 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto Optimization for Active Learning under Out-of-Distribution Data Scenarios
Jul 04, 2022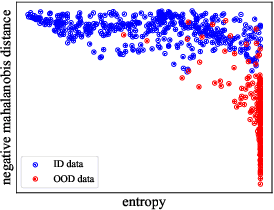
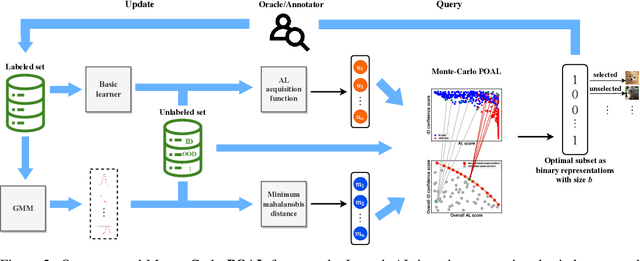
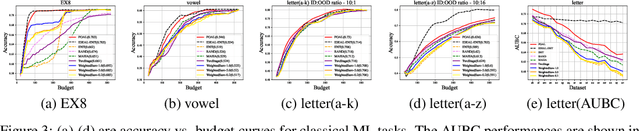
Pool-based Active Learning (AL) has achieved great success in minimizing labeling cost by sequentially selecting informative unlabeled samples from a large unlabeled data pool and querying their labels from oracle/annotators. However, existing AL sampling strategies might not work well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains some data samples that do not belong to the classes of the target task. Achieving good AL performance under OOD data scenarios is a challenging task due to the natural conflict between AL sampling strategies and OOD sample detection. AL selects data that are hard to be classified by the current basic classifier (e.g., samples whose predicted class probabilities have high entropy), while OOD samples tend to have more uniform predicted class probabilities (i.e., high entropy) than in-distribution (ID) data. In this paper, we propose a sampling scheme, Monte-Carlo Pareto Optimization for Active Learning (POAL), which selects optimal subsets of unlabeled samples with fixed batch size from the unlabeled data pool. We cast the AL sampling task as a multi-objective optimization problem, and thus we utilize Pareto optimization based on two conflicting objectives: (1) the normal AL data sampling scheme (e.g., maximum entropy), and (2) the confidence of not being an OOD sample. Experimental results show its effectiveness on both classical Machine Learning (ML) and Deep Learning (DL) tasks.
FedHiSyn: A Hierarchical Synchronous Federated Learning Framework for Resource and Data Heterogeneity
Jun 21, 2022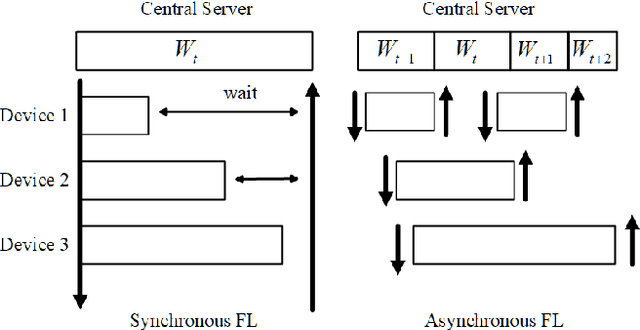
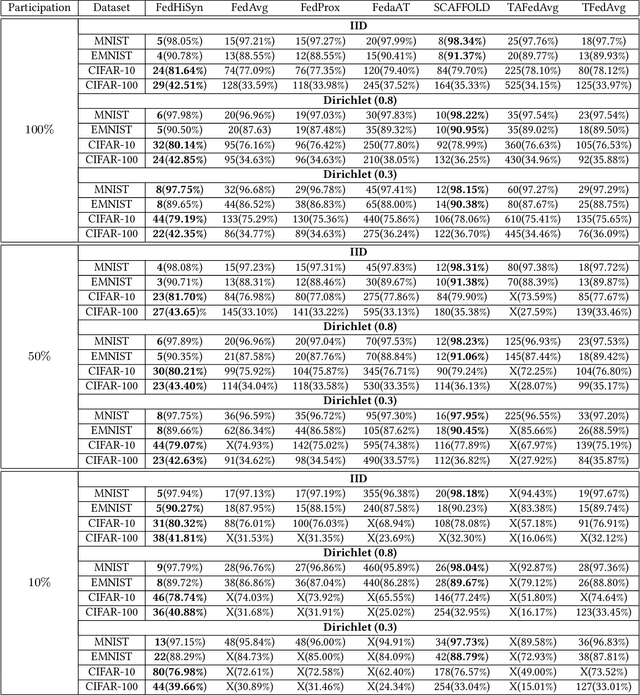
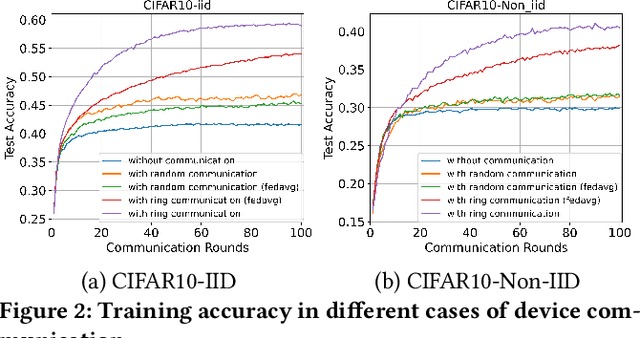
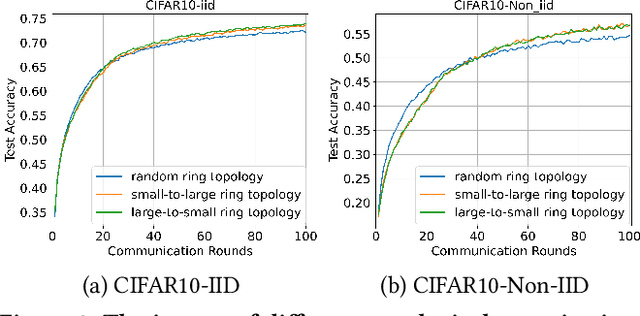
Federated Learning (FL) enables training a global model without sharing the decentralized raw data stored on multiple devices to protect data privacy. Due to the diverse capacity of the devices, FL frameworks struggle to tackle the problems of straggler effects and outdated models. In addition, the data heterogeneity incurs severe accuracy degradation of the global model in the FL training process. To address aforementioned issues, we propose a hierarchical synchronous FL framework, i.e., FedHiSyn. FedHiSyn first clusters all available devices into a small number of categories based on their computing capacity. After a certain interval of local