 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKairosVL: Orchestrating Time Series and Semantics for Unified Reasoning
Feb 24, 2026Driven by the increasingly complex and decision-oriented demands of time series analysis, we introduce the Semantic-Conditional Time Series Reasoning task, which extends conventional time series analysis beyond purely numerical modeling to incorporate contextual and semantic understanding. To further enhance the mode's reasoning capabilities on complex time series problems, we propose a two-round reinforcement learning framework: the first round strengthens the mode's perception of fundamental temporal primitives, while the second focuses on semantic-conditioned reasoning. The resulting model, KairosVL, achieves competitive performance across both synthetic and real-world tasks. Extensive experiments and ablation studies demonstrate that our framework not only boosts performance but also preserves intrinsic reasoning ability and significantly improves generalization to unseen scenarios. To summarize, our work highlights the potential of combining semantic reasoning with temporal modeling and provides a practical framework for real-world time series intelligence, which is in urgent demand.
Does Scaling Law Apply in Time Series Forecasting?
May 15, 2025Rapid expansion of model size has emerged as a key challenge in time series forecasting. From early Transformer with tens of megabytes to recent architectures like TimesNet with thousands of megabytes, performance gains have often come at the cost of exponentially increasing parameter counts. But is this scaling truly necessary? To question the applicability of the scaling law in time series forecasting, we propose Alinear, an ultra-lightweight forecasting model that achieves competitive performance using only k-level parameters. We introduce a horizon-aware adaptive decomposition mechanism that dynamically rebalances component emphasis across different forecast lengths, alongside a progressive frequency attenuation strategy that achieves stable prediction in various forecasting horizons without incurring the computational overhead of attention mechanisms. Extensive experiments on seven benchmark datasets demonstrate that Alinear consistently outperforms large-scale models while using less than 1% of their parameters, maintaining strong accuracy across both short and ultra-long forecasting horizons. Moreover, to more fairly evaluate model efficiency, we propose a new parameter-aware evaluation metric that highlights the superiority of ALinear under constrained model budgets. Our analysis reveals that the relative importance of trend and seasonal components varies depending on data characteristics rather than following a fixed pattern, validating the necessity of our adaptive design. This work challenges the prevailing belief that larger models are inherently better and suggests a paradigm shift toward more efficient time series modeling.
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning
Dec 04, 2024



Understanding time series is crucial for its application in real-world scenarios. Recently, large language models (LLMs) have been increasingly applied to time series tasks, leveraging their strong language capabilities to enhance various applications. However, research on multimodal LLMs (MLLMs) for time series understanding and reasoning remains limited, primarily due to the scarcity of high-quality datasets that align time series with textual information. This paper introduces ChatTS, a novel MLLM designed for time series analysis. ChatTS treats time series as a modality, similar to how vision MLLMs process images, enabling it to perform both understanding and reasoning with time series. To address the scarcity of training data, we propose an attribute-based method for generating synthetic time series with detailed attribute descriptions. We further introduce Time Series Evol-Instruct, a novel approach that generates diverse time series Q&As, enhancing the model's reasoning capabilities. To the best of our knowledge, ChatTS is the first MLLM that takes multivariate time series as input, which is fine-tuned exclusively on synthetic datasets. We evaluate its performance using benchmark datasets with real-world data, including six alignment tasks and four reasoning tasks. Our results show that ChatTS significantly outperforms existing vision-based MLLMs (e.g., GPT-4o) and text/agent-based LLMs, achieving a 46.0% improvement in alignment tasks and a 25.8% improvement in reasoning tasks.
Generic and Robust Root Cause Localization for Multi-Dimensional Data in Online Service Systems
May 05, 2023



Localizing root causes for multi-dimensional data is critical to ensure online service systems' reliability. When a fault occurs, only the measure values within specific attribute combinations are abnormal. Such attribute combinations are substantial clues to the underlying root causes and thus are called root causes of multidimensional data. This paper proposes a generic and robust root cause localization approach for multi-dimensional data, PSqueeze. We propose a generic property of root cause for multi-dimensional data, generalized ripple effect (GRE). Based on it, we propose a novel probabilistic cluster method and a robust heuristic search method. Moreover, we identify the importance of determining external root causes and propose an effective method for the first time in literature. Our experiments on two real-world datasets with 5400 faults show that the F1-score of PSqueeze outperforms baselines by 32.89%, while the localization time is around 10 seconds across all cases. The F1-score in determining external root causes of PSqueeze achieves 0.90. Furthermore, case studies in several production systems demonstrate that PSqueeze is helpful to fault diagnosis in the real world.
