 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized to Persuade: The Effects of Contextualization and Warmth on Trust and Reliance in Conversational AI
May 29, 2026Artificial Intelligence (AI) agents personalize their responses by tailoring explanations to users' backgrounds, interests, and prior interactions, referred to as contextualization. Personalization has been identified as a persuasive strategy in politics or in marketing. However, the persuasive effect of contextualization in everyday tasks, where users often lack prior knowledge, remains unclear. We conducted a $2\times2$ between-subjects experiment ($N = 380$) examining how contextualization, combined with conversational warmth, shapes reliance and persuasiveness of an AI assistant arguing against expert recommendations. Our findings reveal that contextualization reduces the persuasive power of AI, but its combination with warmth restores persuasiveness through a crossover interaction. Reliance on AI is present across conditions and is invariant to the conversational design. Trust strongly predicts both persuasion and reliance, yet neither contextualization nor warmth operates through trust. AI literacy decouples trust from behavior: more literate users report lower trust in the assistant, yet are more persuaded and more reliant on its advice. These results suggest that users are prone to deferring to AI agents over human expert judgment; however, interface-level conversational design choices have a limited role in shaping the behavior.
The Decision to Verify: How Warmth and User Characteristics Shape Reliance on Conversational Agents for Information Search
May 27, 2026Conversational artificial intelligence (AI) provides an efficient and convenient gateway to information access. However, it can cause overreliance when users blindly trust AI and accept its answers without fact-checking. Information search increasingly follows a hybrid interaction paradigm that combines conversational AI with web search, making fact-checking easier. In this paper, we examine whether this interaction paradigm is effective in curbing reliance. We further investigate the underlying factors (e.g., digital literacy and conversation warmth) that drive users to verify AI answers. We conduct a mixed-subjects question-answering experiment where participants interact with either a warm or a neutral chatbot. Our findings reveal that reliance persists despite users having access to both conversational and web search. The decision to verify is driven primarily by existing user perceptions (e.g., prior trust in chatbots) rather than answer properties, with some users fact-checking regardless of the context and others trusting chatbots by default. Warm conversational style has an indirect yet critical influence on reliance by increasing agreement with the chatbot when it is incorrect. Consulting additional AI sources predicts higher accuracy, while traditional web search does not. Our study extends overreliance research by: (a) demonstrating its persistence despite access to fact-checking, (b) identifying verification behavior as user-dependent, and (c) revealing conversational warmth's indirect effect on overreliance with implications for designing trustworthy conversational search systems.
Search for Coverage: Learning Coverage-Aware Retrieval with Augmented Sub-Question Answerability
May 27, 2026Long-form Retrieval-Augmented Generation (RAG) brings the challenge of coverage-based ranking, because ranking methods must ensure the inclusion of comprehensive relevant nuggets (i.e., facts), which can thereby be synthesized into a comprehensive output. In this work, we propose CoveR (Our code is available at https://github.com/DylanJoo/CoveR ) a dense retrieval method optimized for coverage-aware retrieval scenarios. CoveR is a bi-encoder trained with the coverage-based contrastive and distillation objectives, which enables CoveR to capture diverse aspects of information needs. To train CoveR, we create the SCOPE dataset, (Our training data is available at https://huggingface.co/datasets/DylanJHJ/scope ) which comprises 90K training pairs from Researchy Questions with synthetic coverage signals augmented from sub-question answerability judgments generated by LLMs. Our empirical experiments show that CoveR enhances nugget coverage by 10\% over strong dense retrieval baselines without sacrificing its relevance-based retrieval capability. Further ablation studies validate the importance of our proposed learning method, showing that CoveR achieves a superior trade-off between relevance- and coverage-based ranking, which is essential for long-form RAG.