training, the models trained in different categories are simultaneously uploaded to a central server. Within a single category, the devices communicate the local updated model weights to each other based on a ring topology. As the efficiency of training in the ring topology prefers devices with homogeneous resources, the classification based on the computing capacity mitigates the impact of straggler effects. Besides, the combination of the synchronous update of multiple categories and the device communication within a single category help address the data heterogeneity issue while achieving high accuracy. We evaluate the proposed framework based on MNIST, EMNIST, CIFAR10 and CIFAR100 datasets and diverse heterogeneous settings of devices. Experimental results show that FedHiSyn outperforms six baseline methods, e.g., FedAvg, SCAFFOLD, and FedAT, in terms of training accuracy and efficiency.
Fine-tuning Pre-trained Language Models with Noise Stability Regularization
Jun 12, 2022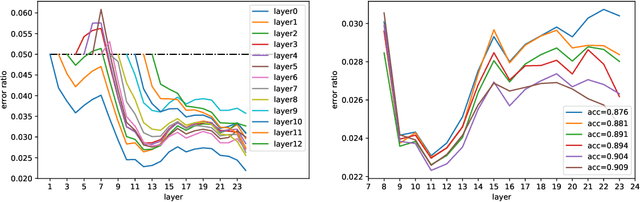
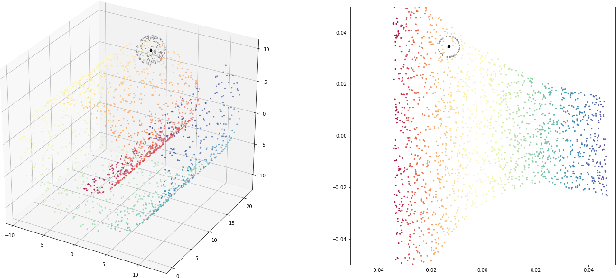
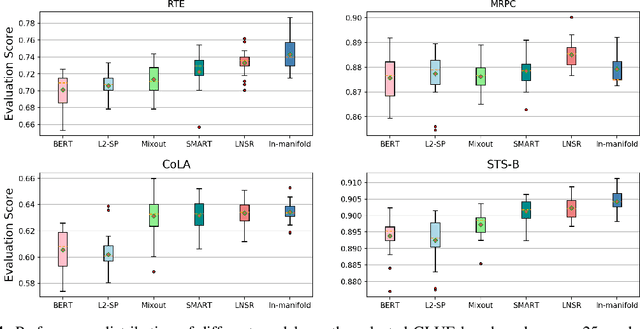
The advent of large-scale pre-trained language models has contributed greatly to the recent progress in natural language processing. Many state-of-the-art language models are first trained on a large text corpus and then fine-tuned on downstream tasks. Despite its recent success and wide adoption, fine-tuning a pre-trained language model often suffers from overfitting, which leads to poor generalizability due to the extremely high complexity of the model and the limited training samples from downstream tasks. To address this problem, we propose a novel and effective fine-tuning framework, named Layerwise Noise Stability Regularization (LNSR). Specifically, we propose to inject the standard Gaussian noise or In-manifold noise and regularize hidden representations of the fine-tuned model. We first provide theoretical analyses to support the efficacy of our method. We then demonstrate the advantages of the proposed method over other state-of-the-art algorithms including L2-SP, Mixout and SMART. While these previous works only verify the effectiveness of their methods on relatively simple text classification tasks, we also verify the effectiveness of our method on question answering tasks, where the target problem is much more difficult and more training examples are available. Furthermore, extensive experimental results indicate that the proposed algorithm can not only enhance the in-domain performance of the language models but also improve the domain generalization performance on out-of-domain data.
