 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Voice Conversion with Information Perturbation
Jun 15, 2022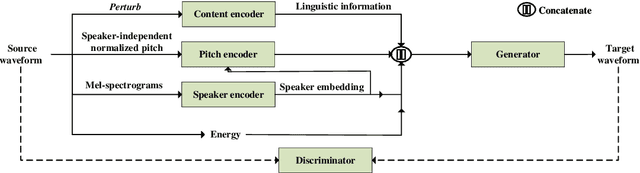
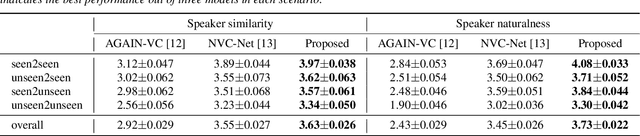
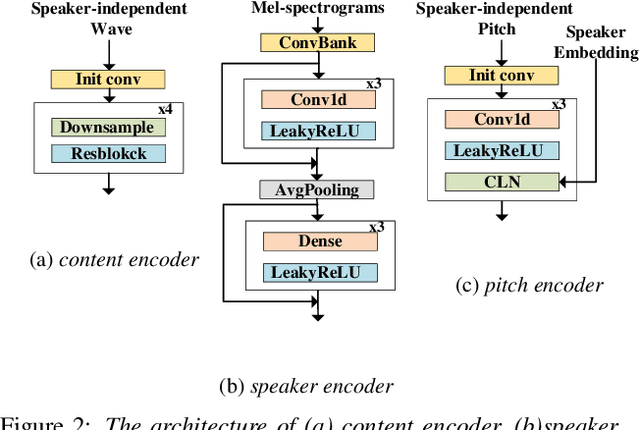
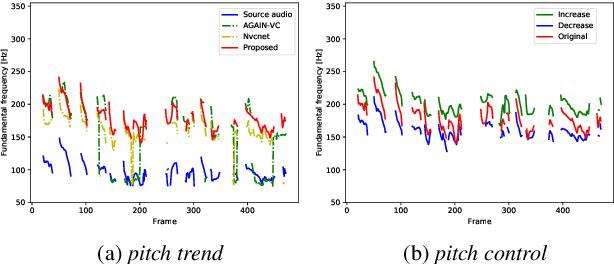
The ideal goal of voice conversion is to convert the source speaker's speech to sound naturally like the target speaker while maintaining the linguistic content and the prosody of the source speech. However, current approaches are insufficient to achieve comprehensive source prosody transfer and target speaker timbre preservation in the converted speech, and the quality of the converted speech is also unsatisfied due to the mismatch between the acoustic model and the vocoder. In this paper, we leverage the recent advances in information perturbation and propose a fully end-to-end approach to conduct high-quality voice conversion. We first adopt information perturbation to remove speaker-related information in the source speech to disentangle speaker timbre and linguistic content and thus the linguistic information is subsequently modeled by a content encoder. To better transfer the prosody of the source speech to the target, we particularly introduce a speaker-related pitch encoder which can maintain the general pitch pattern of the source speaker while flexibly modifying the pitch intensity of the generated speech. Finally, one-shot voice conversion is set up through continuous speaker space modeling. Experimental results indicate that the proposed end-to-end approach significantly outperforms the state-of-the-art models in terms of intelligibility, naturalness, and speaker similarity.
