 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Audio-Visual Features with Pretrained AV-HuBERT for Multi-Modal Dysarthric Speech Reconstruction
Jan 31, 2024



Dysarthric speech reconstruction (DSR) aims to transform dysarthric speech into normal speech by improving the intelligibility and naturalness. This is a challenging task especially for patients with severe dysarthria and speaking in complex, noisy acoustic environments. To address these challenges, we propose a novel multi-modal framework to utilize visual information, e.g., lip movements, in DSR as extra clues for reconstructing the highly abnormal pronunciations. The multi-modal framework consists of: (i) a multi-modal encoder to extract robust phoneme embeddings from dysarthric speech with auxiliary visual features; (ii) a variance adaptor to infer the normal phoneme duration and pitch contour from the extracted phoneme embeddings; (iii) a speaker encoder to encode the speaker's voice characteristics; and (iv) a mel-decoder to generate the reconstructed mel-spectrogram based on the extracted phoneme embeddings, prosodic features and speaker embeddings. Both objective and subjective evaluations conducted on the commonly used UASpeech corpus show that our proposed approach can achieve significant improvements over baseline systems in terms of speech intelligibility and naturalness, especially for the speakers with more severe symptoms. Compared with original dysarthric speech, the reconstructed speech achieves 42.1\% absolute word error rate reduction for patients with more severe dysarthria levels.
UNIT-DSR: Dysarthric Speech Reconstruction System Using Speech Unit Normalization
Jan 26, 2024



Dysarthric speech reconstruction (DSR) systems aim to automatically convert dysarthric speech into normal-sounding speech. The technology eases communication with speakers affected by the neuromotor disorder and enhances their social inclusion. NED-based (Neural Encoder-Decoder) systems have significantly improved the intelligibility of the reconstructed speech as compared with GAN-based (Generative Adversarial Network) approaches, but the approach is still limited by training inefficiency caused by the cascaded pipeline and auxiliary tasks of the content encoder, which may in turn affect the quality of reconstruction. Inspired by self-supervised speech representation learning and discrete speech units, we propose a Unit-DSR system, which harnesses the powerful domain-adaptation capacity of HuBERT for training efficiency improvement and utilizes speech units to constrain the dysarthric content restoration in a discrete linguistic space. Compared with NED approaches, the Unit-DSR system only consists of a speech unit normalizer and a Unit HiFi-GAN vocoder, which is considerably simpler without cascaded sub-modules or auxiliary tasks. Results on the UASpeech corpus indicate that Unit-DSR outperforms competitive baselines in terms of content restoration, reaching a 28.2% relative average word error rate reduction when compared to original dysarthric speech, and shows robustness against speed perturbation and noise.
Disentangled Speech Representation Learning for One-Shot Cross-lingual Voice Conversion Using $β$-VAE
Oct 25, 2022



We propose an unsupervised learning method to disentangle speech into content representation and speaker identity representation. We apply this method to the challenging one-shot cross-lingual voice conversion task to demonstrate the effectiveness of the disentanglement. Inspired by $\beta$-VAE, we introduce a learning objective that balances between the information captured by the content and speaker representations. In addition, the inductive biases from the architectural design and the training dataset further encourage the desired disentanglement. Both objective and subjective evaluations show the effectiveness of the proposed method in speech disentanglement and in one-shot cross-lingual voice conversion.
