 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Self-Incentivization Empowers Large Language Models as Agentic Searchers
May 26, 2025Large language models (LLMs) have been widely integrated into information retrieval to advance traditional techniques. However, effectively enabling LLMs to seek accurate knowledge in complex tasks remains a challenge due to the complexity of multi-hop queries as well as the irrelevant retrieved content. To address these limitations, we propose EXSEARCH, an agentic search framework, where the LLM learns to retrieve useful information as the reasoning unfolds through a self-incentivized process. At each step, the LLM decides what to retrieve (thinking), triggers an external retriever (search), and extracts fine-grained evidence (recording) to support next-step reasoning. To enable LLM with this capability, EXSEARCH adopts a Generalized Expectation-Maximization algorithm. In the E-step, the LLM generates multiple search trajectories and assigns an importance weight to each; the M-step trains the LLM on them with a re-weighted loss function. This creates a self-incentivized loop, where the LLM iteratively learns from its own generated data, progressively improving itself for search. We further theoretically analyze this training process, establishing convergence guarantees. Extensive experiments on four knowledge-intensive benchmarks show that EXSEARCH substantially outperforms baselines, e.g., +7.8% improvement on exact match score. Motivated by these promising results, we introduce EXSEARCH-Zoo, an extension that extends our method to broader scenarios, to facilitate future work.
Joint Flashback Adaptation for Forgetting-Resistant Instruction Tuning
May 21, 2025Large language models have achieved remarkable success in various tasks. However, it is challenging for them to learn new tasks incrementally due to catastrophic forgetting. Existing approaches rely on experience replay, optimization constraints, or task differentiation, which encounter strict limitations in real-world scenarios. To address these issues, we propose Joint Flashback Adaptation. We first introduce flashbacks -- a limited number of prompts from old tasks -- when adapting to new tasks and constrain the deviations of the model outputs compared to the original one. We then interpolate latent tasks between flashbacks and new tasks to enable jointly learning relevant latent tasks, new tasks, and flashbacks, alleviating data sparsity in flashbacks and facilitating knowledge sharing for smooth adaptation. Our method requires only a limited number of flashbacks without access to the replay data and is task-agnostic. We conduct extensive experiments on state-of-the-art large language models across 1000+ instruction-following tasks, arithmetic reasoning tasks, and general reasoning tasks. The results demonstrate the superior performance of our method in improving generalization on new tasks and reducing forgetting in old tasks.
Direct Retrieval-augmented Optimization: Synergizing Knowledge Selection and Language Models
May 05, 2025Retrieval-augmented generation (RAG) integrates large language models ( LLM s) with retrievers to access external knowledge, improving the factuality of LLM generation in knowledge-grounded tasks. To optimize the RAG performance, most previous work independently fine-tunes the retriever to adapt to frozen LLM s or trains the LLMs to use documents retrieved by off-the-shelf retrievers, lacking end-to-end training supervision. Recent work addresses this limitation by jointly training these two components but relies on overly simplifying assumptions of document independence, which has been criticized for being far from real-world scenarios. Thus, effectively optimizing the overall RAG performance remains a critical challenge. We propose a direct retrieval-augmented optimization framework, named DRO, that enables end-to-end training of two key components: (i) a generative knowledge selection model and (ii) an LLM generator. DRO alternates between two phases: (i) document permutation estimation and (ii) re-weighted maximization, progressively improving RAG components through a variational approach. In the estimation step, we treat document permutation as a latent variable and directly estimate its distribution from the selection model by applying an importance sampling strategy. In the maximization step, we calibrate the optimization expectation using importance weights and jointly train the selection model and LLM generator. Our theoretical analysis reveals that DRO is analogous to policy-gradient methods in reinforcement learning. Extensive experiments conducted on five datasets illustrate that DRO outperforms the best baseline with 5%-15% improvements in EM and F1. We also provide in-depth experiments to qualitatively analyze the stability, convergence, and variance of DRO.
