 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile Catching with Whole-Body MPC and Blackbox Policy Learning
Jun 14, 2023


We address a benchmark task in agile robotics: catching objects thrown at high-speed. This is a challenging task that involves tracking, intercepting, and cradling a thrown object with access only to visual observations of the object and the proprioceptive state of the robot, all within a fraction of a second. We present the relative merits of two fundamentally different solution strategies: (i) Model Predictive Control using accelerated constrained trajectory optimization, and (ii) Reinforcement Learning using zeroth-order optimization. We provide insights into various performance trade-offs including sample efficiency, sim-to-real transfer, robustness to distribution shifts, and whole-body multimodality via extensive on-hardware experiments. We conclude with proposals on fusing "classical" and "learning-based" techniques for agile robot control. Videos of our experiments may be found at https://sites.google.com/view/agile-catching
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023



Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Efficient Graph Field Integrators Meet Point Clouds
Feb 05, 2023



We present two new classes of algorithms for efficient field integration on graphs encoding point clouds. The first class, SeparatorFactorization(SF), leverages the bounded genus of point cloud mesh graphs, while the second class, RFDiffusion(RFD), uses popular epsilon-nearest-neighbor graph representations for point clouds. Both can be viewed as providing the functionality of Fast Multipole Methods (FMMs), which have had a tremendous impact on efficient integration, but for non-Euclidean spaces. We focus on geometries induced by distributions of walk lengths between points (e.g., shortest-path distance). We provide an extensive theoretical analysis of our algorithms, obtaining new results in structural graph theory as a byproduct. We also perform exhaustive empirical evaluation, including on-surface interpolation for rigid and deformable objects (particularly for mesh-dynamics modeling), Wasserstein distance computations for point clouds, and the Gromov-Wasserstein variant.
Mnemosyne: Learning to Train Transformers with Transformers
Feb 02, 2023Training complex machine learning (ML) architectures requires a compute and time consuming process of selecting the right optimizer and tuning its hyper-parameters. A new paradigm of learning optimizers from data has emerged as a better alternative to hand-designed ML optimizers. We propose Mnemosyne optimizer, that uses Performers: implicit low-rank attention Transformers. It can learn to train entire neural network architectures including other Transformers without any task-specific optimizer tuning. We show that Mnemosyne: (a) generalizes better than popular LSTM optimizer, (b) in particular can successfully train Vision Transformers (ViTs) while meta--trained on standard MLPs and (c) can initialize optimizers for faster convergence in Robotics applications. We believe that these results open the possibility of using Transformers to build foundational optimization models that can address the challenges of regular Transformer training. We complement our results with an extensive theoretical analysis of the compact associative memory used by Mnemosyne.