A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications
Jun 02, 2022
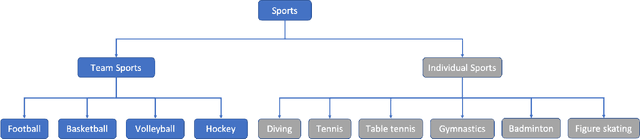
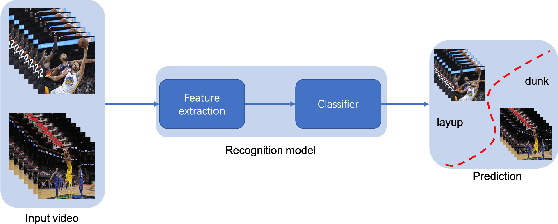
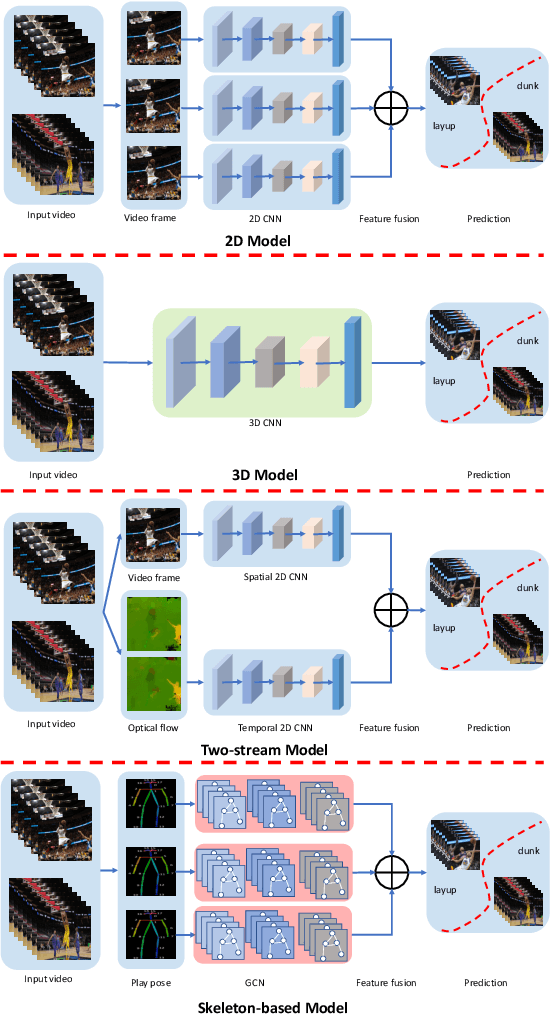
To understand human behaviors, action recognition based on videos is a common approach. Compared with image-based action recognition, videos provide much more information. Reducing the ambiguity of actions and in the last decade, many works focused on datasets, novel models and learning approaches have improved video action recognition to a higher level. However, there are challenges and unsolved problems, in particular in sports analytics where data collection and labeling are more sophisticated, requiring sport professionals to annotate data. In addition, the actions could be extremely fast and it becomes difficult to recognize them. Moreover, in team sports like football and basketball, one action could involve multiple players, and to correctly recognize them, we need to analyse all players, which is relatively complicated. In this paper, we present a survey on video action recognition for sports analytics. We introduce more than ten types of sports, including team sports, such as football, basketball, volleyball, hockey and individual sports, such as figure skating, gymnastics, table tennis, tennis, diving and badminton. Then we compare numerous existing frameworks for sports analysis to present status quo of video action recognition in both team sports and individual sports. Finally, we discuss the challenges and unsolved problems in this area and to facilitate sports analytics, we develop a toolbox using PaddlePaddle, which supports football, basketball, table tennis and figure skating action recognition.
