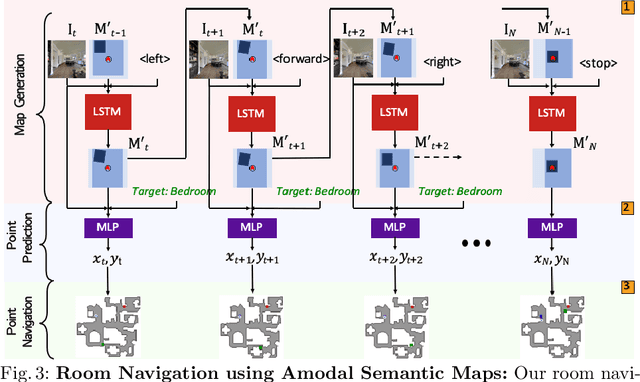
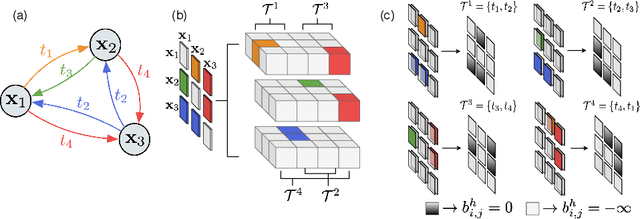
We introduce a learning-based approach for room navigation using semantic maps. Our proposed architecture learns to predict top-down belief maps of regions that lie beyond the agent's field of view while modeling architectural and stylistic regularities in houses. First, we train a model to generate amodal semantic top-down maps indicating beliefs of location, size, and shape of rooms by learning the underlying architectural patterns in houses. Next, we use these maps to predict a point that lies in the target room and train a policy to navigate to the point. We empirically demonstrate that by predicting semantic maps, the model learns common correlations found in houses and generalizes to novel environments. We also demonstrate that reducing the task of room navigation to point navigation improves the performance further.
Auxiliary Tasks Speed Up Learning PointGoal Navigation
Jul 09, 2020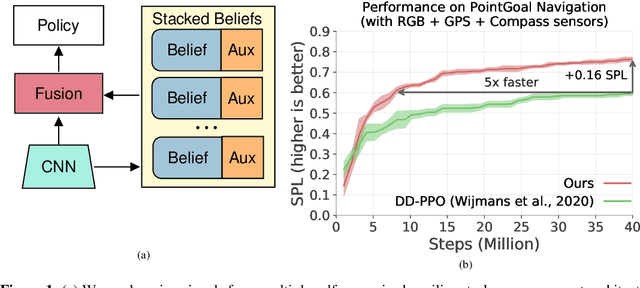

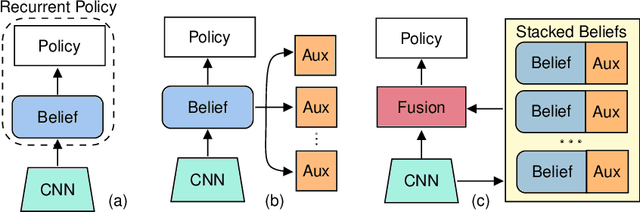
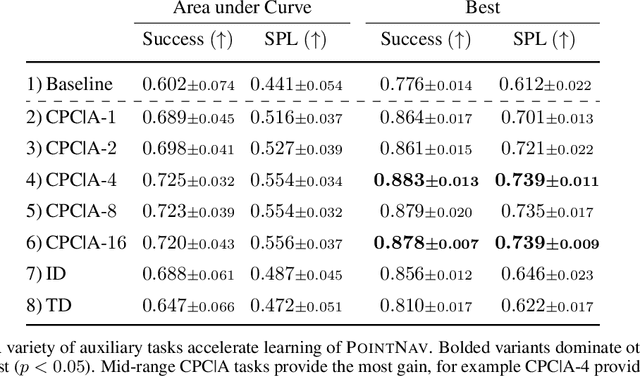
PointGoal Navigation is an embodied task that requires agents to navigate to a specified point in an unseen environment. Wijmans et al. showed that this task is solvable but their method is computationally prohibitive, requiring 2.5 billion frames and 180 GPU-days. In this work, we develop a method to significantly increase sample and time efficiency in learning PointNav using self-supervised auxiliary tasks (e.g. predicting the action taken between two egocentric observations, predicting the distance between two observations from a trajectory,etc.).We find that naively combining multiple auxiliary tasks improves sample efficiency,but only provides marginal gains beyond a point. To overcome this, we use attention to combine representations learnt from individual auxiliary tasks. Our best agent is 5x faster to reach the performance of the previous state-of-the-art, DD-PPO, at 40M frames, and improves on DD-PPO's performance at40M frames by 0.16 SPL. Our code is publicly available at https://github.com/joel99/habitat-pointnav-aux.
ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects
Jun 23, 2020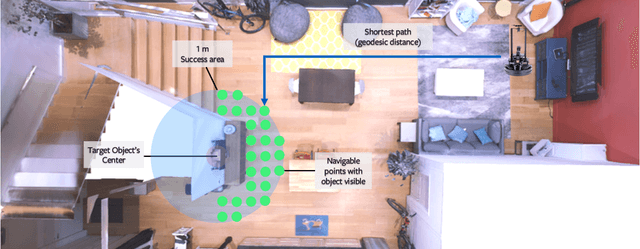

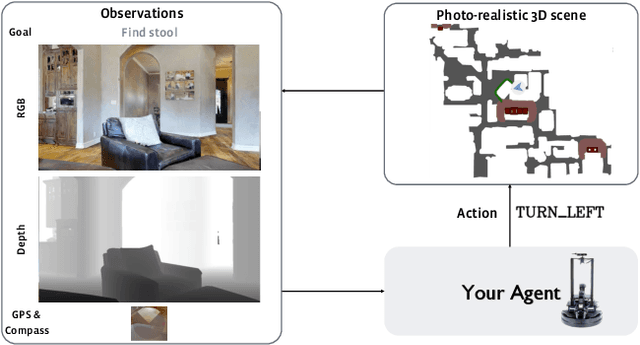
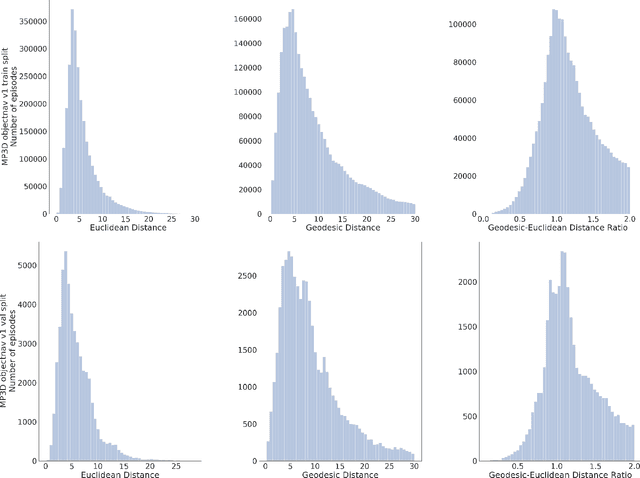
We revisit the problem of Object-Goal Navigation (ObjectNav). In its simplest form, ObjectNav is defined as the task of navigating to an object, specified by its label, in an unexplored environment. In particular, the agent is initialized at a random location and pose in an environment and asked to find an instance of an object category, e.g., find a chair, by navigating to it. As the community begins to show increased interest in semantic goal specification for navigation tasks, a number of different often-inconsistent interpretations of this task are emerging. This document summarizes the consensus recommendations of this working group on ObjectNav. In particular, we make recommendations on subtle but important details of evaluation criteria (for measuring success when navigating towards a target object), the agent's embodiment parameters, and the characteristics of the environments within which the task is carried out. Finally, we provide a detailed description of the instantiation of these recommendations in challenges organized at the Embodied AI workshop at CVPR 2020 \url{http://embodied-ai.org} .