AdaVITS: Tiny VITS for Low Computing Resource Speaker Adaptation
Jun 01, 2022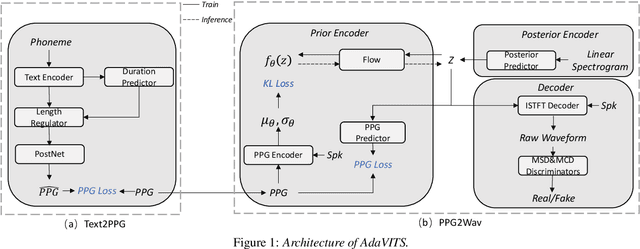

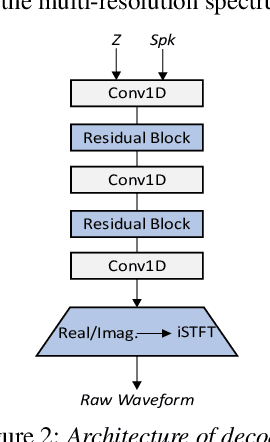
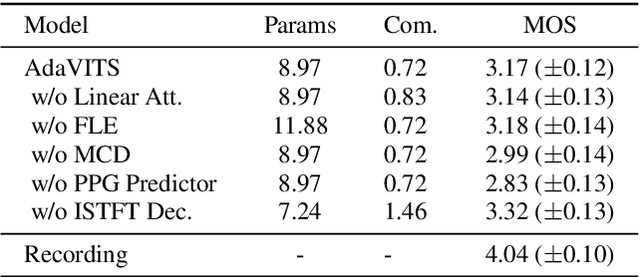
Speaker adaptation in text-to-speech synthesis (TTS) is to finetune a pre-trained TTS model to adapt to new target speakers with limited data. While much effort has been conducted towards this task, seldom work has been performed for low computational resource scenarios due to the challenges raised by the requirement of the lightweight model and less computational complexity. In this paper, a tiny VITS-based TTS model, named AdaVITS, for low computing resource speaker adaptation is proposed. To effectively reduce parameters and computational complexity of VITS, an iSTFT-based wave construction decoder is proposed to replace the upsampling-based decoder which is resource-consuming in the original VITS. Besides, NanoFlow is introduced to share the density estimate across flow blocks to reduce the parameters of the prior encoder. Furthermore, to reduce the computational complexity of the textual encoder, scaled-dot attention is replaced with linear attention. To deal with the instability caused by the simplified model, instead of using the original text encoder, phonetic posteriorgram (PPG) is utilized as linguistic feature via a text-to-PPG module, which is then used as input for the encoder. Experiment shows that AdaVITS can generate stable and natural speech in speaker adaptation with 8.97M model parameters and 0.72GFlops computational complexity.
AiSocrates: Towards Answering Ethical Quandary Questions
May 24, 2022
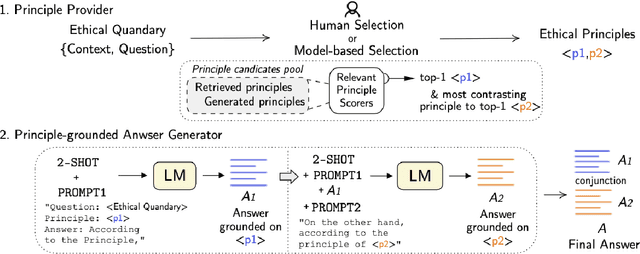


Considerable advancements have been made in various NLP tasks based on the impressive power of large pre-trained language models (LLMs). These results have inspired efforts to understand the limits of LLMs so as to evaluate how far we are from achieving human level general natural language understanding. In this work, we challenge the capability of LLMs with the new task of Ethical Quandary Generative Question Answering. Ethical quandary questions are more challenging to address because multiple conflicting answers may exist to a single quandary. We propose a system, AiSocrates, that provides an answer with a deliberative exchange of different perspectives to an ethical quandary, in the approach of Socratic philosophy, instead of providing a closed answer like an oracle. AiSocrates searches for different ethical principles applicable to the ethical quandary and generates an answer conditioned on the chosen principles through prompt-based few-shot learning. We also address safety concerns by providing a human controllability option in choosing ethical principles. We show that AiSocrates generates promising answers to ethical quandary questions with multiple perspectives, 6.92% more often than answers written by human philosophers by one measure, but the system still needs improvement to match the coherence of human philosophers fully. We argue that AiSocrates is a promising step toward developing an NLP system that incorporates human values explicitly by prompt instructions. We are releasing the code for research purposes.
FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis
Apr 21, 2022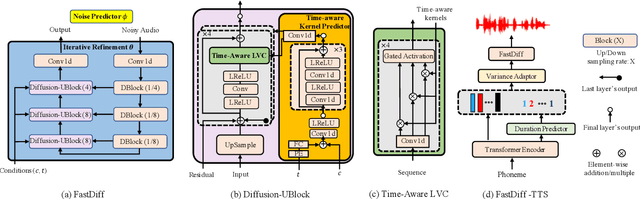
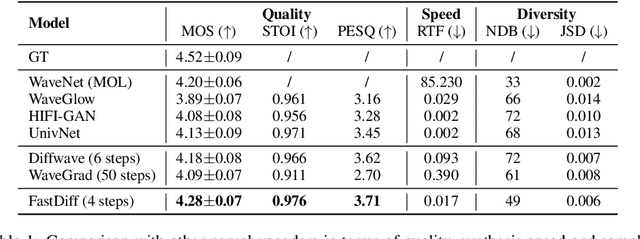
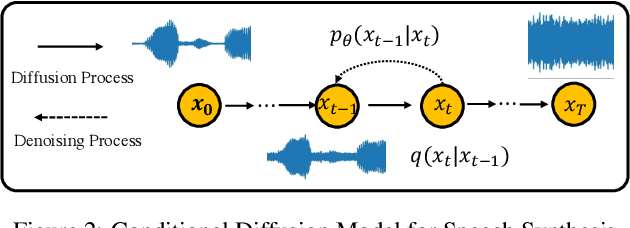

Denoising diffusion probabilistic models (DDPMs) have recently achieved leading performances in many generative tasks. However, the inherited iterative sampling process costs hindered their applications to speech synthesis. This paper proposes FastDiff, a fast conditional diffusion model for high-quality speech synthesis. FastDiff employs a stack of time-aware location-variable convolutions of diverse receptive field patterns to efficiently model long-term time dependencies with adaptive conditions. A noise schedule predictor is also adopted to reduce the sampling steps without sacrificing the generation quality. Based on FastDiff, we design an end-to-end text-to-speech synthesizer, FastDiff-TTS, which generates high-fidelity speech waveforms without any intermediate feature (e.g., Mel-spectrogram). Our evaluation of FastDiff demonstrates the state-of-the-art results with higher-quality (MOS 4.28) speech samples. Also, FastDiff enables a sampling speed of 58x faster than real-time on a V100 GPU, making diffusion models practically applicable to speech synthesis deployment for the first time. We further show that FastDiff generalized well to the mel-spectrogram inversion of unseen speakers, and FastDiff-TTS outperformed other competing methods in end-to-end text-to-speech synthesis. Audio samples are available at \url{https://FastDiff.github.io/}.