Implicit Two-Tower Policies
Aug 02, 2022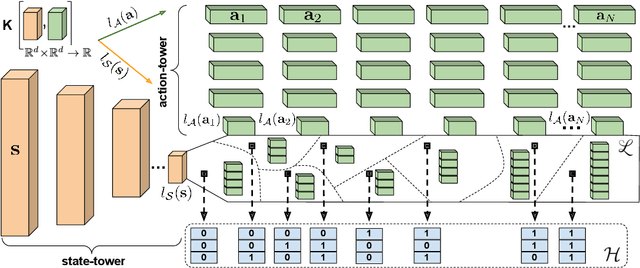
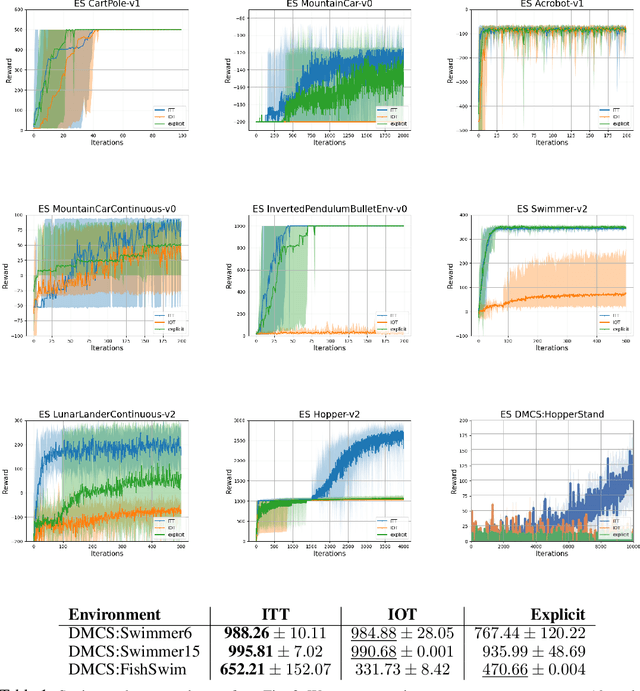
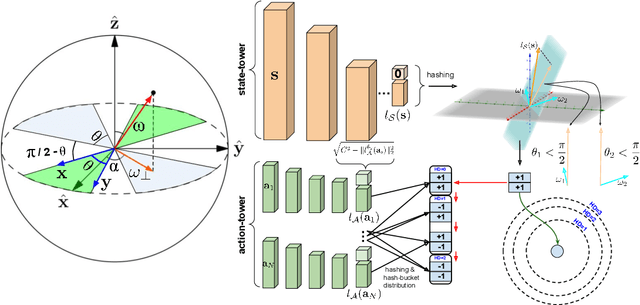
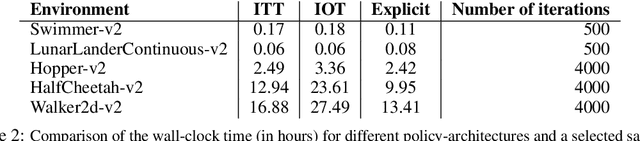
We present a new class of structured reinforcement learning policy-architectures, Implicit Two-Tower (ITT) policies, where the actions are chosen based on the attention scores of their learnable latent representations with those of the input states. By explicitly disentangling action from state processing in the policy stack, we achieve two main goals: substantial computational gains and better performance. Our architectures are compatible with both: discrete and continuous action spaces. By conducting tests on 15 environments from OpenAI Gym and DeepMind Control Suite, we show that ITT-architectures are particularly suited for blackbox/evolutionary optimization and the corresponding policy training algorithms outperform their vanilla unstructured implicit counterparts as well as commonly used explicit policies. We complement our analysis by showing how techniques such as hashing and lazy tower updates, critically relying on the two-tower structure of ITTs, can be applied to obtain additional computational improvements.
Hybrid Random Features
Oct 13, 2021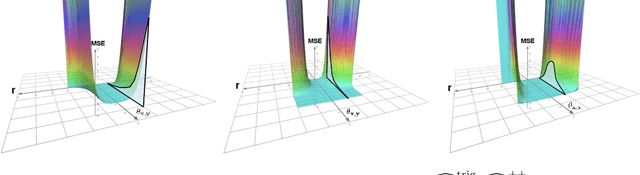
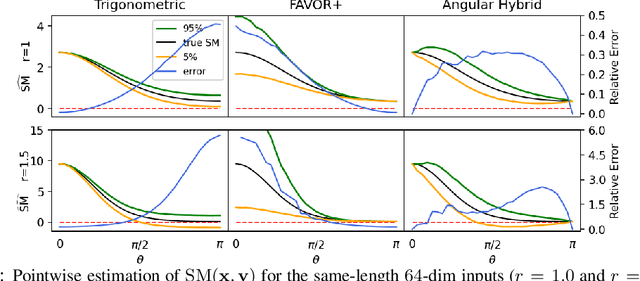
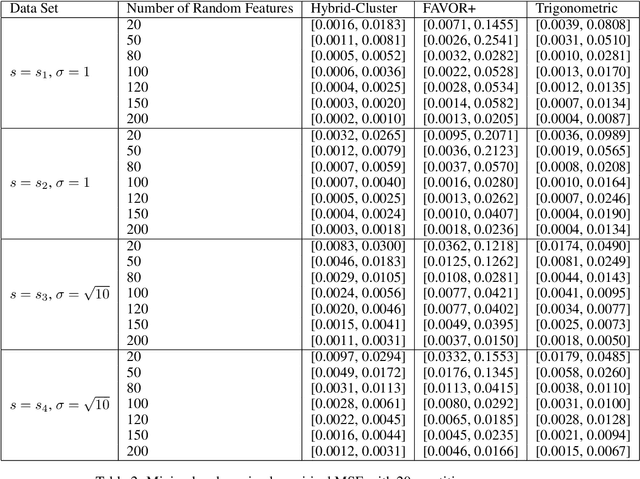
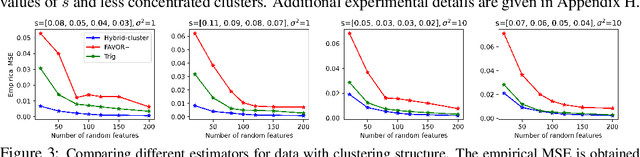
We propose a new class of random feature methods for linearizing softmax and Gaussian kernels called hybrid random features (HRFs) that automatically adapt the quality of kernel estimation to provide most accurate approximation in the defined regions of interest. Special instantiations of HRFs lead to well-known methods such as trigonometric (Rahimi and Recht, 2007) or (recently introduced in the context of linear-attention Transformers) positive random features (Choromanski et al., 2021). By generalizing Bochner's Theorem for softmax/Gaussian kernels and leveraging random features for compositional kernels, the HRF-mechanism provides strong theoretical guarantees - unbiased approximation and strictly smaller worst-case relative errors than its counterparts. We conduct exhaustive empirical evaluation of HRF ranging from pointwise kernel estimation experiments, through tests on data admitting clustering structure to benchmarking implicit-attention Transformers (also for downstream Robotics applications), demonstrating its quality in a wide spectrum of machine learning problems.
