 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogPurge: Log Data Purification for Anomaly Detection via Rule-Enhanced Filtering
Nov 18, 2025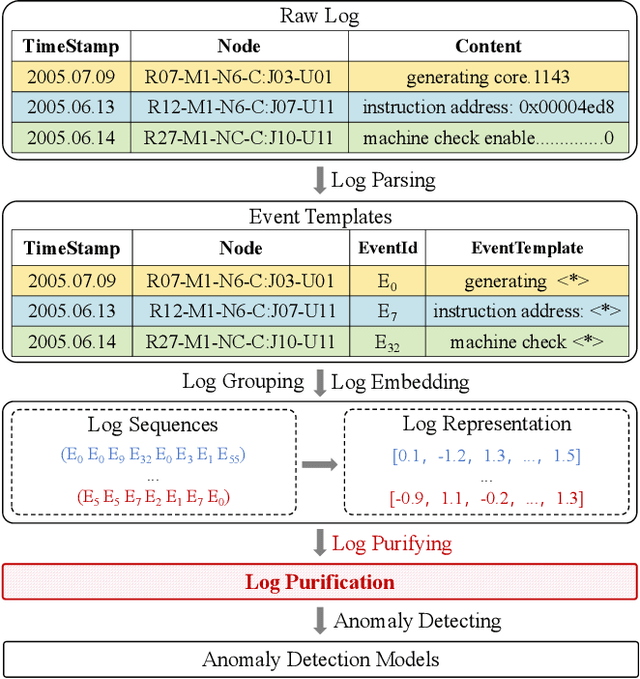
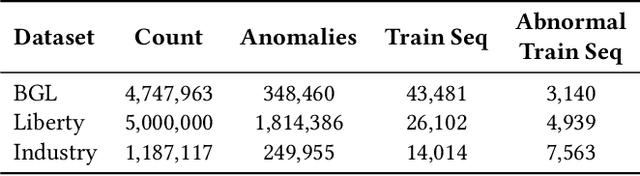
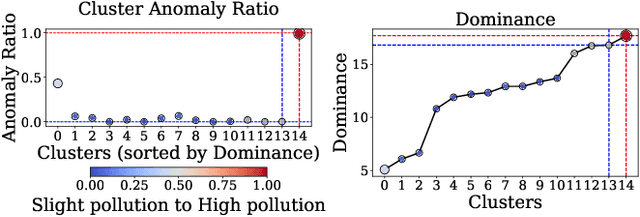
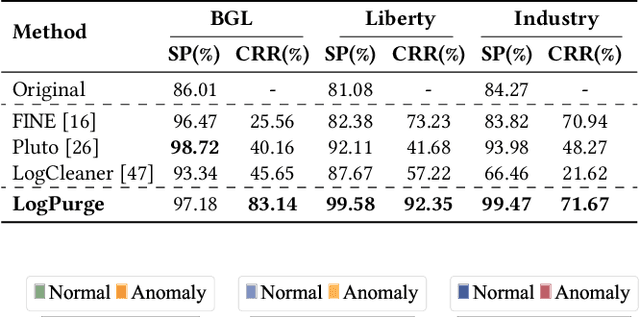
Log anomaly detection, which is critical for identifying system failures and preempting security breaches, detects irregular patterns within large volumes of log data, and impacts domains such as service reliability, performance optimization, and database log analysis. Modern log anomaly detection methods rely on training deep learning models on clean, anomaly-free log sequences. However, obtaining such clean log data requires costly and tedious human labeling, and existing automatic cleaning methods fail to fully integrate the specific characteristics and actual semantics of logs in their purification process. In this paper, we propose a cost-aware, rule-enhanced purification framework, LogPurge, that automatically selects a sufficient subset of normal log sequences from contamination log sequences to train a anomaly detection model. Our approach involves a two-stage filtering algorithm: In the first stage, we use a large language model (LLM) to remove clustered anomalous patterns and enhance system rules to improve LLM's understanding of system logs; in the second stage, we utilize a divide-and-conquer strategy that decomposes the remaining contaminated regions into smaller subproblems, allowing each to be effectively purified through the first stage procedure. Our experiments, conducted on two public datasets and one industrial dataset, show that our method significantly removes an average of 98.74% of anomalies while retaining 82.39% of normal samples. Compared to the latest unsupervised log sample selection algorithms, our method achieves F-1 score improvements of 35.7% and 84.11% on the public datasets, and an impressive 149.72% F-1 improvement on the private dataset, demonstrating the effectiveness of our approach.