Feature Forgetting in Continual Representation Learning
May 26, 2022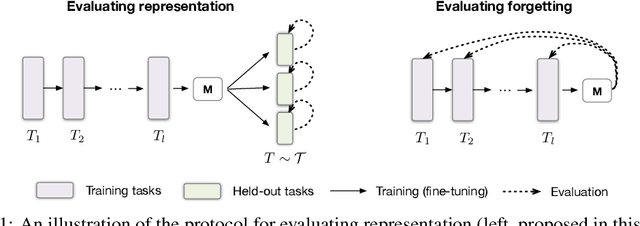

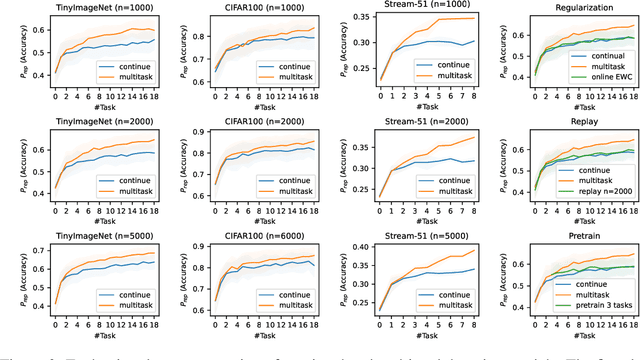
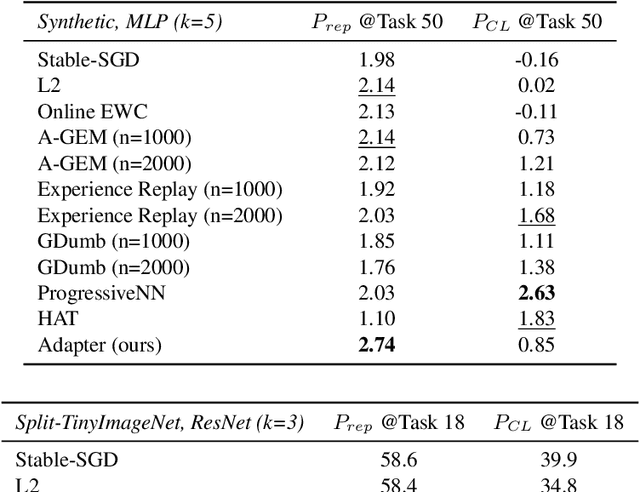
In continual and lifelong learning, good representation learning can help increase performance and reduce sample complexity when learning new tasks. There is evidence that representations do not suffer from "catastrophic forgetting" even in plain continual learning, but little further fact is known about its characteristics. In this paper, we aim to gain more understanding about representation learning in continual learning, especially on the feature forgetting problem. We devise a protocol for evaluating representation in continual learning, and then use it to present an overview of the basic trends of continual representation learning, showing its consistent deficiency and potential issues. To study the feature forgetting problem, we create a synthetic dataset to identify and visualize the prevalence of feature forgetting in neural networks. Finally, we propose a simple technique using gating adapters to mitigate feature forgetting. We conclude by discussing that improving representation learning benefits both old and new tasks in continual learning.
Deep Active Learning with Noise Stability
May 26, 2022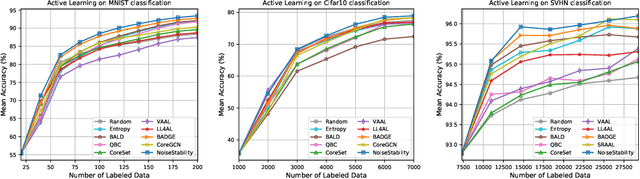
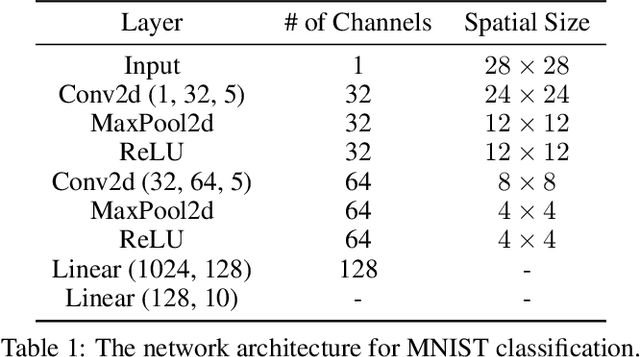
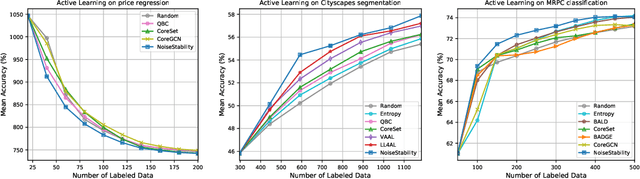
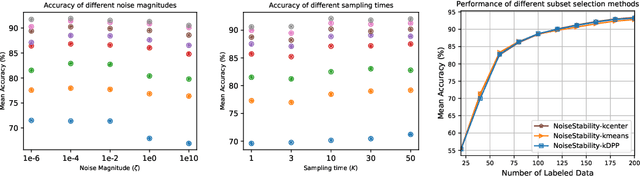
Uncertainty estimation for unlabeled data is crucial to active learning. With a deep neural network employed as the backbone model, the data selection process is highly challenging due to the potential over-confidence of the model inference. Existing methods resort to special learning fashions (e.g. adversarial) or auxiliary models to address this challenge. This tends to result in complex and inefficient pipelines, which would render the methods impractical. In this work, we propose a novel algorithm that leverages noise stability to estimate data uncertainty in a Single-Training Multi-Inference fashion. The key idea is to measure the output derivation from the original observation when the model parameters are randomly perturbed by noise. We provide theoretical analyses by leveraging the small Gaussian noise theory and demonstrate that our method favors a subset with large and diverse gradients. Despite its simplicity, our method outperforms the state-of-the-art active learning baselines in various tasks, including computer vision, natural language processing, and structural data analysis.