3M: Multi-loss, Multi-path and Multi-level Neural Networks for speech recognition
Apr 14, 2022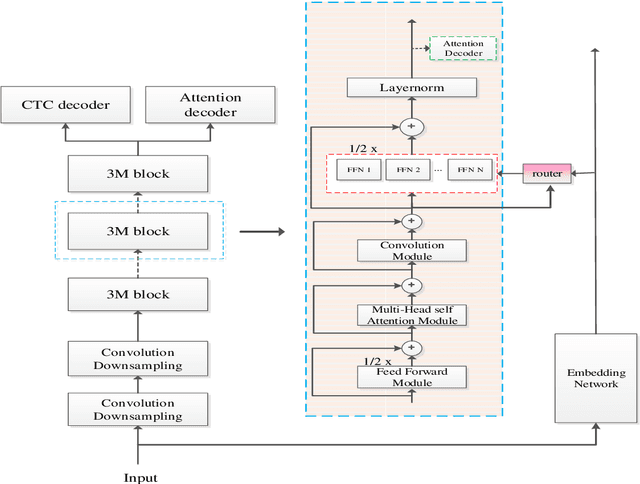
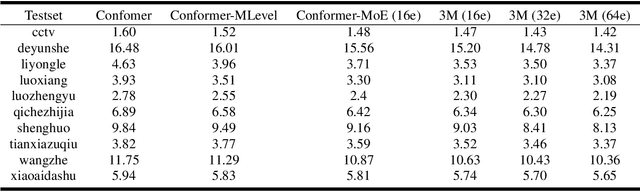
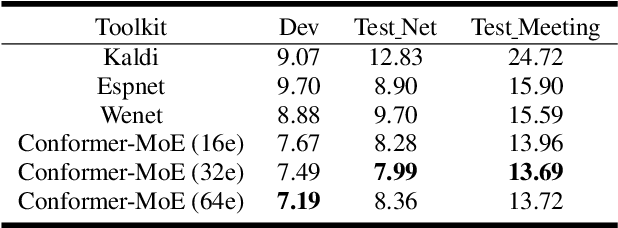
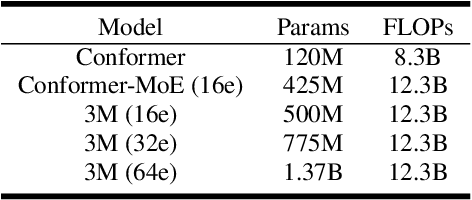
Recently, Conformer based CTC/AED model has become a mainstream architecture for ASR. In this paper, based on our prior work, we identify and integrate several approaches to achieve further improvements for ASR tasks, which we denote as multi-loss, multi-path and multi-level, summarized as "3M" model. Specifically, multi-loss refers to the joint CTC/AED loss and multi-path denotes the Mixture-of-Experts(MoE) architecture which can effectively increase the model capacity without remarkably increasing computation cost. Multi-level means that we introduce auxiliary loss at multiple level of a deep model to help training. We evaluate our proposed method on the public WenetSpeech dataset and experimental results show that the proposed method provides 12.2%-17.6% relative CER improvement over the baseline model trained by Wenet toolkit. On our large scale dataset of 150k hours corpus, the 3M model has also shown obvious superiority over the baseline Conformer model. Code is publicly available at https://github.com/tencent-ailab/3m-asr.
Content-Dependent Fine-Grained Speaker Embedding for Zero-Shot Speaker Adaptation in Text-to-Speech Synthesis
Apr 03, 2022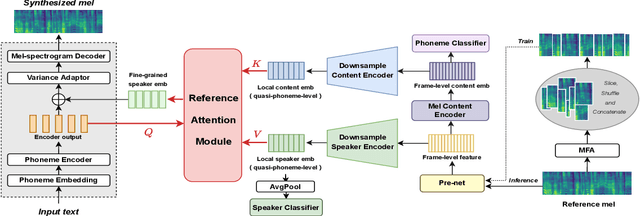
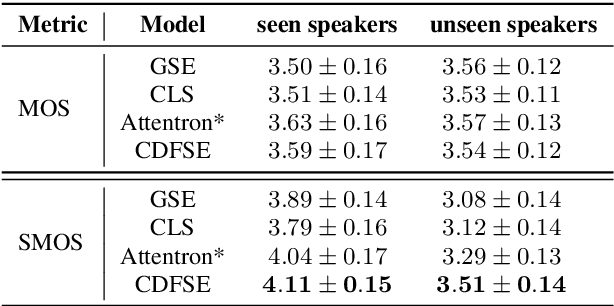
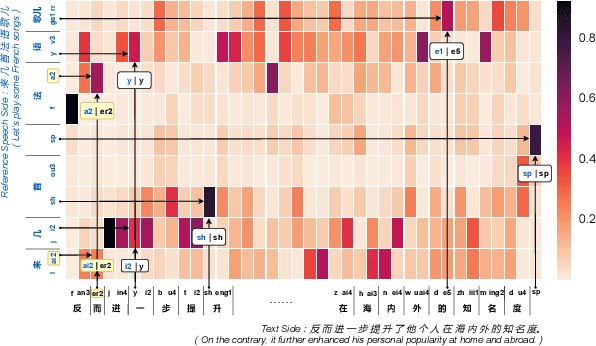
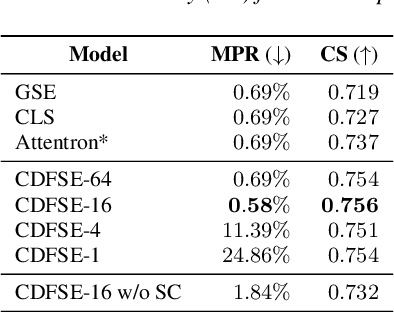
Zero-shot speaker adaptation aims to clone an unseen speaker's voice without any adaptation time and parameters. Previous researches usually use a speaker encoder to extract a global fixed speaker embedding from reference speech, and several attempts have tried variable-length speaker embedding. However, they neglect to transfer the personal pronunciation characteristics related to phoneme content, leading to poor speaker similarity in terms of detailed speaking styles and pronunciation habits. To improve