TimeSense:Making Large Language Models Proficient in Time-Series Analysis
Nov 09, 2025In the time-series domain, an increasing number of works combine text with temporal data to leverage the reasoning capabilities of large language models (LLMs) for various downstream time-series understanding tasks. This enables a single model to flexibly perform tasks that previously required specialized models for each domain. However, these methods typically rely on text labels for supervision during training, biasing the model toward textual cues while potentially neglecting the full temporal features. Such a bias can lead to outputs that contradict the underlying time-series context. To address this issue, we construct the EvalTS benchmark, comprising 10 tasks across three difficulty levels, from fundamental temporal pattern recognition to complex real-world reasoning, to evaluate models under more challenging and realistic scenarios. We also propose TimeSense, a multimodal framework that makes LLMs proficient in time-series analysis by balancing textual reasoning with a preserved temporal sense. TimeSense incorporates a Temporal Sense module that reconstructs the input time-series within the model's context, ensuring that textual reasoning is grounded in the time-series dynamics. Moreover, to enhance spatial understanding of time-series data, we explicitly incorporate coordinate-based positional embeddings, which provide each time point with spatial context and enable the model to capture structural dependencies more effectively. Experimental results demonstrate that TimeSense achieves state-of-the-art performance across multiple tasks, and it particularly outperforms existing methods on complex multi-dimensional time-series reasoning tasks.
ViTs: Teaching Machines to See Time Series Anomalies Like Human Experts
Oct 06, 2025



Web service administrators must ensure the stability of multiple systems by promptly detecting anomalies in Key Performance Indicators (KPIs). Achieving the goal of "train once, infer across scenarios" remains a fundamental challenge for time series anomaly detection models. Beyond improving zero-shot generalization, such models must also flexibly handle sequences of varying lengths during inference, ranging from one hour to one week, without retraining. Conventional approaches rely on sliding-window encoding and self-supervised learning, which restrict inference to fixed-length inputs. Large Language Models (LLMs) have demonstrated remarkable zero-shot capabilities across general domains. However, when applied to time series data, they face inherent limitations due to context length. To address this issue, we propose ViTs, a Vision-Language Model (VLM)-based framework that converts time series curves into visual representations. By rescaling time series images, temporal dependencies are preserved while maintaining a consistent input size, thereby enabling efficient processing of arbitrarily long sequences without context constraints. Training VLMs for this purpose introduces unique challenges, primarily due to the scarcity of aligned time series image-text data. To overcome this, we employ an evolutionary algorithm to automatically generate thousands of high-quality image-text pairs and design a three-stage training pipeline consisting of: (1) time series knowledge injection, (2) anomaly detection enhancement, and (3) anomaly reasoning refinement. Extensive experiments demonstrate that ViTs substantially enhance the ability of VLMs to understand and detect anomalies in time series data. All datasets and code will be publicly released at: https://anonymous.4open.science/r/ViTs-C484/.
CMoS: Rethinking Time Series Prediction Through the Lens of Chunk-wise Spatial Correlations
May 25, 2025Recent advances in lightweight time series forecasting models suggest the inherent simplicity of time series forecasting tasks. In this paper, we present CMoS, a super-lightweight time series forecasting model. Instead of learning the embedding of the shapes, CMoS directly models the spatial correlations between different time series chunks. Additionally, we introduce a Correlation Mixing technique that enables the model to capture diverse spatial correlations with minimal parameters, and an optional Periodicity Injection technique to ensure faster convergence. Despite utilizing as low as 1% of the lightweight model DLinear's parameters count, experimental results demonstrate that CMoS outperforms existing state-of-the-art models across multiple datasets. Furthermore, the learned weights of CMoS exhibit great interpretability, providing practitioners with valuable insights into temporal structures within specific application scenarios.
