 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMade-in China, Thinking in America:U.S. Values Persist in Chinese LLMs
Dec 13, 2025



As large language models increasingly mediate access to information and facilitate decision-making, they are becoming instruments in soft power competitions between global actors such as the United States and China. So far, language models seem to be aligned with the values of Western countries, but evidence for this ethical bias comes mostly from models made by American companies. The current crop of state-of-the-art models includes several made in China, so we conducted the first large-scale investigation of how models made in China and the USA align with people from China and the USA. We elicited responses to the Moral Foundations Questionnaire 2.0 and the World Values Survey from ten Chinese models and ten American models, and we compared their responses to responses from thousands of Chinese and American people. We found that all models respond to both surveys more like American people than like Chinese people. This skew toward American values is only slightly mitigated when prompting the models in Chinese or imposing a Chinese persona on the models. These findings have important implications for a near future in which large language models generate much of the content people consume and shape normative influence in geopolitics.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
High-Dimension Human Value Representation in Large Language Models
Apr 11, 2024



The widespread application of Large Language Models (LLMs) across various tasks and fields has necessitated the alignment of these models with human values and preferences. Given various approaches of human value alignment, ranging from Reinforcement Learning with Human Feedback (RLHF), to constitutional learning, etc. there is an urgent need to understand the scope and nature of human values injected into these models before their release. There is also a need for model alignment without a costly large scale human annotation effort. We propose UniVaR, a high-dimensional representation of human value distributions in LLMs, orthogonal to model architecture and training data. Trained from the value-relevant output of eight multilingual LLMs and tested on the output from four multilingual LLMs, namely LlaMA2, ChatGPT, JAIS and Yi, we show that UniVaR is a powerful tool to compare the distribution of human values embedded in different LLMs with different langauge sources. Through UniVaR, we explore how different LLMs prioritize various values in different languages and cultures, shedding light on the complex interplay between human values and language modeling.
Learn What NOT to Learn: Towards Generative Safety in Chatbots
Apr 25, 2023



Conversational models that are generative and open-domain are particularly susceptible to generating unsafe content since they are trained on web-based social data. Prior approaches to mitigating this issue have drawbacks, such as disrupting the flow of conversation, limited generalization to unseen toxic input contexts, and sacrificing the quality of the dialogue for the sake of safety. In this paper, we present a novel framework, named "LOT" (Learn NOT to), that employs a contrastive loss to enhance generalization by learning from both positive and negative training signals. Our approach differs from the standard contrastive learning framework in that it automatically obtains positive and negative signals from the safe and unsafe language distributions that have been learned beforehand. The LOT framework utilizes divergence to steer the generations away from the unsafe subspace and towards the safe subspace while sustaining the flow of conversation. Our approach is memory and time-efficient during decoding and effectively reduces toxicity while preserving engagingness and fluency. Empirical results indicate that LOT reduces toxicity by up to four-fold while achieving four to six-fold higher rates of engagingness and fluency compared to baseline models. Our findings are further corroborated by human evaluation.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022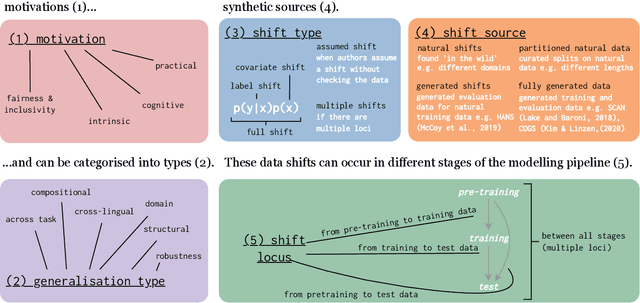
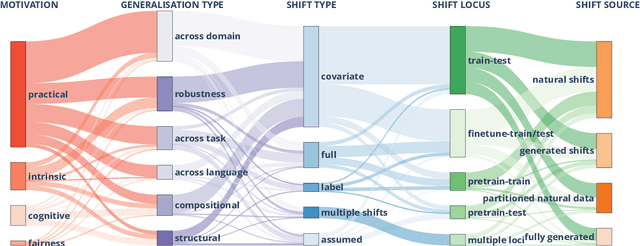
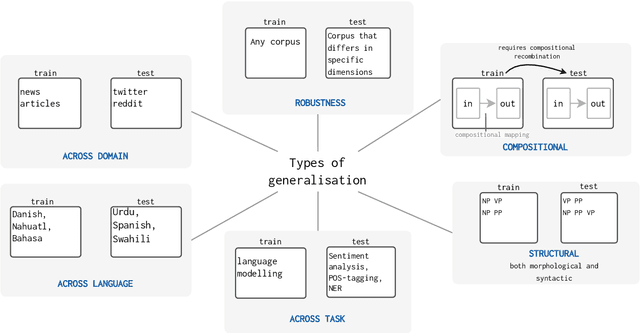

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
AiSocrates: Towards Answering Ethical Quandary Questions
May 24, 2022
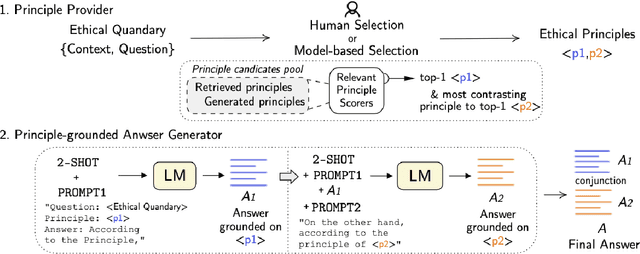


Considerable advancements have been made in various NLP tasks based on the impressive power of large pre-trained language models (LLMs). These results have inspired efforts to understand the limits of LLMs so as to evaluate how far we are from achieving human level general natural language understanding. In this work, we challenge the capability of LLMs with the new task of Ethical Quandary Generative Question Answering. Ethical quandary questions are more challenging to address because multiple conflicting answers may exist to a single quandary. We propose a system, AiSocrates, that provides an answer with a deliberative exchange of different perspectives to an ethical quandary, in the approach of Socratic philosophy, instead of providing a closed answer like an oracle. AiSocrates searches for different ethical principles applicable to the ethical quandary and generates an answer conditioned on the chosen principles through prompt-based few-shot learning. We also address safety concerns by providing a human controllability option in choosing ethical principles. We show that AiSocrates generates promising answers to ethical quandary questions with multiple perspectives, 6.92% more often than answers written by human philosophers by one measure, but the system still needs improvement to match the coherence of human philosophers fully. We argue that AiSocrates is a promising step toward developing an NLP system that incorporates human values explicitly by prompt instructions. We are releasing the code for research purposes.