Practical Strategies of Active Learning to Rank for Web Search
May 20, 2022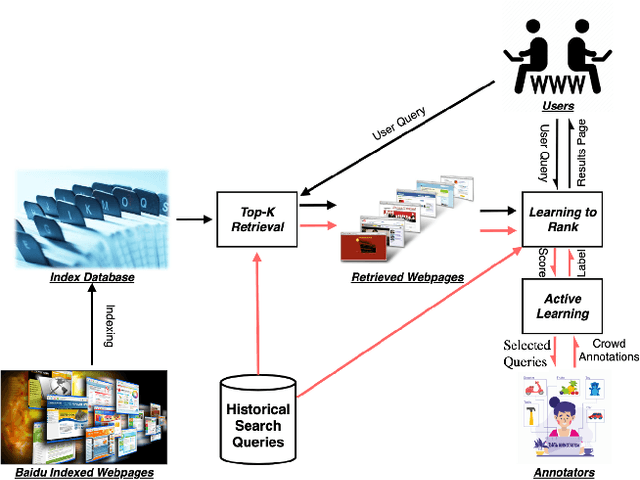
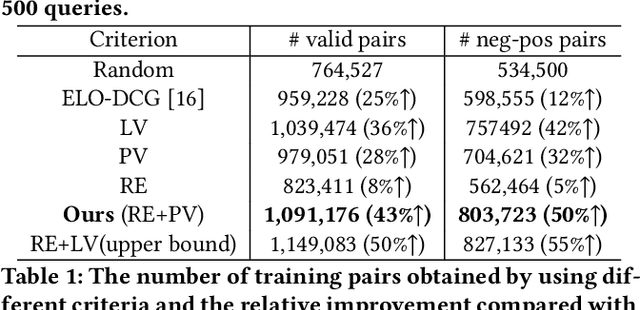
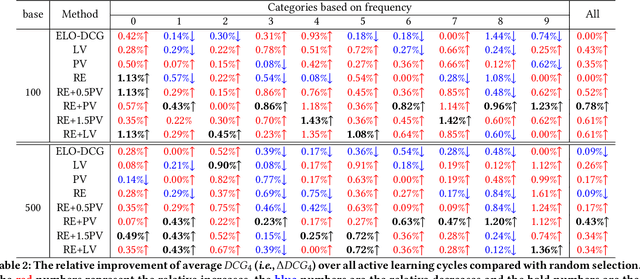
While China has become the biggest online market in the world with around 1 billion internet users, Baidu runs the world largest Chinese search engine serving more than hundreds of millions of daily active users and responding billions queries per day. To handle the diverse query requests from users at web-scale, Baidu has done tremendous efforts in understanding users' queries, retrieve relevant contents from a pool of trillions of webpages, and rank the most relevant webpages on the top of results. Among these components used in Baidu search, learning to rank (LTR) plays a critical role and we need to timely label an extremely large number of queries together with relevant webpages to train and update the online LTR models. To reduce the costs and time consumption of queries/webpages labeling, we study the problem of Activ Learning to Rank (active LTR) that selects unlabeled queries for annotation and training in this work. Specifically, we first investigate the criterion -- Ranking Entropy (RE) characterizing the entropy of relevant webpages under a query produced by a sequence of online LTR models updated by different checkpoints, using a Query-By-Committee (QBC) method. Then, we explore a new criterion namely Prediction Variances (PV) that measures the variance of prediction results for all relevant webpages under a query. Our empirical studies find that RE may favor low-frequency queries from the pool for labeling while PV prioritizing high-frequency queries more. Finally, we combine these two complementary criteria as the sample selection strategies for active learning. Extensive experiments with comparisons to baseline algorithms show that the proposed approach could train LTR models achieving higher Discounted Cumulative Gain (i.e., the relative improvement {\Delta}DCG4=1.38%) with the same budgeted labeling efforts.