Position: Empowering Time Series Reasoning with Multimodal LLMs
Feb 03, 2025



Understanding time series data is crucial for multiple real-world applications. While large language models (LLMs) show promise in time series tasks, current approaches often rely on numerical data alone, overlooking the multimodal nature of time-dependent information, such as textual descriptions, visual data, and audio signals. Moreover, these methods underutilize LLMs' reasoning capabilities, limiting the analysis to surface-level interpretations instead of deeper temporal and multimodal reasoning. In this position paper, we argue that multimodal LLMs (MLLMs) can enable more powerful and flexible reasoning for time series analysis, enhancing decision-making and real-world applications. We call on researchers and practitioners to leverage this potential by developing strategies that prioritize trust, interpretability, and robust reasoning in MLLMs. Lastly, we highlight key research directions, including novel reasoning paradigms, architectural innovations, and domain-specific applications, to advance time series reasoning with MLLMs.
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning
Dec 04, 2024



Understanding time series is crucial for its application in real-world scenarios. Recently, large language models (LLMs) have been increasingly applied to time series tasks, leveraging their strong language capabilities to enhance various applications. However, research on multimodal LLMs (MLLMs) for time series understanding and reasoning remains limited, primarily due to the scarcity of high-quality datasets that align time series with textual information. This paper introduces ChatTS, a novel MLLM designed for time series analysis. ChatTS treats time series as a modality, similar to how vision MLLMs process images, enabling it to perform both understanding and reasoning with time series. To address the scarcity of training data, we propose an attribute-based method for generating synthetic time series with detailed attribute descriptions. We further introduce Time Series Evol-Instruct, a novel approach that generates diverse time series Q&As, enhancing the model's reasoning capabilities. To the best of our knowledge, ChatTS is the first MLLM that takes multivariate time series as input, which is fine-tuned exclusively on synthetic datasets. We evaluate its performance using benchmark datasets with real-world data, including six alignment tasks and four reasoning tasks. Our results show that ChatTS significantly outperforms existing vision-based MLLMs (e.g., GPT-4o) and text/agent-based LLMs, achieving a 46.0% improvement in alignment tasks and a 25.8% improvement in reasoning tasks.
KAN-AD: Time Series Anomaly Detection with Kolmogorov-Arnold Networks
Nov 01, 2024



Time series anomaly detection (TSAD) has become an essential component of large-scale cloud services and web systems because it can promptly identify anomalies, providing early warnings to prevent greater losses. Deep learning-based forecasting methods have become very popular in TSAD due to their powerful learning capabilities. However, accurate predictions don't necessarily lead to better anomaly detection. Due to the common occurrence of noise, i.e., local peaks and drops in time series, existing black-box learning methods can easily learn these unintended patterns, significantly affecting anomaly detection performance. Kolmogorov-Arnold Networks (KAN) offers a potential solution by decomposing complex temporal sequences into a combination of multiple univariate functions, making the training process more controllable. However, KAN optimizes univariate functions using spline functions, which are also susceptible to the influence of local anomalies. To address this issue, we present KAN-AD, which leverages the Fourier series to emphasize global temporal patterns, thereby mitigating the influence of local peaks and drops. KAN-AD improves both effectiveness and efficiency by transforming the existing black-box learning approach into learning the weights preceding univariate functions. Experimental results show that, compared to the current state-of-the-art, we achieved an accuracy increase of 15% while boosting inference speed by 55 times.