Replication and Exploration of Generative Retrieval over Dynamic Corpora
Apr 24, 2025Generative retrieval (GR) has emerged as a promising paradigm in information retrieval (IR). However, most existing GR models are developed and evaluated using a static document collection, and their performance in dynamic corpora where document collections evolve continuously is rarely studied. In this paper, we first reproduce and systematically evaluate various representative GR approaches over dynamic corpora. Through extensive experiments, we reveal that existing GR models with \textit{text-based} docids show superior generalization to unseen documents. We observe that the more fine-grained the docid design in the GR model, the better its performance over dynamic corpora, surpassing BM25 and even being comparable to dense retrieval methods. While GR models with \textit{numeric-based} docids show high efficiency, their performance drops significantly over dynamic corpora. Furthermore, our experiments find that the underperformance of numeric-based docids is partly due to their excessive tendency toward the initial document set, which likely results from overfitting on the training set. We then conduct an in-depth analysis of the best-performing GR methods. We identify three critical advantages of text-based docids in dynamic corpora: (i) Semantic alignment with language models' pretrained knowledge, (ii) Fine-grained docid design, and (iii) High lexical diversity. Building on these insights, we finally propose a novel multi-docid design that leverages both the efficiency of numeric-based docids and the effectiveness of text-based docids, achieving improved performance in dynamic corpus without requiring additional retraining. Our work offers empirical evidence for advancing GR methods over dynamic corpora and paves the way for developing more generalized yet efficient GR models in real-world search engines.
From Prompting to Alignment: A Generative Framework for Query Recommendation
Apr 14, 2025
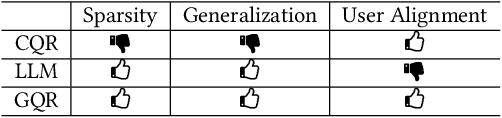
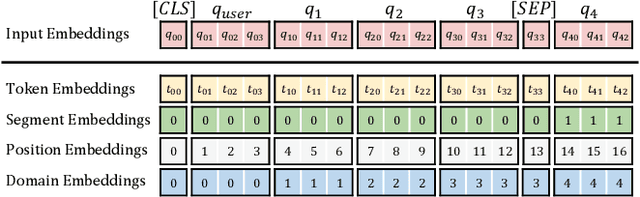
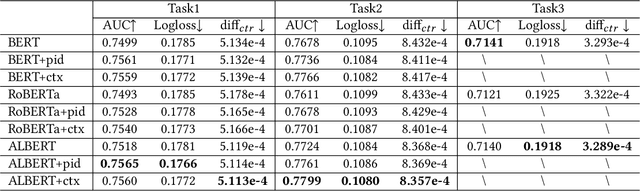
In modern search systems, search engines often suggest relevant queries to users through various panels or components, helping refine their information needs. Traditionally, these recommendations heavily rely on historical search logs to build models, which suffer from cold-start or long-tail issues. Furthermore, tasks such as query suggestion, completion or clarification are studied separately by specific design, which lacks generalizability and hinders adaptation to novel applications. Despite recent attempts to explore the use of LLMs for query recommendation, these methods mainly rely on the inherent knowledge of LLMs or external sources like few-shot examples, retrieved documents, or knowledge bases, neglecting the importance of the calibration and alignment with user feedback, thus limiting their practical utility. To address these challenges, we first propose a general Generative Query Recommendation (GQR) framework that aligns LLM-based query generation with user preference. Specifically, we unify diverse query recommendation tasks by a universal prompt framework, leveraging the instruct-following capability of LLMs for effective generation. Secondly, we align LLMs with user feedback via presenting a CTR-alignment framework, which involves training a query-wise CTR predictor as a process reward model and employing list-wise preference alignment to maximize the click probability of the generated query list. Furthermore, recognizing the inconsistency between LLM knowledge and proactive search intents arising from the separation of user-initiated queries from models, we align LLMs with user initiative via retrieving co-occurrence queries as side information when historical logs are available.
TP-RAG: Benchmarking Retrieval-Augmented Large Language Model Agents for Spatiotemporal-Aware Travel Planning
Apr 11, 2025Large language models (LLMs) have shown promise in automating travel planning, yet they often fall short in addressing nuanced spatiotemporal rationality. While existing benchmarks focus on basic plan validity, they neglect critical aspects such as route efficiency, POI appeal, and real-time adaptability. This paper introduces TP-RAG, the first benchmark tailored for retrieval-augmented, spatiotemporal-aware travel planning. Our dataset includes 2,348 real-world travel queries, 85,575 fine-grain annotated POIs, and 18,784 high-quality travel trajectory references sourced from online tourist documents, enabling dynamic and context-aware planning. Through extensive experiments, we reveal that integrating reference trajectories significantly improves spatial efficiency and POI rationality of the travel plan, while challenges persist in universality and robustness due to conflicting references and noisy data. To address these issues, we propose EvoRAG, an evolutionary framework that potently synergizes diverse retrieved trajectories with LLMs' intrinsic reasoning. EvoRAG achieves state-of-the-art performance, improving spatiotemporal compliance and reducing commonsense violation compared to ground-up and retrieval-augmented baselines. Our work underscores the potential of hybridizing Web knowledge with LLM-driven optimization, paving the way for more reliable and adaptive travel planning agents.