Speaker Identity Preservation in Dysarthric Speech Reconstruction by Adversarial Speaker Adaptation
Feb 18, 2022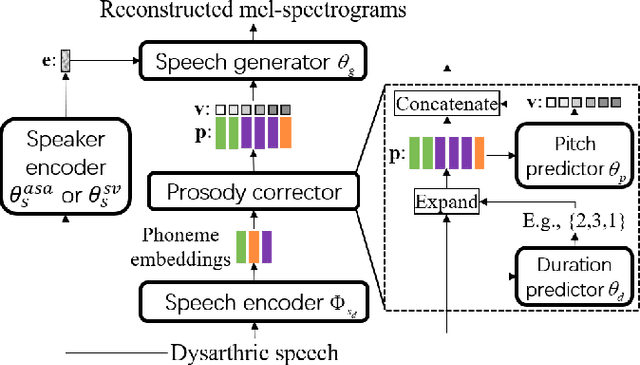
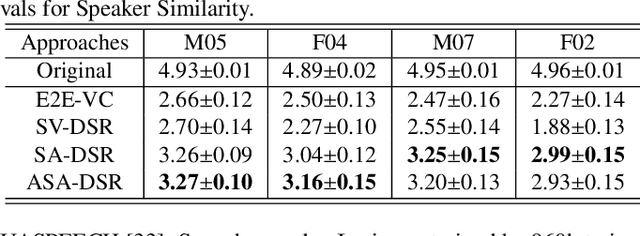
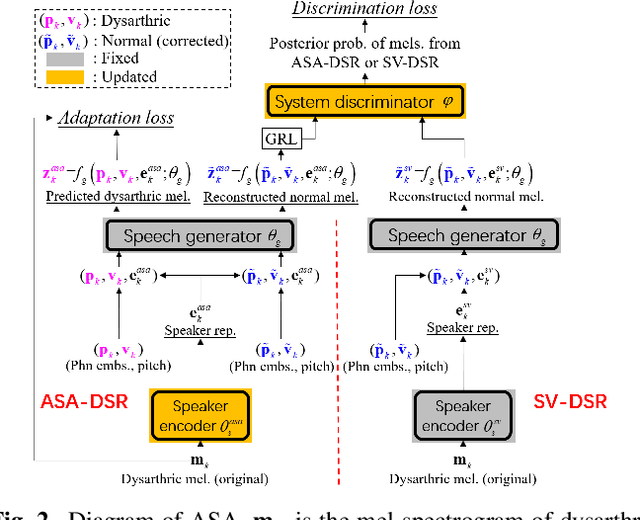
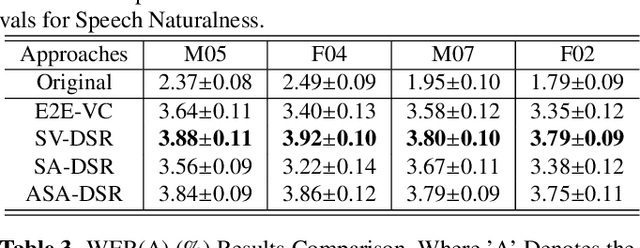
Dysarthric speech reconstruction (DSR), which aims to improve the quality of dysarthric speech, remains a challenge, not only because we need to restore the speech to be normal, but also must preserve the speaker's identity. The speaker representation extracted by the speaker encoder (SE) optimized for speaker verification has been explored to control the speaker identity. However, the SE may not be able to fully capture the characteristics of dysarthric speakers that are previously unseen. To address this research problem, we propose a novel multi-task learning strategy, i.e., adversarial speaker adaptation (ASA). The primary task of ASA fine-tunes the SE with the speech of the target dysarthric speaker to effectively capture identity-related information, and the secondary task applies adversarial training to avoid the incorporation of abnormal speaking patterns into the reconstructed speech, by regularizing the distribution of reconstructed speech to be close to that of reference speech with high quality. Experiments show that the proposed approach can achieve enhanced speaker similarity and comparable speech naturalness with a strong baseline approach. Compared with dysarthric speech, the reconstructed speech achieves 22.3% and 31.5% absolute word error rate reduction for speakers with moderate and moderate-severe dysarthria respectively. Our demo page is released here: https://wendison.github.io/ASA-DSR-demo/
VCVTS: Multi-speaker Video-to-Speech synthesis via cross-modal knowledge transfer from voice conversion
Feb 18, 2022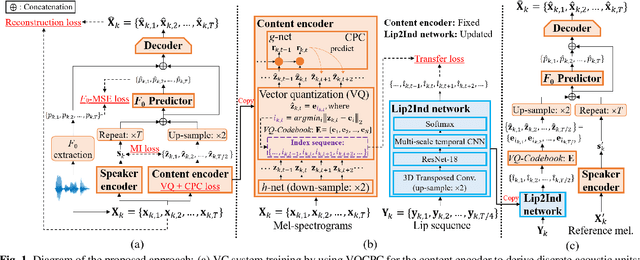
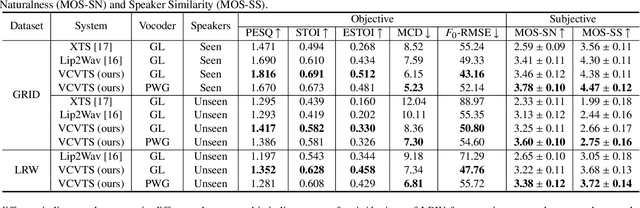
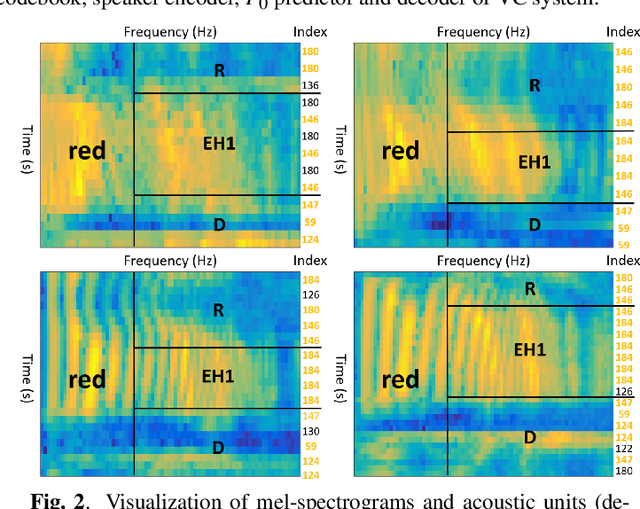
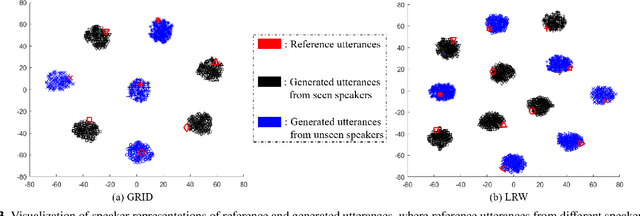
Though significant progress has been made for speaker-dependent Video-to-Speech (VTS) synthesis, little attention is devoted to multi-speaker VTS that can map silent video to speech, while allowing flexible control of speaker identity, all in a single system. This paper proposes a novel multi-speaker VTS system based on cross-modal knowledge transfer from voice conversion (VC), where vector quantization