 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Enhancing User Engagement in Socially-Driven Dialogue through Interactive LLM Alignments
Jun 26, 2025



Enhancing user engagement through interactions plays an essential role in socially-driven dialogues. While prior works have optimized models to reason over relevant knowledge or plan a dialogue act flow, the relationship between user engagement and knowledge or dialogue acts is subtle and does not guarantee user engagement in socially-driven dialogues. To this end, we enable interactive LLMs to learn user engagement by leveraging signals from the future development of conversations. Specifically, we adopt a more direct and relevant indicator of user engagement, i.e., the user's reaction related to dialogue intention after the interaction, as a reward to align interactive LLMs. To achieve this, we develop a user simulator to interact with target interactive LLMs and explore interactions between the user and the interactive LLM system via \textit{i$\times$MCTS} (\textit{M}onte \textit{C}arlo \textit{T}ree \textit{S}earch for \textit{i}nteraction). In this way, we collect a dataset containing pairs of higher and lower-quality experiences using \textit{i$\times$MCTS}, and align interactive LLMs for high-level user engagement by direct preference optimization (DPO) accordingly. Experiments conducted on two socially-driven dialogue scenarios (emotional support conversations and persuasion for good) demonstrate that our method effectively enhances user engagement in interactive LLMs.
Towards Dynamic Theory of Mind: Evaluating LLM Adaptation to Temporal Evolution of Human States
May 23, 2025As Large Language Models (LLMs) increasingly participate in human-AI interactions, evaluating their Theory of Mind (ToM) capabilities - particularly their ability to track dynamic mental states - becomes crucial. While existing benchmarks assess basic ToM abilities, they predominantly focus on static snapshots of mental states, overlooking the temporal evolution that characterizes real-world social interactions. We present \textsc{DynToM}, a novel benchmark specifically designed to evaluate LLMs' ability to understand and track the temporal progression of mental states across interconnected scenarios. Through a systematic four-step framework, we generate 1,100 social contexts encompassing 5,500 scenarios and 78,100 questions, each validated for realism and quality. Our comprehensive evaluation of ten state-of-the-art LLMs reveals that their average performance underperforms humans by 44.7\%, with performance degrading significantly when tracking and reasoning about the shift of mental states. This performance gap highlights fundamental limitations in current LLMs' ability to model the dynamic nature of human mental states.
Towards a Client-Centered Assessment of LLM Therapists by Client Simulation
Jun 18, 2024



Although there is a growing belief that LLMs can be used as therapists, exploring LLMs' capabilities and inefficacy, particularly from the client's perspective, is limited. This work focuses on a client-centered assessment of LLM therapists with the involvement of simulated clients, a standard approach in clinical medical education. However, there are two challenges when applying the approach to assess LLM therapists at scale. Ethically, asking humans to frequently mimic clients and exposing them to potentially harmful LLM outputs can be risky and unsafe. Technically, it can be difficult to consistently compare the performances of different LLM therapists interacting with the same client. To this end, we adopt LLMs to simulate clients and propose ClientCAST, a client-centered approach to assessing LLM therapists by client simulation. Specifically, the simulated client is utilized to interact with LLM therapists and complete questionnaires related to the interaction. Based on the questionnaire results, we assess LLM therapists from three client-centered aspects: session outcome, therapeutic alliance, and self-reported feelings. We conduct experiments to examine the reliability of ClientCAST and use it to evaluate LLMs therapists implemented by Claude-3, GPT-3.5, LLaMA3-70B, and Mixtral 8*7B. Codes are released at https://github.com/wangjs9/ClientCAST.
3D-Speaker-Toolkit: An Open Source Toolkit for Multi-modal Speaker Verification and Diarization
Mar 29, 2024This paper introduces 3D-Speaker-Toolkit, an open source toolkit for multi-modal speaker verification and diarization. It is designed for the needs of academic researchers and industrial practitioners. The 3D-Speaker-Toolkit adeptly leverages the combined strengths of acoustic, semantic, and visual data, seamlessly fusing these modalities to offer robust speaker recognition capabilities. The acoustic module extracts speaker embeddings from acoustic features, employing both fully-supervised and self-supervised learning approaches. The semantic module leverages advanced language models to apprehend the substance and context of spoken language, thereby augmenting the system's proficiency in distinguishing speakers through linguistic patterns. Finally, the visual module applies image processing technologies to scrutinize facial features, which bolsters the precision of speaker diarization in multi-speaker environments. Collectively, these modules empower the 3D-Speaker-Toolkit to attain elevated levels of accuracy and dependability in executing speaker-related tasks, establishing a new benchmark in multi-modal speaker analysis. The 3D-Speaker project also includes a handful of open-sourced state-of-the-art models and a large dataset containing over 10,000 speakers. The toolkit is publicly available at https://github.com/alibaba-damo-academy/3D-Speaker.
Text-Only Domain Adaptation for End-to-End Speech Recognition through Down-Sampling Acoustic Representation
Sep 04, 2023