the ability of the speaker encoder to model personal pronunciation characteristics, we propose content-dependent fine-grained speaker embedding for zero-shot speaker adaptation. The corresponding local content embeddings and speaker embeddings are extracted from a reference speech, respectively. Instead of modeling the temporal relations, a reference attention module is introduced to model the content relevance between the reference speech and the input text, and to generate the fine-grained speaker embedding for each phoneme encoder output. The experimental results show that our proposed method can improve speaker similarity of synthesized speeches, especially for unseen speakers.
BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis
Mar 25, 2022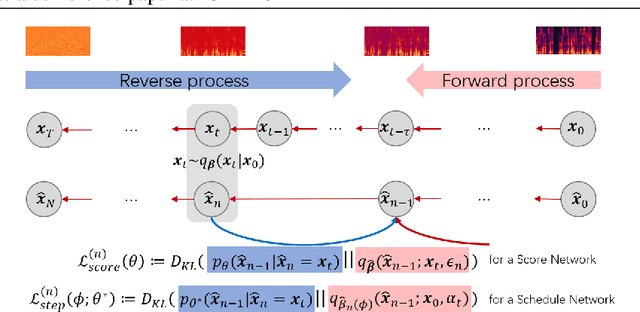
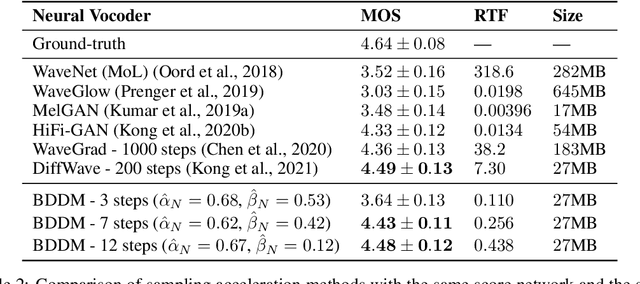
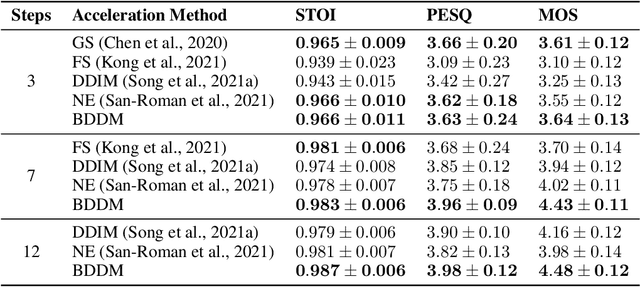
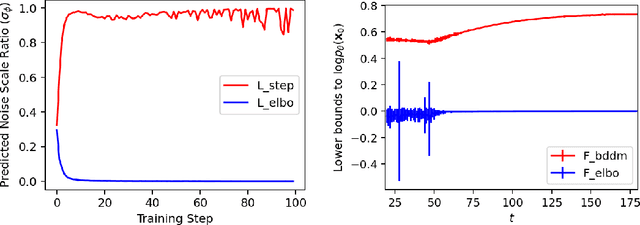
Diffusion probabilistic models (DPMs) and their extensions have emerged as competitive generative models yet confront challenges of efficient sampling. We propose a new bilateral denoising diffusion model (BDDM) that parameterizes both the forward and reverse processes with a schedule network and a score network, which can train with a novel bilateral modeling objective. We show that the new surrogate objective can achieve a lower bound of the log marginal likelihood tighter than a conventional surrogate. We also find that BDDM allows inheriting pre-trained score network parameters from any DPMs and consequently enables speedy and stable learning of the schedule network and optimization of a noise schedule for sampling. Our experiments demonstrate that BDDMs can generate high-fidelity audio samples with as few as three sampling steps. Moreover, compared to other state-of-the-art diffusion-based neural vocoders, BDDMs produce comparable or higher quality samples indistinguishable from human speech, notably with only seven sampling steps (143x faster than WaveGrad and 28.6x faster than DiffWave). We release our code at https://github.com/tencent-ailab/bddm.