with contrastive predictive coding (VQCPC) is used for the content encoder of VC to derive discrete phoneme-like acoustic units, which are transferred to a Lip-to-Index (Lip2Ind) network to infer the index sequence of acoustic units. The Lip2Ind network can then substitute the content encoder of VC to form a multi-speaker VTS system to convert silent video to acoustic units for reconstructing accurate spoken content. The VTS system also inherits the advantages of VC by using a speaker encoder to produce speaker representations to effectively control the speaker identity of generated speech. Extensive evaluations verify the effectiveness of proposed approach, which can be applied in both constrained vocabulary and open vocabulary conditions, achieving state-of-the-art performance in generating high-quality speech with high naturalness, intelligibility and speaker similarity. Our demo page is released here: https://wendison.github.io/VCVTS-demo/
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
Jun 18, 2021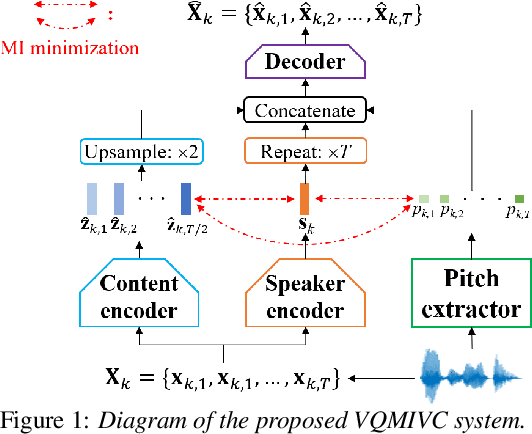
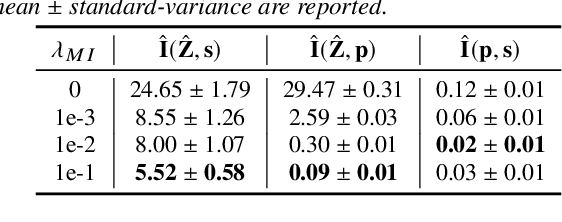
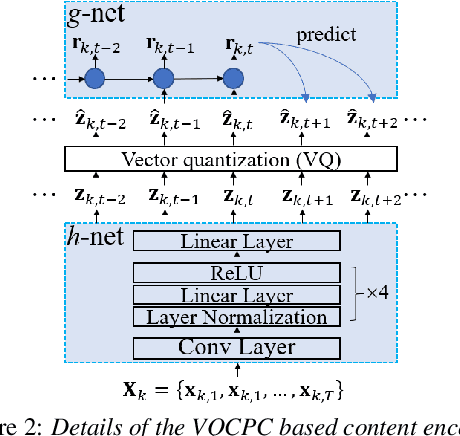
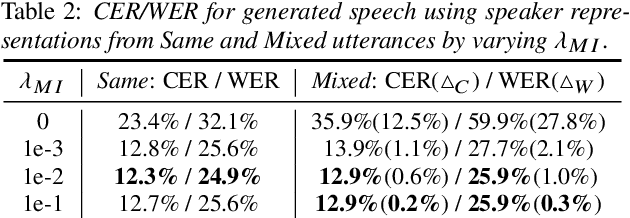
One-shot voice conversion (VC), which performs conversion across arbitrary speakers with only a single target-speaker utterance for reference, can be effectively achieved by speech representation disentanglement. Existing work generally ignores the correlation between different speech representations during training, which causes leakage of content information into the speaker representation and thus degrades VC performance. To alleviate this issue, we employ vector quantization (VQ) for content encoding and introduce mutual information (MI) as the correlation metric during training, to achieve proper disentanglement of content, speaker and pitch representations, by reducing their inter-dependencies in an unsupervised manner. Experimental results reflect the superiority of the proposed method in learning effective disentangled speech representations for retaining source linguistic content and intonation variations, while capturing target speaker characteristics. In doing so, the proposed approach achieves higher speech naturalness and speaker similarity than current state-of-the-art one-shot VC systems. Our code, pre-trained models and demo are available at https://github.com/Wendison/VQMIVC.