Enhanced Fine-Tuning of Lightweight Domain-Specific Q&A Model Based on Large Language Models
Aug 23, 2024



Large language models (LLMs) excel at general question-answering (Q&A) but often fall short in specialized domains due to a lack of domain-specific knowledge. Commercial companies face the dual challenges of privacy protection and resource constraints when involving LLMs for fine-tuning. This paper propose a novel framework, Self-Evolution, designed to address these issues by leveraging lightweight open-source LLMs through multiple iterative fine-tuning rounds. To enhance the efficiency of iterative fine-tuning, Self-Evolution employ a strategy that filters and reinforces the knowledge with higher value during the iterative process. We employed Self-Evolution on Qwen1.5-7B-Chat using 4,000 documents containing rich domain knowledge from China Mobile, achieving a performance score 174% higher on domain-specific question-answering evaluations than Qwen1.5-7B-Chat and even 22% higher than Qwen1.5-72B-Chat. Self-Evolution has been deployed in China Mobile's daily operation and maintenance for 117 days, and it improves the efficiency of locating alarms, fixing problems, and finding related reports, with an average efficiency improvement of over 18.6%. In addition, we release Self-Evolution framework code in https://github.com/Zero-Pointer/Self-Evolution.
LogEval: A Comprehensive Benchmark Suite for Large Language Models In Log Analysis
Jul 02, 2024



Log analysis is crucial for ensuring the orderly and stable operation of information systems, particularly in the field of Artificial Intelligence for IT Operations (AIOps). Large Language Models (LLMs) have demonstrated significant potential in natural language processing tasks. In the AIOps domain, they excel in tasks such as anomaly detection, root cause analysis of faults, operations and maintenance script generation, and alert information summarization. However, the performance of current LLMs in log analysis tasks remains inadequately validated. To address this gap, we introduce LogEval, a comprehensive benchmark suite designed to evaluate the capabilities of LLMs in various log analysis tasks for the first time. This benchmark covers tasks such as log parsing, log anomaly detection, log fault diagnosis, and log summarization. LogEval evaluates each task using 4,000 publicly available log data entries and employs 15 different prompts for each task to ensure a thorough and fair assessment. By rigorously evaluating leading LLMs, we demonstrate the impact of various LLM technologies on log analysis performance, focusing on aspects such as self-consistency and few-shot contextual learning. We also discuss findings related to model quantification, Chinese-English question-answering evaluation, and prompt engineering. These findings provide insights into the strengths and weaknesses of LLMs in multilingual environments and the effectiveness of different prompt strategies. Various evaluation methods are employed for different tasks to accurately measure the performance of LLMs in log analysis, ensuring a comprehensive assessment. The insights gained from LogEvals evaluation reveal the strengths and limitations of LLMs in log analysis tasks, providing valuable guidance for researchers and practitioners.
TimeSeriesBench: An Industrial-Grade Benchmark for Time Series Anomaly Detection Models
Feb 26, 2024Driven by the proliferation of real-world application scenarios and scales, time series anomaly detection (TSAD) has attracted considerable scholarly and industrial interest. However, existing algorithms exhibit a gap in terms of training paradigm, online detection paradigm, and evaluation criteria when compared to the actual needs of real-world industrial systems. Firstly, current algorithms typically train a specific model for each individual time series. In a large-scale online system with tens of thousands of curves, maintaining such a multitude of models is impractical. The performance of using merely one single unified model to detect anomalies remains unknown. Secondly, most TSAD models are trained on the historical part of a time series and are tested on its future segment. In distributed systems, however, there are frequent system deployments and upgrades, with new, previously unseen time series emerging daily. The performance of testing newly incoming unseen time series on current TSAD algorithms remains unknown. Lastly, although some papers have conducted detailed surveys, the absence of an online evaluation platform prevents answering questions like "Who is the best at anomaly detection at the current stage?" In this paper, we propose TimeSeriesBench, an industrial-grade benchmark that we continuously maintain as a leaderboard. On this leaderboard, we assess the performance of existing algorithms across more than 168 evaluation settings combining different training and testing paradigms, evaluation metrics and datasets. Through our comprehensive analysis of the results, we provide recommendations for the future design of anomaly detection algorithms. To address known issues with existing public datasets, we release an industrial dataset to the public together with TimeSeriesBench. All code, data, and the online leaderboard have been made publicly available.