RankSteer: Activation Steering for Pointwise LLM Ranking
Feb 03, 2026Large language models (LLMs) have recently shown strong performance as zero-shot rankers, yet their effectiveness is highly sensitive to prompt formulation, particularly role-play instructions. Prior analyses suggest that role-related signals are encoded along activation channels that are largely separate from query-document representations, raising the possibility of steering ranking behavior directly at the activation level rather than through brittle prompt engineering. In this work, we propose RankSteer, a post-hoc activation steering framework for zero-shot pointwise LLM ranking. We characterize ranking behavior through three disentangled and steerable directions in representation space: a \textbf{decision direction} that maps hidden states to relevance scores, an \textbf{evidence direction} that captures relevance signals not directly exploited by the decision head, and a \textbf{role direction} that modulates model behavior without injecting relevance information. Using projection-based interventions at inference time, RankSteer jointly controls these directions to calibrate ranking behavior without modifying model weights or introducing explicit cross-document comparisons. Experiments on TREC DL 20 and multiple BEIR benchmarks show that RankSteer consistently improves ranking quality using only a small number of anchor queries, demonstrating that substantial ranking capacity remains under-utilized in pointwise LLM rankers. We further provide a geometric analysis revealing that steering improves ranking by stabilizing ranking geometry and reducing dispersion, offering new insight into how LLMs internally represent and calibrate relevance judgments.
LANCER: LLM Reranking for Nugget Coverage
Jan 29, 2026Unlike short-form retrieval-augmented generation (RAG), such as factoid question answering, long-form RAG requires retrieval to provide documents covering a wide range of relevant information. Automated report generation exemplifies this setting: it requires not only relevant information but also a more elaborate response with comprehensive information. Yet, existing retrieval methods are primarily optimized for relevance ranking rather than information coverage. To address this limitation, we propose LANCER, an LLM-based reranking method for nugget coverage. LANCER predicts what sub-questions should be answered to satisfy an information need, predicts which documents answer these sub-questions, and reranks documents in order to provide a ranked list covering as many information nuggets as possible. Our empirical results show that LANCER enhances the quality of retrieval as measured by nugget coverage metrics, achieving higher $α$-nDCG and information coverage than other LLM-based reranking methods. Our oracle analysis further reveals that sub-question generation plays an essential role.
Differentiable Semantic ID for Generative Recommendation
Jan 27, 2026Generative recommendation provides a novel paradigm in which each item is represented by a discrete semantic ID (SID) learned from rich content. Most existing methods treat SIDs as predefined and train recommenders under static indexing. In practice, SIDs are typically optimized only for content reconstruction rather than recommendation accuracy. This leads to an objective mismatch: the system optimizes an indexing loss to learn the SID and a recommendation loss for interaction prediction, but because the tokenizer is trained independently, the recommendation loss cannot update it. A natural approach is to make semantic indexing differentiable so that recommendation gradients can directly influence SID learning, but this often causes codebook collapse, where only a few codes are used. We attribute this issue to early deterministic assignments that limit codebook exploration, resulting in imbalance and unstable optimization. In this paper, we propose DIGER (Differentiable Semantic ID for Generative Recommendation), a first step toward effective differentiable semantic IDs for generative recommendation. DIGER introduces Gumbel noise to explicitly encourage early-stage exploration over codes, mitigating codebook collapse and improving code utilization. To balance exploration and convergence, we further design two uncertainty decay strategies that gradually reduce the Gumbel noise, enabling a smooth transition from early exploration to exploitation of learned SIDs. Extensive experiments on multiple public datasets demonstrate consistent improvements from differentiable semantic IDs. These results confirm the effectiveness of aligning indexing and recommendation objectives through differentiable SIDs and highlight differentiable semantic indexing as a promising research direction.