FedDUAP: Federated Learning with Dynamic Update and Adaptive Pruning Using Shared Data on the Server
Apr 25, 2022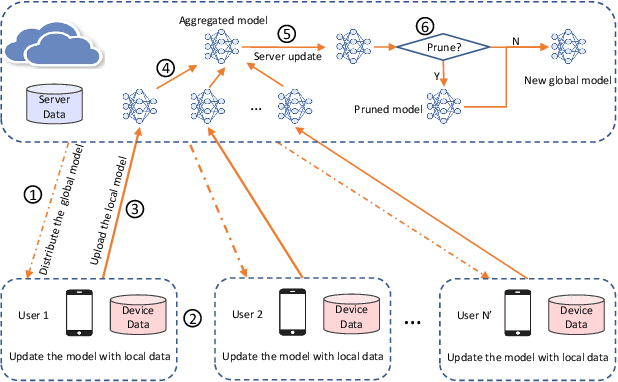
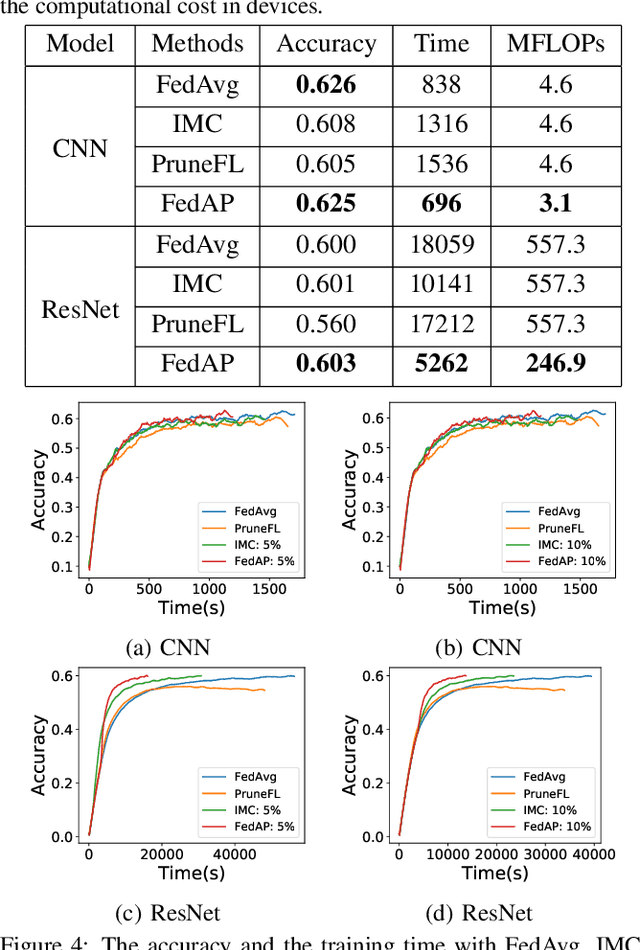
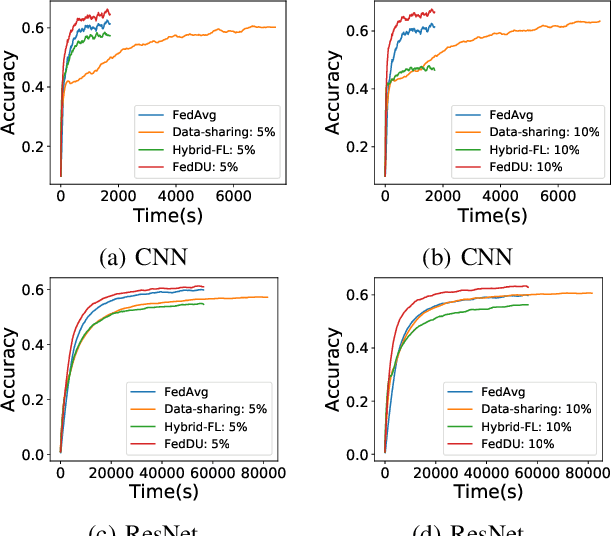
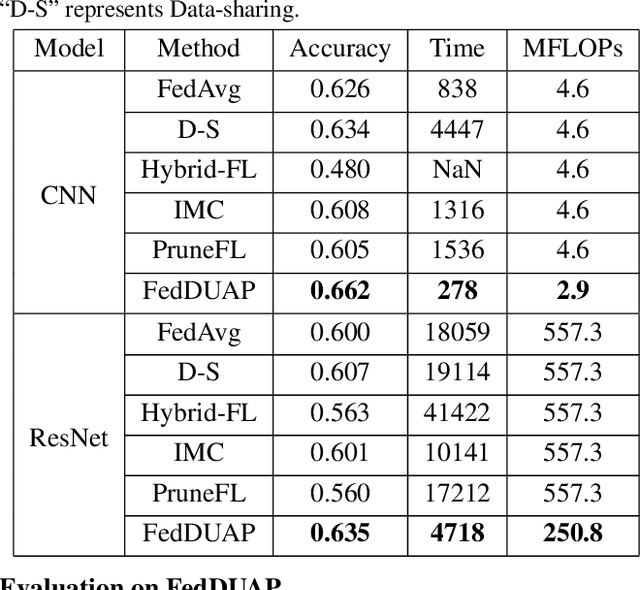
Despite achieving remarkable performance, Federated Learning (FL) suffers from two critical challenges, i.e., limited computational resources and low training efficiency. In this paper, we propose a novel FL framework, i.e., FedDUAP, with two original contributions, to exploit the insensitive data on the server and the decentralized data in edge devices to further improve the training efficiency. First, a dynamic server update algorithm is designed to exploit the insensitive data on the server, in order to dynamically determine the optimal steps of the server update for improving the convergence and accuracy of the global model. Second, a layer-adaptive model pruning method is developed to perform unique pruning operations adapted to the different dimensions and importance of multiple layers, to achieve a good balance between efficiency and effectiveness. By integrating the two original techniques together, our proposed FL model, FedDUAP, significantly outperforms baseline approaches in terms of accuracy (up to 4.8% higher), efficiency (up to 2.8 times faster), and computational cost (up to 61.9% smaller).
Structure-aware Protein Self-supervised Learning