* Accepted in ICLR 2022. arXiv admin note: text overlap with arXiv:2108.11514
Read before Generate! Faithful Long Form Question Answering with Machine Reading
Mar 01, 2022
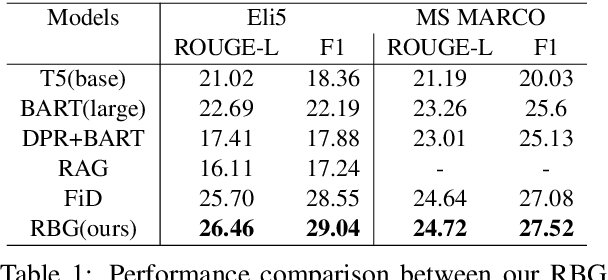
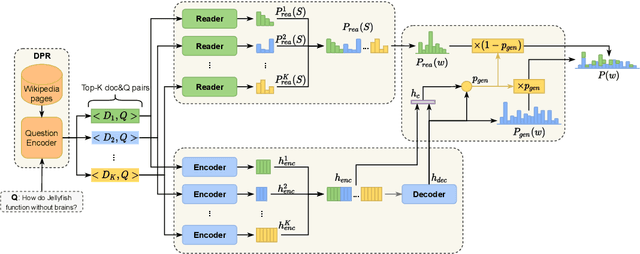
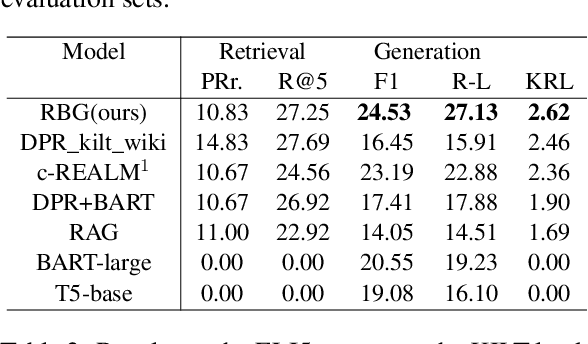
Long-form question answering (LFQA) aims to generate a paragraph-length answer for a given question. While current work on LFQA using large pre-trained model for generation are effective at producing fluent and somewhat relevant content, one primary challenge lies in how to generate a faithful answer that has less hallucinated content. We propose a new end-to-end framework that jointly models answer generation and machine reading. The key idea is to augment the generation model with fine-grained, answer-related salient information which can be viewed as an emphasis on faithful facts. State-of-the-art results on two LFQA datasets, ELI5 and MS MARCO, demonstrate the effectiveness of our method, in comparison with strong baselines on automatic and human evaluation metrics. A detailed analysis further proves the competency of our methods in generating fluent, relevant, and more faithful answers.