Mapping two modalities, speech and text, into a shared representation space, is a research topic of using text-only data to improve end-to-end automatic speech recognition (ASR) performance in new domains. However, the length of speech representation and text representation is inconsistent. Although the previous method up-samples the text representation to align with acoustic modality, it may not match the expected actual duration. In this paper, we proposed novel representations match strategy through down-sampling acoustic representation to align with text modality. By introducing a continuous integrate-and-fire (CIF) module generating acoustic representations consistent with token length, our ASR model can learn unified representations from both modalities better, allowing for domain adaptation using text-only data of the target domain. Experiment results of new domain data demonstrate the effectiveness of the proposed method.
SememeASR: Boosting Performance of End-to-End Speech Recognition against Domain and Long-Tailed Data Shift with Sememe Semantic Knowledge
Sep 04, 2023



Recently, excellent progress has been made in speech recognition. However, pure data-driven approaches have struggled to solve the problem in domain-mismatch and long-tailed data. Considering that knowledge-driven approaches can help data-driven approaches alleviate their flaws, we introduce sememe-based semantic knowledge information to speech recognition (SememeASR). Sememe, according to the linguistic definition, is the minimum semantic unit in a language and is able to represent the implicit semantic information behind each word very well. Our experiments show that the introduction of sememe information can improve the effectiveness of speech recognition. In addition, our further experiments show that sememe knowledge can improve the model's recognition of long-tailed data and enhance the model's domain generalization ability.
Improving Mandarin Prosodic Structure Prediction with Multi-level Contextual Information
Aug 31, 2023