Analyzing Cancer Patients' Experiences with Embedding-based Topic Modeling and LLMs
Jan 17, 2026This study investigates the use of neural topic modeling and LLMs to uncover meaningful themes from patient storytelling data, to offer insights that could contribute to more patient-oriented healthcare practices. We analyze a collection of transcribed interviews with cancer patients (132,722 words in 13 interviews). We first evaluate BERTopic and Top2Vec for individual interview summarization by using similar preprocessing, chunking, and clustering configurations to ensure a fair comparison on Keyword Extraction. LLMs (GPT4) are then used for the next step topic labeling. Their outputs for a single interview (I0) are rated through a small-scale human evaluation, focusing on {coherence}, {clarity}, and {relevance}. Based on the preliminary results and evaluation, BERTopic shows stronger performance and is selected for further experimentation using three {clinically oriented embedding} models. We then analyzed the full interview collection with the best model setting. Results show that domain-specific embeddings improved topic \textit{precision} and \textit{interpretability}, with BioClinicalBERT producing the most consistent results across transcripts. The global analysis of the full dataset of 13 interviews, using the BioClinicalBERT embedding model, reveals the most dominant topics throughout all 13 interviews, namely ``Coordination and Communication in Cancer Care Management" and ``Patient Decision-Making in Cancer Treatment Journey''. Although the interviews are machine translations from Dutch to English, and clinical professionals are not involved in this evaluation, the findings suggest that neural topic modeling, particularly BERTopic, can help provide useful feedback to clinicians from patient interviews. This pipeline could support more efficient document navigation and strengthen the role of patients' voices in healthcare workflows.
Unifying Search and Recommendation in LLMs via Gradient Multi-Subspace Tuning
Jan 14, 2026Search and recommendation (S&R) are core to online platforms, addressing explicit intent through queries and modeling implicit intent from behaviors, respectively. Their complementary roles motivate a unified modeling paradigm. Early studies to unify S&R adopt shared encoders with task-specific heads, while recent efforts reframe item ranking in both S&R as conditional generation. The latter holds particular promise, enabling end-to-end optimization and leveraging the semantic understanding of LLMs. However, existing methods rely on full fine-tuning, which is computationally expensive and limits scalability. Parameter-efficient fine-tuning (PEFT) offers a more practical alternative but faces two critical challenges in unifying S&R: (1) gradient conflicts across tasks due to divergent optimization objectives, and (2) shifts in user intent understanding caused by overfitting to fine-tuning data, which distort general-domain knowledge and weaken LLM reasoning. To address the above issues, we propose Gradient Multi-Subspace Tuning (GEMS), a novel framework that unifies S&R with LLMs while alleviating gradient conflicts and preserving general-domain knowledge. GEMS introduces (1) \textbf{Multi-Subspace Decomposition}, which disentangles shared and task-specific optimization signals into complementary low-rank subspaces, thereby reducing destructive gradient interference, and (2) \textbf{Null-Space Projection}, which constrains parameter updates to a subspace orthogonal to the general-domain knowledge space, mitigating shifts in user intent understanding. Extensive experiments on benchmark datasets show that GEMS consistently outperforms the state-of-the-art baselines across both search and recommendation tasks, achieving superior effectiveness.