Causal Inference-Based Root Cause Analysis for Online Service Systems with Intervention Recognition
Jun 13, 2022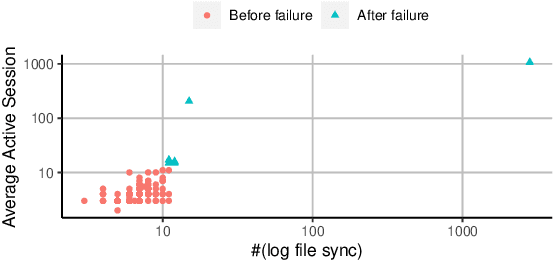
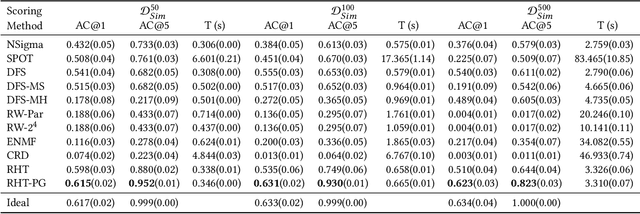
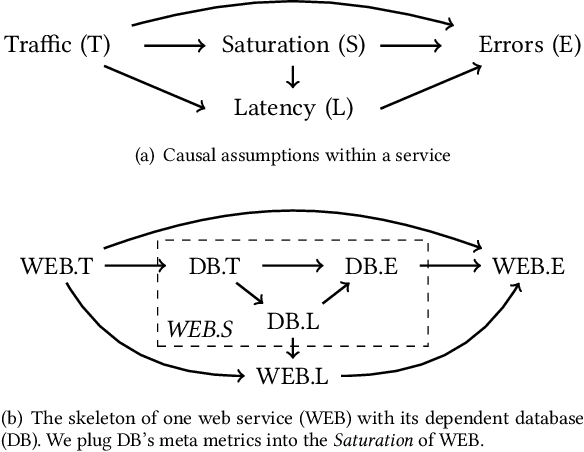
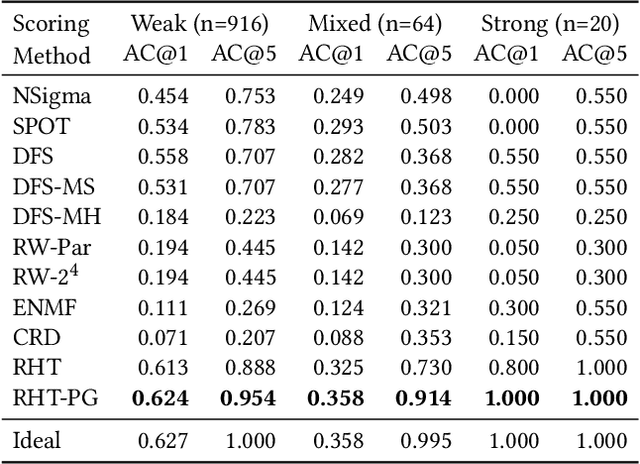
Fault diagnosis is critical in many domains, as faults may lead to safety threats or economic losses. In the field of online service systems, operators rely on enormous monitoring data to detect and mitigate failures. Quickly recognizing a small set of root cause indicators for the underlying fault can save much time for failure mitigation. In this paper, we formulate the root cause analysis problem as a new causal inference task named intervention recognition. We proposed a novel unsupervised causal inference-based method named Causal Inference-based Root Cause Analysis (CIRCA). The core idea is a sufficient condition for a monitoring variable to be a root cause indicator, i.e., the change of probability distribution conditioned on the parents in the Causal Bayesian Network (CBN). Towards the application in online service systems, CIRCA constructs a graph among monitoring metrics based on the knowledge of system architecture and a set of causal assumptions. The simulation study illustrates the theoretical reliability of CIRCA. The performance on a real-world dataset further shows that CIRCA can improve the recall of the top-1 recommendation by 25% over the best baseline method.