Unsupervised Domain Adaptation for Dysarthric Speech Detection via Domain Adversarial Training and Mutual Information Minimization
Jun 18, 2021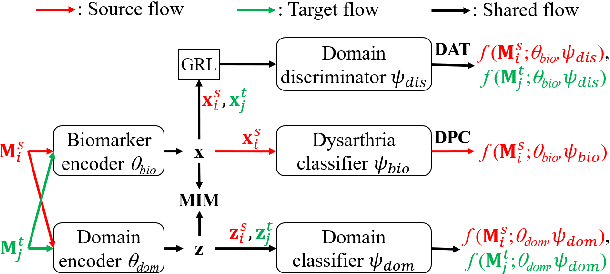

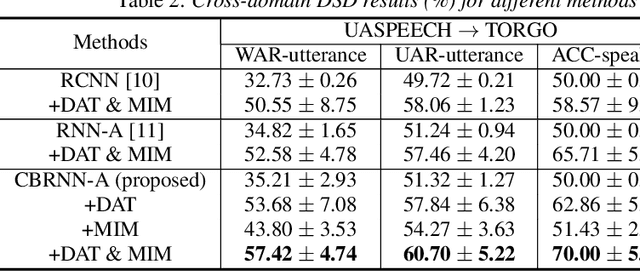
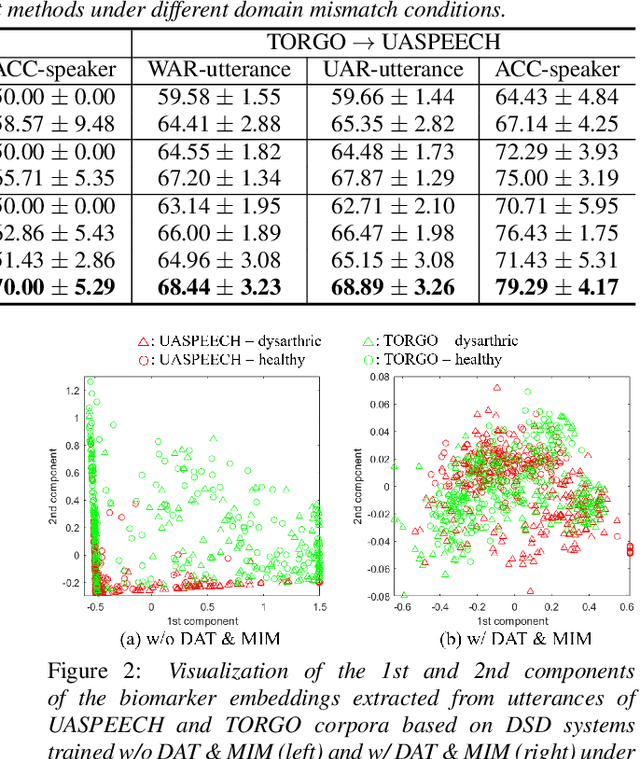
Dysarthric speech detection (DSD) systems aim to detect characteristics of the neuromotor disorder from speech. Such systems are particularly susceptible to domain mismatch where the training and testing data come from the source and target domains respectively, but the two domains may differ in terms of speech stimuli, disease etiology, etc. It is hard to acquire labelled data in the target domain, due to high costs of annotating sizeable datasets. This paper makes a first attempt to formulate cross-domain DSD as an unsupervised domain adaptation (UDA) problem. We use labelled source-domain data and unlabelled target-domain data, and propose a multi-task learning strategy, including dysarthria presence classification (DPC), domain adversarial training (DAT) and mutual information minimization (MIM), which aim to learn dysarthria-discriminative and domain-invariant biomarker embeddings. Specifically, DPC helps biomarker embeddings capture critical indicators of dysarthria; DAT forces biomarker embeddings to be indistinguishable in source and target domains; and MIM further reduces the correlation between biomarker embeddings and domain-related cues. By treating the UASPEECH and TORGO corpora respectively as the source and target domains, experiments show that the incorporation of UDA attains absolute increases of 22.2% and 20.0% respectively in utterance-level weighted average recall and speaker-level accuracy.