HealthcareNLP: where are we and what is next?
Dec 09, 2025

This proposed tutorial focuses on Healthcare Domain Applications of NLP, what we have achieved around HealthcareNLP, and the challenges that lie ahead for the future. Existing reviews in this domain either overlook some important tasks, such as synthetic data generation for addressing privacy concerns, or explainable clinical NLP for improved integration and implementation, or fail to mention important methodologies, including retrieval augmented generation and the neural symbolic integration of LLMs and KGs. In light of this, the goal of this tutorial is to provide an introductory overview of the most important sub-areas of a patient- and resource-oriented HealthcareNLP, with three layers of hierarchy: data/resource layer: annotation guidelines, ethical approvals, governance, synthetic data; NLP-Eval layer: NLP tasks such as NER, RE, sentiment analysis, and linking/coding with categorised methods, leading to explainable HealthAI; patients layer: Patient Public Involvement and Engagement (PPIE), health literacy, translation, simplification, and summarisation (also NLP tasks), and shared decision-making support. A hands-on session will be included in the tutorial for the audience to use HealthcareNLP applications. The target audience includes NLP practitioners in the healthcare application domain, NLP researchers who are interested in domain applications, healthcare researchers, and students from NLP fields. The type of tutorial is "Introductory to CL/NLP topics (HealthcareNLP)" and the audience does not need prior knowledge to attend this. Tutorial materials: https://github.com/4dpicture/HealthNLP
Personality over Precision: Exploring the Influence of Human-Likeness on ChatGPT Use for Search
Nov 09, 2025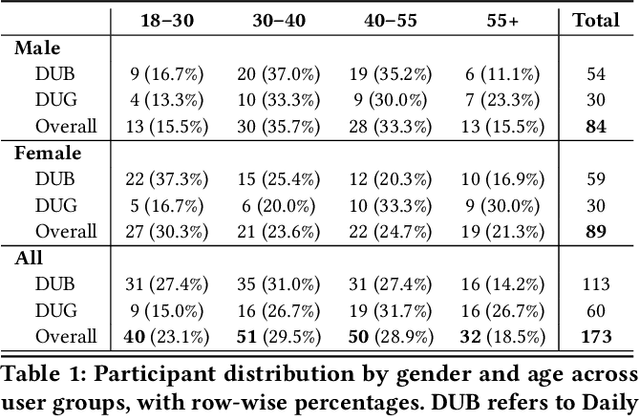
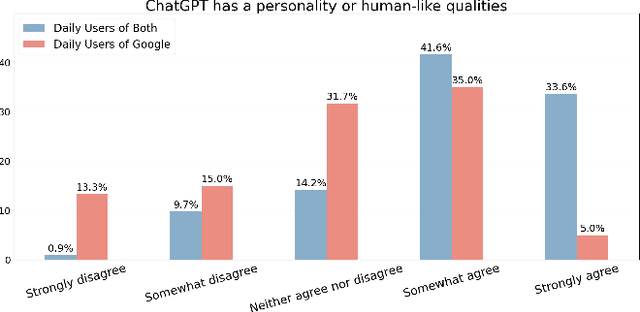
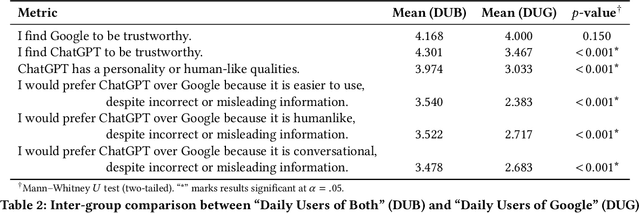
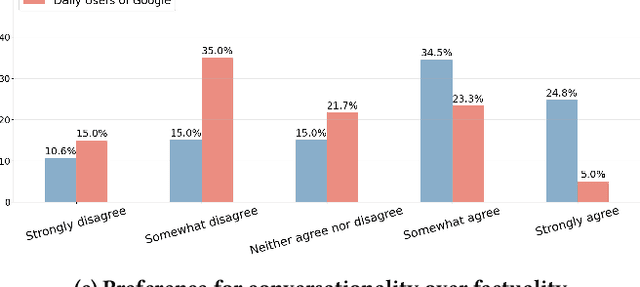
Conversational search interfaces, like ChatGPT, offer an interactive, personalized, and engaging user experience compared to traditional search. On the downside, they are prone to cause overtrust issues where users rely on their responses even when they are incorrect. What aspects of the conversational interaction paradigm drive people to adopt it, and how it creates personalized experiences that lead to overtrust, is not clear. To understand the factors influencing the adoption of conversational interfaces, we conducted a survey with 173 participants. We examined user perceptions regarding trust, human-likeness (anthropomorphism), and design preferences between ChatGPT and Google. To better understand the overtrust phenomenon, we asked users about their willingness to trade off factuality for constructs like ease of use or human-likeness. Our analysis identified two distinct user groups: those who use both ChatGPT and Google daily (DUB), and those who primarily rely on Google (DUG). The DUB group exhibited higher trust in ChatGPT, perceiving it as more human-like, and expressed greater willingness to trade factual accuracy for enhanced personalization and conversational flow. Conversely, the DUG group showed lower trust toward ChatGPT but still appreciated aspects like ad-free experiences and responsive interactions. Demographic analysis further revealed nuanced patterns, with middle-aged adults using ChatGPT less frequently yet trusting it more, suggesting potential vulnerability to misinformation. Our findings contribute to understanding user segmentation, emphasizing the critical roles of personalization and human-likeness in conversational IR systems, and reveal important implications regarding users' willingness to compromise factual accuracy for more engaging interactions.