Apr 06, 2022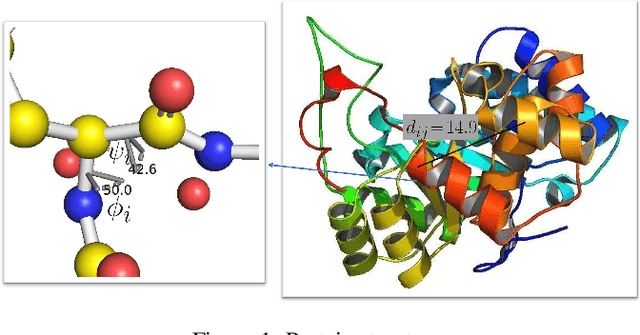
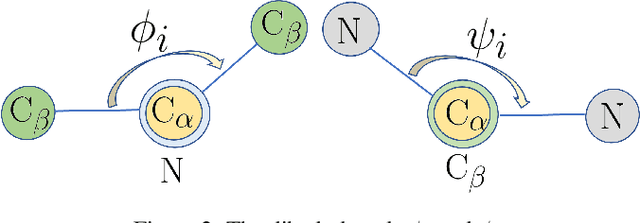
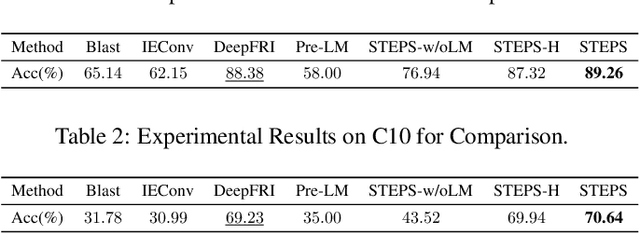
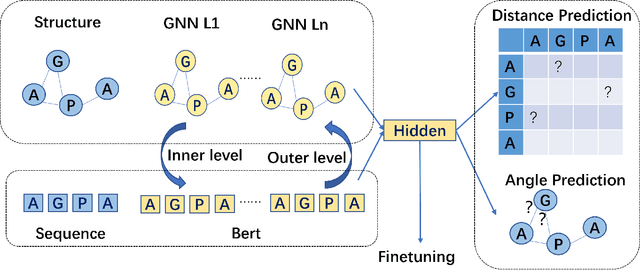
Protein representation learning methods have shown great potential to yield useful representation for many downstream tasks, especially on protein classification. Moreover, a few recent studies have shown great promise in addressing insufficient labels of proteins with self-supervised learning methods. However, existing protein language models are usually pretrained on protein sequences without considering the important protein structural information. To this end, we propose a novel structure-aware protein self-supervised learning method to effectively capture structural information of proteins. In particular, a well-designed graph neural network (GNN) model is pretrained to preserve the protein structural information with self-supervised tasks from a pairwise residue distance perspective and a dihedral angle perspective, respectively. Furthermore, we propose to leverage the available protein language model pretrained on protein sequences to enhance the self-supervised learning. Specifically, we identify the relation between the sequential information in the protein language model and the structural information in the specially designed GNN model via a novel pseudo bi-level optimization scheme. Experiments on several supervised downstream tasks verify the effectiveness of our proposed method.