Leveraging LLMs for Utility-Focused Annotation: Reducing Manual Effort for Retrieval and RAG
Apr 08, 2025Retrieval models typically rely on costly human-labeled query-document relevance annotations for training and evaluation. To reduce this cost and leverage the potential of Large Language Models (LLMs) in relevance judgments, we aim to explore whether LLM-generated annotations can effectively replace human annotations in training retrieval models. Retrieval usually emphasizes relevance, which indicates "topic-relatedness" of a document to a query, while in RAG, the value of a document (or utility) depends on how it contributes to answer generation. Recognizing this mismatch, some researchers use LLM performance on downstream tasks with documents as labels, but this approach requires manual answers for specific tasks, leading to high costs and limited generalization. In another line of work, prompting LLMs to select useful documents as RAG references eliminates the need for human annotation and is not task-specific. If we leverage LLMs' utility judgments to annotate retrieval data, we may retain cross-task generalization without human annotation in large-scale corpora. Therefore, we investigate utility-focused annotation via LLMs for large-scale retriever training data across both in-domain and out-of-domain settings on the retrieval and RAG tasks. To reduce the impact of low-quality positives labeled by LLMs, we design a novel loss function, i.e., Disj-InfoNCE. Our experiments reveal that: (1) Retrievers trained on utility-focused annotations significantly outperform those trained on human annotations in the out-of-domain setting on both tasks, demonstrating superior generalization capabilities. (2) LLM annotation does not replace human annotation in the in-domain setting. However, incorporating just 20% human-annotated data enables retrievers trained with utility-focused annotations to match the performance of models trained entirely with human annotations.
Unleashing the Power of LLMs in Dense Retrieval with Query Likelihood Modeling
Apr 07, 2025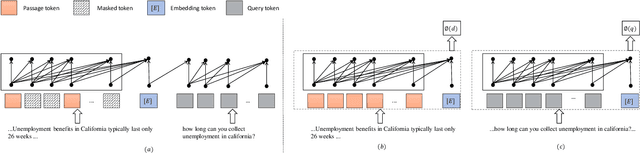
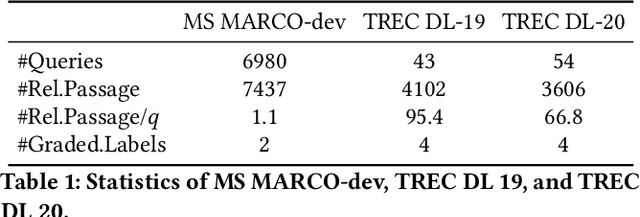
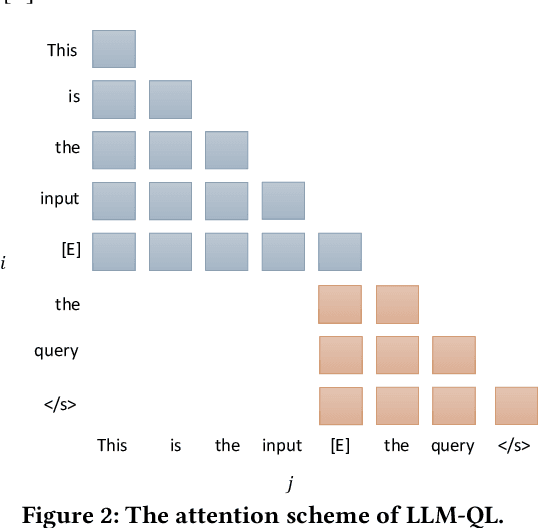
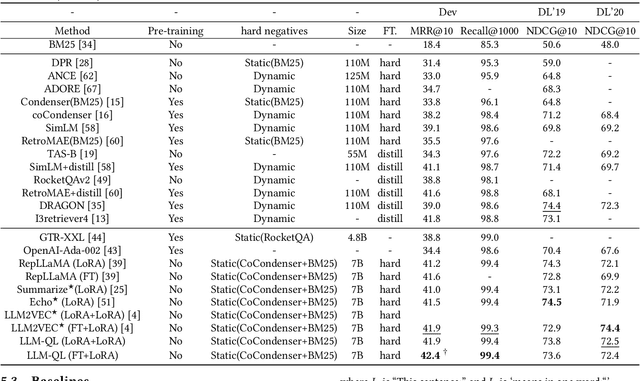
Dense retrieval is a crucial task in Information Retrieval (IR) and is the foundation for downstream tasks such as re-ranking. Recently, large language models (LLMs) have shown compelling semantic understanding capabilities and are appealing to researchers studying dense retrieval. LLMs, as decoder-style generative models, are competent at language generation while falling short on modeling global information due to the lack of attention to tokens afterward. Inspired by the classical word-based language modeling approach for IR, i.e., the query likelihood (QL) model, we seek to sufficiently utilize LLMs' generative ability by QL maximization. However, instead of ranking documents with QL estimation, we introduce an auxiliary task of QL maximization to yield a better backbone for contrastively learning a discriminative retriever. We name our model as LLM-QL. To condense global document semantics to a single vector during QL modeling, LLM-QL has two major components, Attention Stop (AS) and Input Corruption (IC). AS stops the attention of predictive tokens to previous tokens until the ending token of the document. IC masks a portion of tokens in the input documents during prediction. Experiments on MSMARCO show that LLM-QL can achieve significantly better performance than other LLM-based retrievers and using QL estimated by LLM-QL for ranking outperforms word-based QL by a large margin.