VCVTS: Multi-speaker Video-to-Speech synthesis via cross-modal knowledge transfer from voice conversion
Feb 18, 2022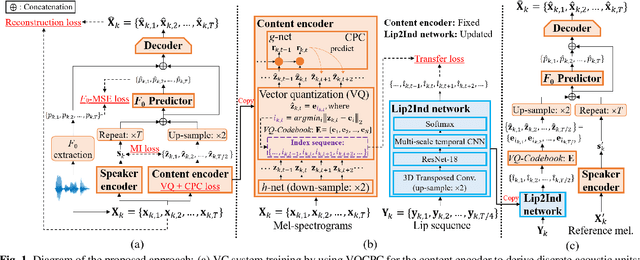
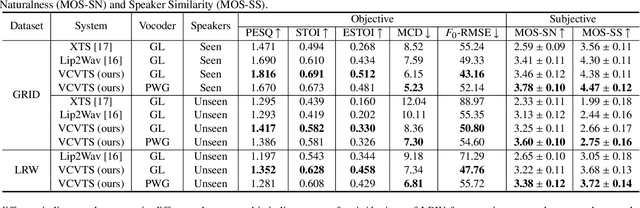
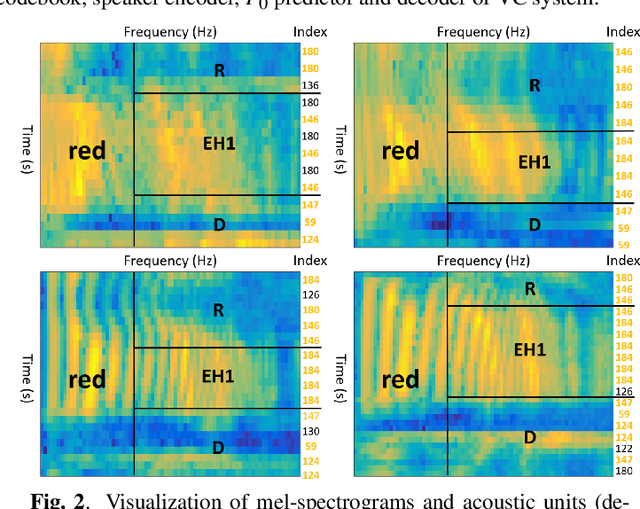
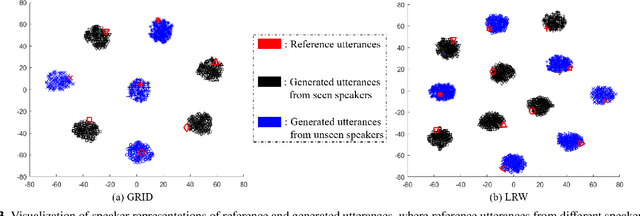
Though significant progress has been made for speaker-dependent Video-to-Speech (VTS) synthesis, little attention is devoted to multi-speaker VTS that can map silent video to speech, while allowing flexible control of speaker identity, all in a single system. This paper proposes a novel multi-speaker VTS system based on cross-modal knowledge transfer from voice conversion (VC), where vector quantization with contrastive predictive coding (VQCPC) is used for the content encoder of VC to derive discrete phoneme-like acoustic units, which are transferred to a Lip-to-Index (Lip2Ind) network to infer the index sequence of acoustic units. The Lip2Ind network can then substitute the content encoder of VC to form a multi-speaker VTS system to convert silent video to acoustic units for reconstructing accurate spoken content. The VTS system also inherits the advantages of VC by using a speaker encoder to produce speaker representations to effectively control the speaker identity of generated speech. Extensive evaluations verify the effectiveness of proposed approach, which can be applied in both constrained vocabulary and open vocabulary conditions, achieving state-of-the-art performance in generating high-quality speech with high naturalness, intelligibility and speaker similarity. Our demo page is released here: https://wendison.github.io/VCVTS-demo/