Unlocking Pixels for Reinforcement Learning via Implicit Attention
Mar 04, 2021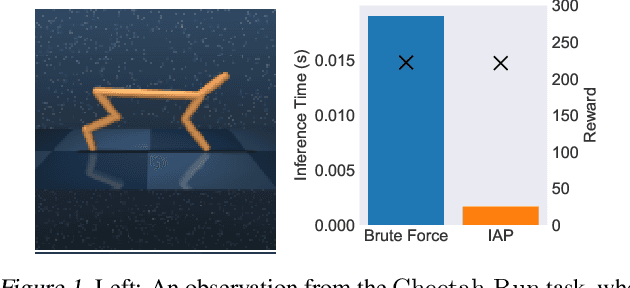
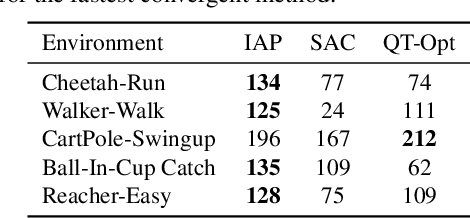
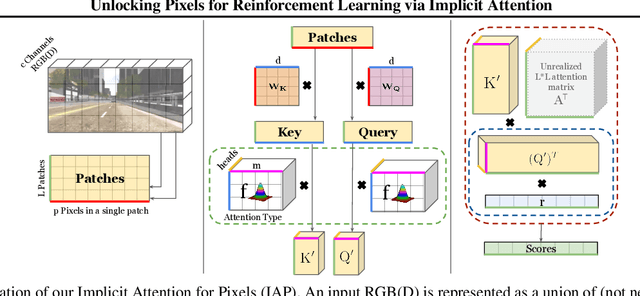

There has recently been significant interest in training reinforcement learning (RL) agents in vision-based environments. This poses many challenges, such as high dimensionality and potential for observational overfitting through spurious correlations. A promising approach to solve both of these problems is a self-attention bottleneck, which provides a simple and effective framework for learning high performing policies, even in the presence of distractions. However, due to poor scalability of attention architectures, these methods do not scale beyond low resolution visual inputs, using large patches (thus small attention matrices). In this paper we make use of new efficient attention algorithms, recently shown to be highly effective for Transformers, and demonstrate that these new techniques can be applied in the RL setting. This allows our attention-based controllers to scale to larger visual inputs, and facilitate the use of smaller patches, even individual pixels, improving generalization. In addition, we propose a new efficient algorithm approximating softmax attention with what we call hybrid random features, leveraging the theory of angular kernels. We show theoretically and empirically that hybrid random features is a promising approach when using attention for vision-based RL.