CoRanking: Collaborative Ranking with Small and Large Ranking Agents
Apr 01, 2025Large Language Models (LLMs) have demonstrated superior listwise ranking performance. However, their superior performance often relies on large-scale parameters (\eg, GPT-4) and a repetitive sliding window process, which introduces significant efficiency challenges. In this paper, we propose \textbf{CoRanking}, a novel collaborative ranking framework that combines small and large ranking models for efficient and effective ranking. CoRanking first employs a small-size reranker to pre-rank all the candidate passages, bringing relevant ones to the top part of the list (\eg, top-20). Then, the LLM listwise reranker is applied to only rerank these top-ranked passages instead of the whole list, substantially enhancing overall ranking efficiency. Although more efficient, previous studies have revealed that the LLM listwise reranker have significant positional biases on the order of input passages. Directly feed the top-ranked passages from small reranker may result in the sub-optimal performance of LLM listwise reranker. To alleviate this problem, we introduce a passage order adjuster trained via reinforcement learning, which reorders the top passages from the small reranker to align with the LLM's preferences of passage order. Extensive experiments on three IR benchmarks demonstrate that CoRanking significantly improves efficiency (reducing ranking latency by about 70\%) while achieving even better effectiveness compared to using only the LLM listwise reranker.
Towards Next-Generation Recommender Systems: A Benchmark for Personalized Recommendation Assistant with LLMs
Mar 12, 2025Recommender systems (RecSys) are widely used across various modern digital platforms and have garnered significant attention. Traditional recommender systems usually focus only on fixed and simple recommendation scenarios, making it difficult to generalize to new and unseen recommendation tasks in an interactive paradigm. Recently, the advancement of large language models (LLMs) has revolutionized the foundational architecture of RecSys, driving their evolution into more intelligent and interactive personalized recommendation assistants. However, most existing studies rely on fixed task-specific prompt templates to generate recommendations and evaluate the performance of personalized assistants, which limits the comprehensive assessments of their capabilities. This is because commonly used datasets lack high-quality textual user queries that reflect real-world recommendation scenarios, making them unsuitable for evaluating LLM-based personalized recommendation assistants. To address this gap, we introduce RecBench+, a new dataset benchmark designed to access LLMs' ability to handle intricate user recommendation needs in the era of LLMs. RecBench+ encompasses a diverse set of queries that span both hard conditions and soft preferences, with varying difficulty levels. We evaluated commonly used LLMs on RecBench+ and uncovered below findings: 1) LLMs demonstrate preliminary abilities to act as recommendation assistants, 2) LLMs are better at handling queries with explicitly stated conditions, while facing challenges with queries that require reasoning or contain misleading information. Our dataset has been released at https://github.com/jiani-huang/RecBench.git.