A Comparative Survey of Deep Active Learning
Mar 25, 2022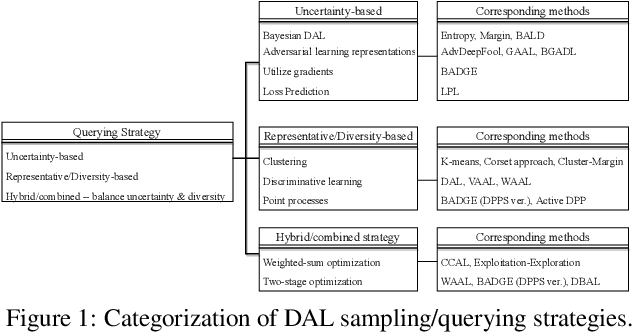
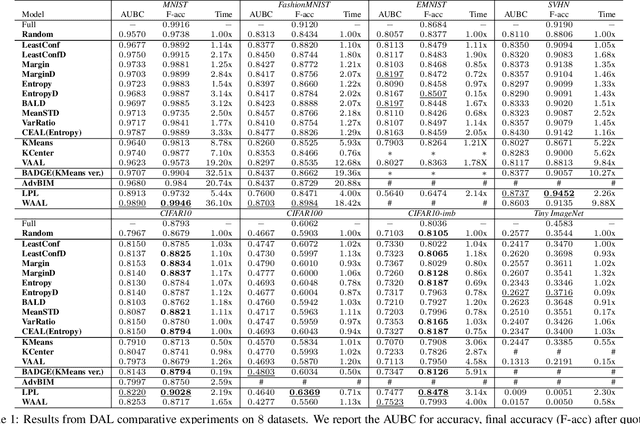
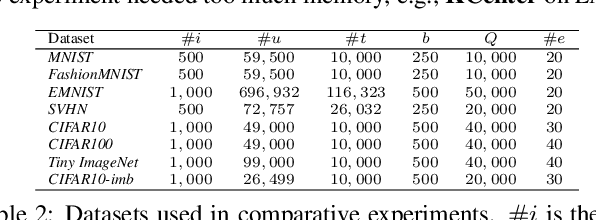
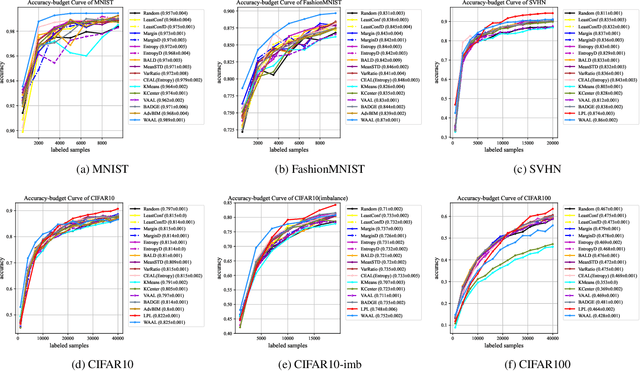
Active Learning (AL) is a set of techniques for reducing labeling cost by sequentially selecting data samples from a large unlabeled data pool for labeling. Meanwhile, Deep Learning (DL) is data-hungry, and the performance of DL models scales monotonically with more training data. Therefore, in recent years, Deep Active Learning (DAL) has risen as feasible solutions for maximizing model performance while minimizing the expensive labeling cost. Abundant methods have sprung up and literature reviews of DAL have been presented before. However, the performance comparison of different branches of DAL methods under various tasks is still insufficient and our work fills this gap. In this paper, we survey and categorize DAL-related work and construct comparative experiments across frequently used datasets and DAL algorithms. Additionally, we explore some factors (e.g., batch size, number of epochs in the training process) that influence the efficacy of DAL, which provides better references for researchers to design their own DAL experiments or carry out DAL-related applications. We construct a DAL toolkit, DeepAL+, by re-implementing many highly-cited DAL-related methods, and it will be released to the public.