ES-ENAS: Combining Evolution Strategies with Neural Architecture Search at No Extra Cost for Reinforcement Learning
Jan 19, 2021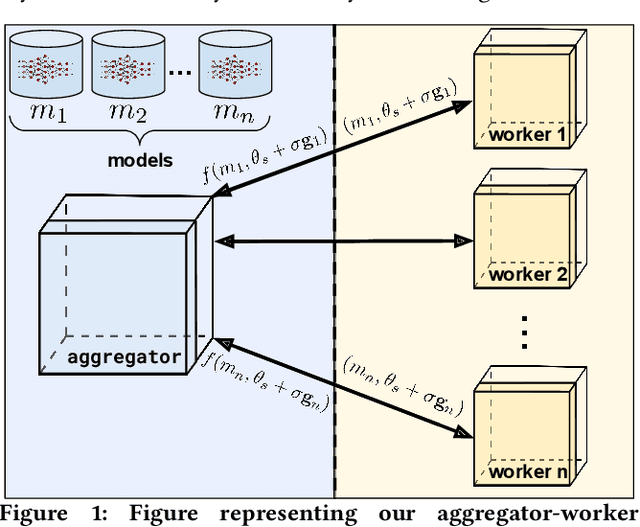

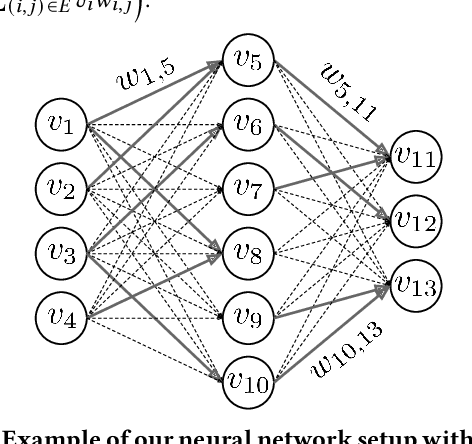
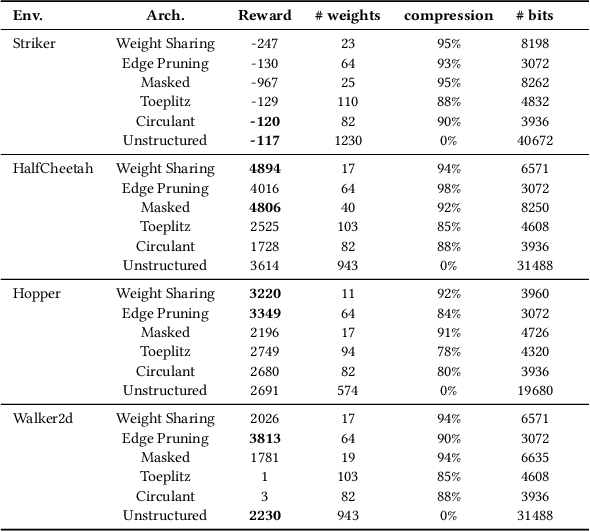
We introduce ES-ENAS, a simple neural architecture search (NAS) algorithm for the purpose of reinforcement learning (RL) policy design, by combining Evolutionary Strategies (ES) and Efficient NAS (ENAS) in a highly scalable and intuitive way. Our main insight is noticing that ES is already a distributed blackbox algorithm, and thus we may simply insert a model controller from ENAS into the central aggregator in ES and obtain weight sharing properties for free. By doing so, we bridge the gap from NAS research in supervised learning settings to the reinforcement learning scenario through this relatively simple marriage between two different lines of research, and are one of the first to apply controller-based NAS techniques to RL. We demonstrate the utility of our method by training combinatorial neural network architectures for RL problems in continuous control, via edge pruning and weight sharing. We also incorporate a wide variety of popular techniques from modern NAS literature, including multiobjective optimization and varying controller methods, to showcase their promise in the RL field and discuss possible extensions. We achieve >90% network compression for multiple tasks, which may be special interest in mobile robotics with limited storage and computational resources.