For text-to-speech (TTS) synthesis, prosodic structure prediction (PSP) plays an important role in producing natural and intelligible speech. Although inter-utterance linguistic information can influence the speech interpretation of the target utterance, previous works on PSP mainly focus on utilizing intrautterance linguistic information of the current utterance only. This work proposes to use inter-utterance linguistic information to improve the performance of PSP. Multi-level contextual information, which includes both inter-utterance and intrautterance linguistic information, is extracted by a hierarchical encoder from character level, utterance level and discourse level of the input text. Then a multi-task learning (MTL) decoder predicts prosodic boundaries from multi-level contextual information. Objective evaluation results on two datasets show that our method achieves better F1 scores in predicting prosodic word (PW), prosodic phrase (PPH) and intonational phrase (IPH). It demonstrates the effectiveness of using multi-level contextual information for PSP. Subjective preference tests also indicate the naturalness of synthesized speeches are improved.
Towards Cross-speaker Reading Style Transfer on Audiobook Dataset
Aug 19, 2022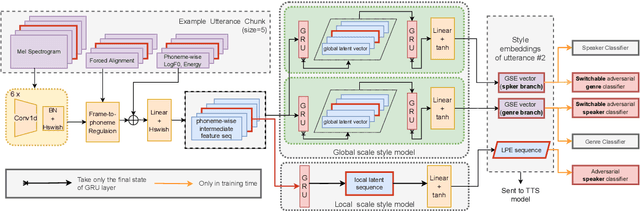
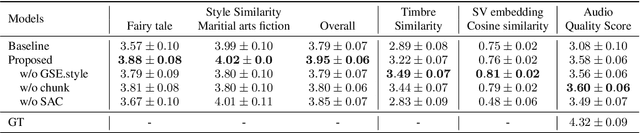
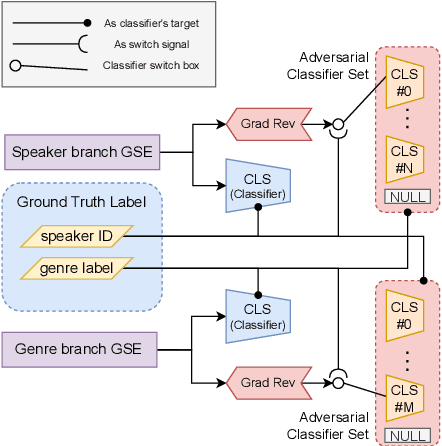
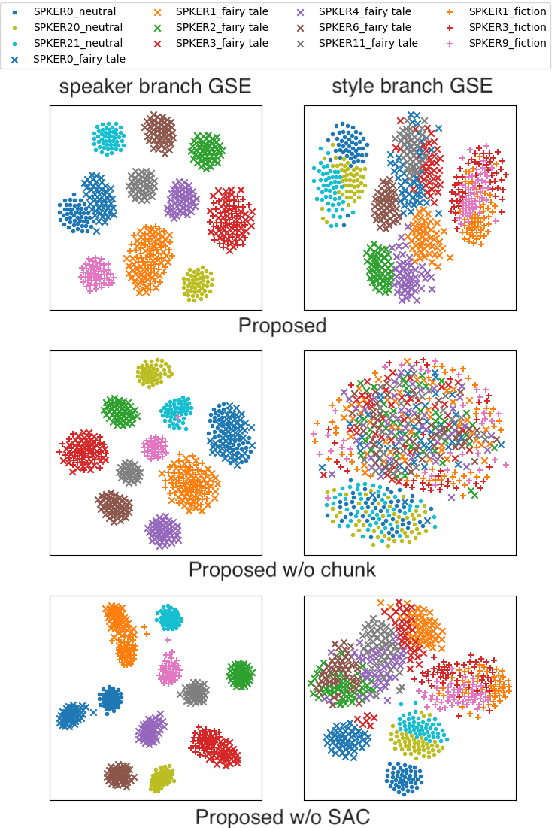
Cross-speaker style transfer aims to extract the speech style of the given reference speech, which can be reproduced in the timbre of arbitrary target speakers. Existing methods on this topic have explored utilizing utterance-level style labels to perform style transfer via either global or local scale style representations. However, audiobook datasets are typically characterized by both the local prosody and global genre, and are rarely accompanied by utterance-level style labels. Thus, properly transferring the reading style across different speakers remains a challenging task. This paper aims to introduce a chunk-wise multi-scale cross-speaker style model to capture both the global genre and the local prosody in audiobook speeches. Moreover, by disentangling speaker timbre and style with the proposed switchable adversarial classifiers, the extracted reading style is made adaptable to the timbre of different speakers. Experiment results confirm that the model manages to transfer a given reading style to new target speakers. With the support of local prosody and global genre type predictor, the potentiality of the proposed method in multi-speaker audiobook generation is further revealed.
Content-Dependent Fine-Grained Speaker Embedding for Zero-Shot Speaker Adaptation in Text-to-Speech Synthesis
Apr 03, 2022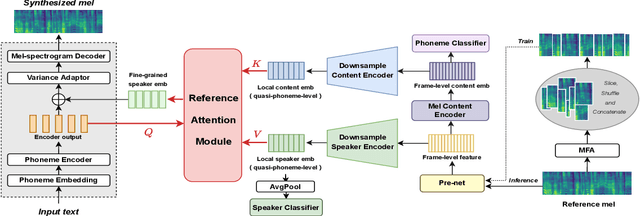
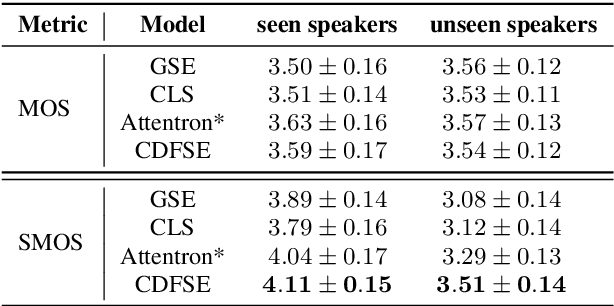
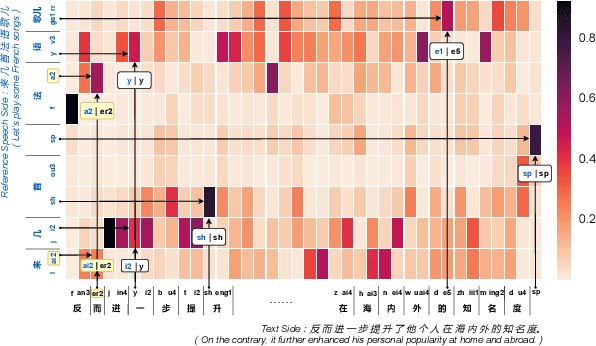
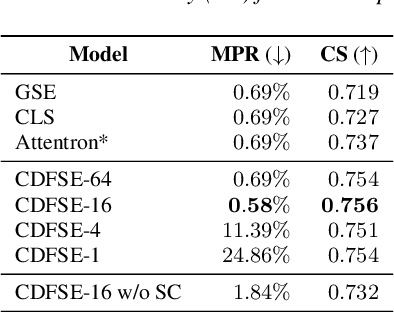
Zero-shot speaker adaptation aims to clone an unseen speaker's voice without any adaptation time and parameters. Previous researches usually use a speaker encoder to extract a global fixed speaker embedding from reference speech, and several attempts have tried variable-length speaker embedding. However, they neglect to transfer the personal pronunciation characteristics related to phoneme content, leading to poor speaker similarity in terms of detailed speaking styles and pronunciation habits. To improve the ability of the speaker encoder to model personal pronunciation characteristics, we propose content-dependent fine-grained speaker embedding for zero-shot speaker adaptation. The corresponding local content embeddings and speaker embeddings are extracted from a reference speech, respectively. Instead of modeling the temporal relations, a reference attention module is introduced to model the content relevance between the reference speech and the input text, and to generate the fine-grained speaker embedding for each phoneme encoder output. The experimental results show that our proposed method can improve speaker similarity of synthesized speeches, especially for unseen speakers.