QA4QG: Using Question Answering to Constrain Multi-Hop Question Generation
Feb 14, 2022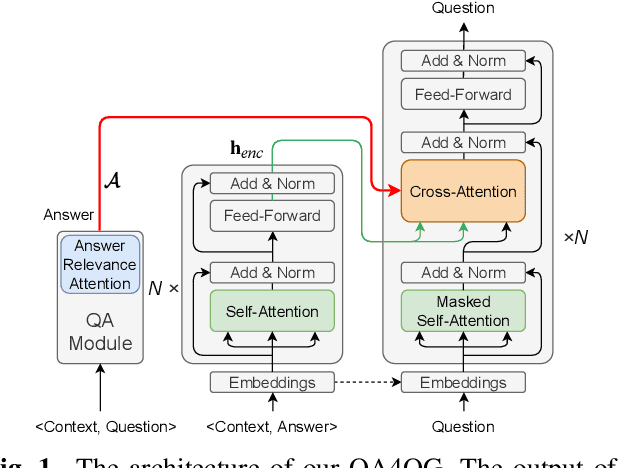
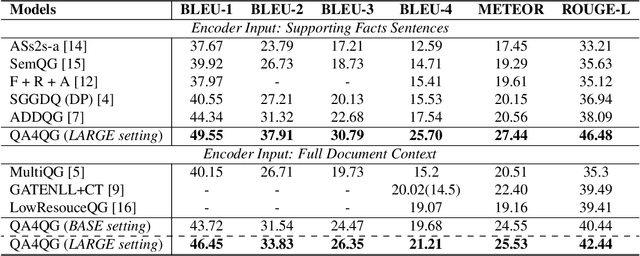
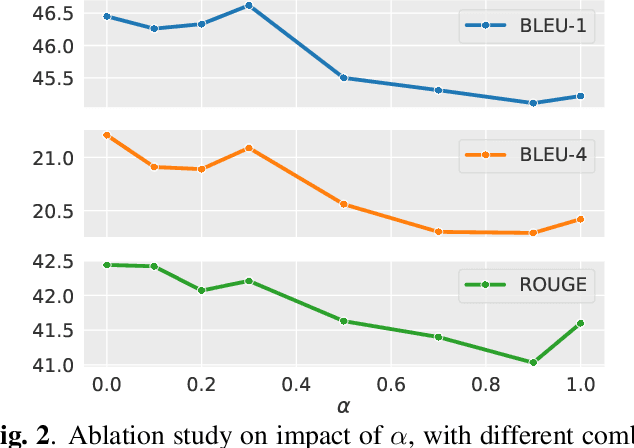
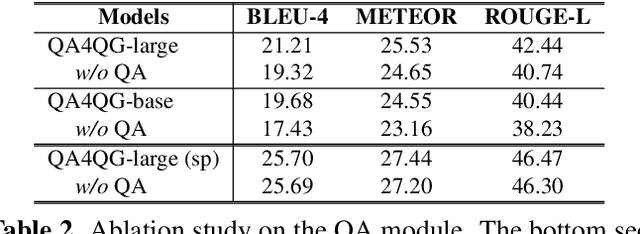
Multi-hop question generation (MQG) aims to generate complex questions which require reasoning over multiple pieces of information of the input passage. Most existing work on MQG has focused on exploring graph-based networks to equip the traditional Sequence-to-sequence framework with reasoning ability. However, these models do not take full advantage of the constraint between questions and answers. Furthermore, studies on multi-hop question answering (QA) suggest that Transformers can replace the graph structure for multi-hop reasoning. Therefore, in this work, we propose a novel framework, QA4QG, a QA-augmented BART-based framework for MQG. It augments the standard BART model with an additional multi-hop QA module to further constrain the generated question. Our results on the HotpotQA dataset show that QA4QG outperforms all state-of-the-art models, with an increase of 8 BLEU-4 and 8 ROUGE points compared to the best results previously reported. Our work suggests the advantage of introducing pre-trained language models and QA module for the MQG task.