Disentangled Planning and Control in Vision Based Robotics via Reward Machines
Dec 28, 2020
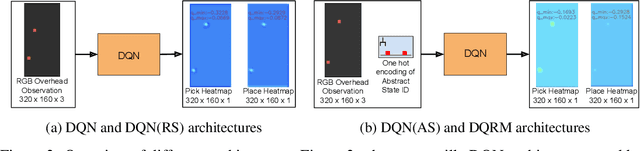
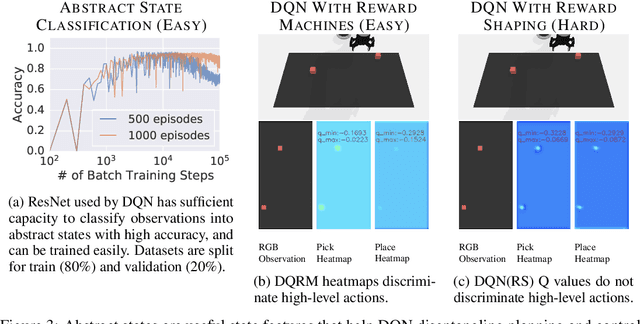
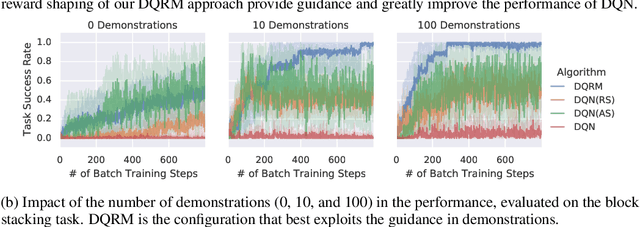
In this work we augment a Deep Q-Learning agent with a Reward Machine (DQRM) to increase speed of learning vision-based policies for robot tasks, and overcome some of the limitations of DQN that prevent it from converging to good-quality policies. A reward machine (RM) is a finite state machine that decomposes a task into a discrete planning graph and equips the agent with a reward function to guide it toward task completion. The reward machine can be used for both reward shaping, and informing the policy what abstract state it is currently at. An abstract state is a high level simplification of the current state, defined in terms of task relevant features. These two supervisory signals of reward shaping and knowledge of current abstract state coming from the reward machine complement each other and can both be used to improve policy performance as demonstrated on several vision based robotic pick and place tasks. Particularly for vision based robotics applications, it is often easier to build a reward machine than to try and get a policy to learn the task without this structure.
From Pixels to Legs: Hierarchical Learning of Quadruped Locomotion
Nov 23, 2020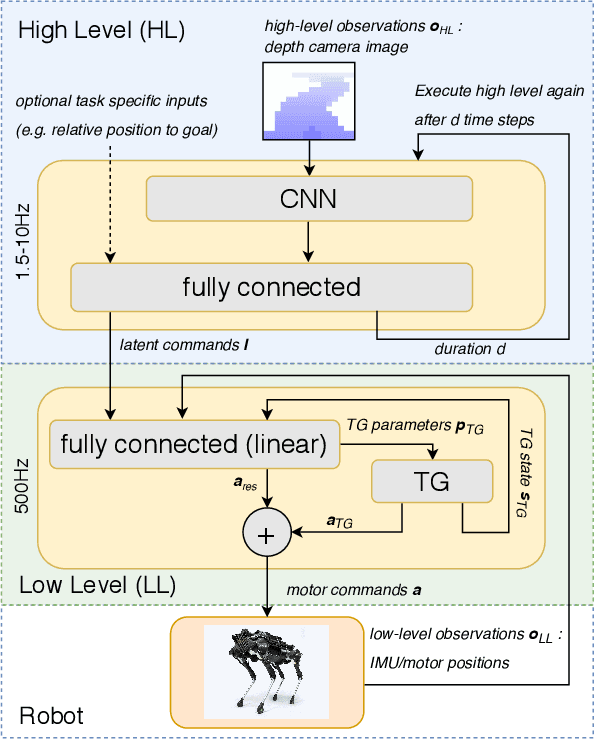

Legged robots navigating crowded scenes and complex terrains in the real world are required to execute dynamic leg movements while processing visual input for obstacle avoidance and path planning. We show that a quadruped robot can acquire both of these skills by means of hierarchical reinforcement learning (HRL). By virtue of their hierarchical structure, our policies learn to implicitly break down this joint problem by concurrently learning High Level (HL) and Low Level (LL) neural network policies. These two levels are connected by a low dimensional hidden layer, which we call latent command. HL receives a first-person camera view, whereas LL receives the latent command from HL and the robot's on-board sensors to control its actuators. We train policies to walk in two different environments: a curved cliff and a maze. We show that hierarchical policies can concurrently learn to locomote and navigate in these environments, and show they are more efficient than non-hierarchical neural network policies. This architecture also allows for knowledge reuse across tasks. LL networks trained on one task can be transferred to a new task in a new environment. Finally HL, which processes camera images, can be evaluated at much lower and varying frequencies compared to LL, thus reducing computation times and bandwidth requirements.