GenAD: General Representations of Multivariate Time Seriesfor Anomaly Detection
Feb 09, 2022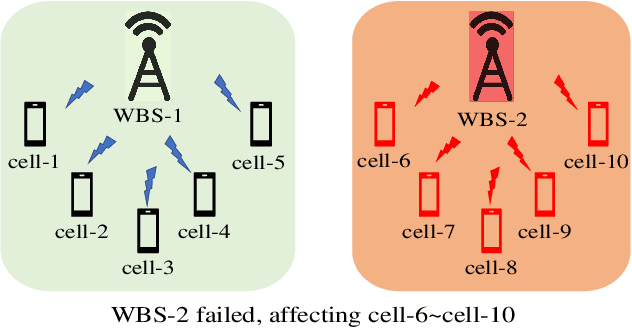
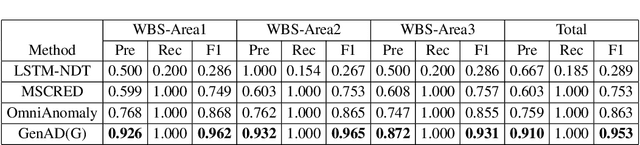
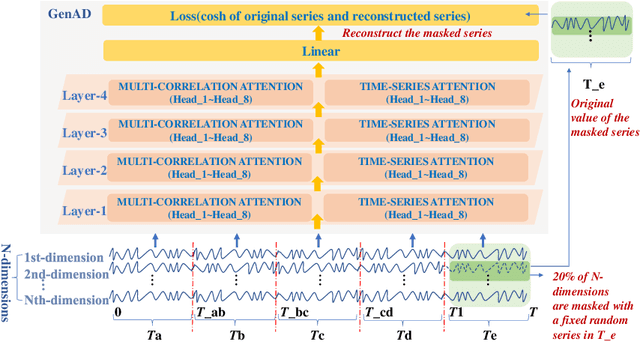

The reliability of wireless base stations in China Mobile is of vital importance, because the cell phone users are connected to the stations and the behaviors of the stations are directly related to user experience. Although the monitoring of the station behaviors can be realized by anomaly detection on multivariate time series, due to complex correlations and various temporal patterns of multivariate series in large-scale stations, building a general unsupervised anomaly detection model with a higher F1-score remains a challenging task. In this paper, we propose a General representation of multivariate time series for Anomaly Detection(GenAD). First, we pre-train a general model on large-scale wireless base stations with self-supervision, which can be easily transferred to a specific station anomaly detection with a small amount of training data. Second, we employ Multi-Correlation Attention and Time-Series Attention to represent the correlations and temporal patterns of the stations. With the above innovations, GenAD increases F1-score by total 9% on real-world datasets in China Mobile, while the performance does not significantly degrade on public datasets with only 10% of the training data.
Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications
Feb 12, 2018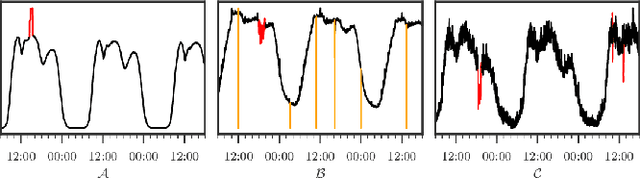
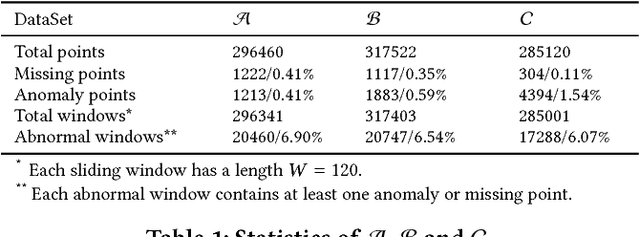
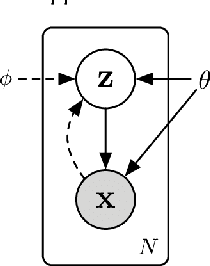

To ensure undisrupted business, large Internet companies need to closely monitor various KPIs (e.g., Page Views, number of online users, and number of orders) of its Web applications, to accurately detect anomalies and trigger timely troubleshooting/mitigation. However, anomaly detection for these seasonal KPIs with various patterns and data quality has been a great challenge, especially without labels. In this paper, we proposed Donut, an unsupervised anomaly detection algorithm based on VAE. Thanks to a few of our key techniques, Donut greatly outperforms a state-of-arts supervised ensemble approach and a baseline VAE approach, and its best F-scores range from 0.75 to 0.9 for the studied KPIs from a top global Internet company. We come up with a novel KDE interpretation of reconstruction for Donut, making it the first VAE-based anomaly detection algorithm with solid theoretical explanation.