Any-to-Many Voice Conversion with Location-Relative Sequence-to-Sequence Modeling
Sep 06, 2020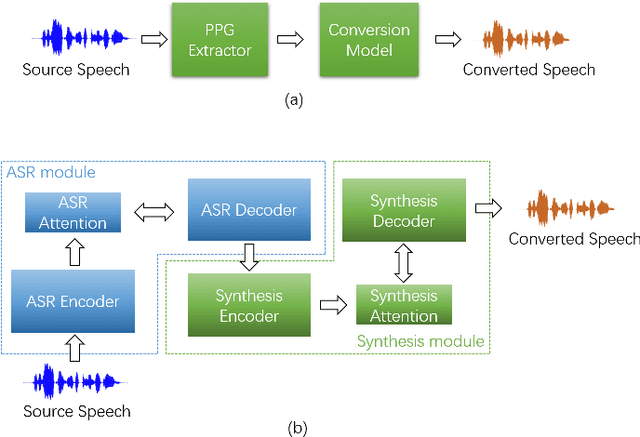
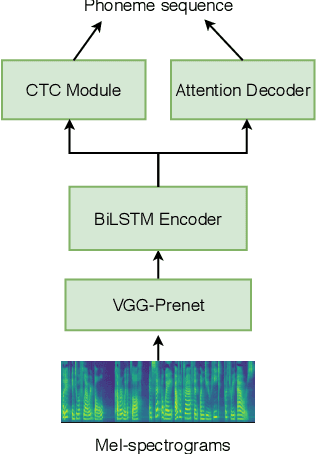
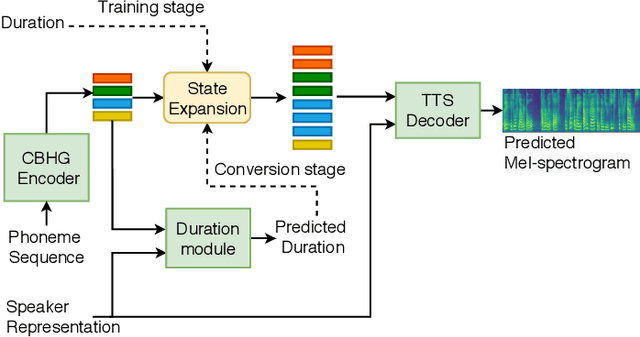
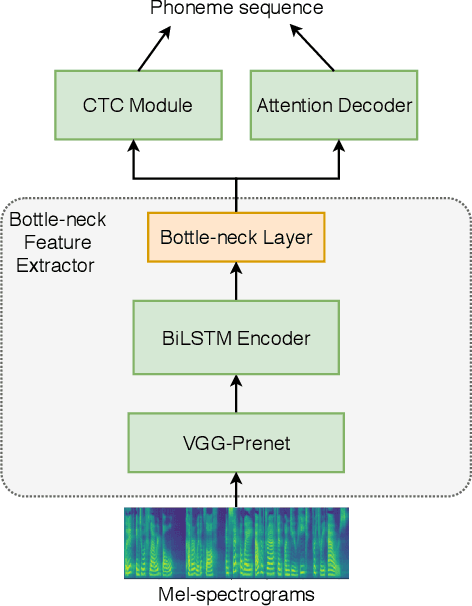
This paper proposes an any-to-many location-relative, sequence-to-sequence (seq2seq) based, non-parallel voice conversion approach. In this approach, we combine a bottle-neck feature extractor (BNE) with a seq2seq based synthesis module. During the training stage, an encoder-decoder based hybrid connectionist-temporal-classification-attention (CTC-attention) phoneme recognizer is trained, whose encoder has a bottle-neck layer. A BNE is obtained from the phoneme recognizer and is utilized to extract speaker-independent, dense and rich linguistic representations from spectral features. Then a multi-speaker location-relative attention based seq2seq synthesis model is trained to reconstruct spectral features from the bottle-neck features, conditioning on speaker representations for speaker identity control in the generated speech. To mitigate the difficulties of using seq2seq based models to align long sequences, we down-sample the input spectral feature along the temporal dimension and equip the synthesis model with a discretized mixture of logistic (MoL) attention mechanism. Since the phoneme recognizer is trained with large speech recognition data corpus, the proposed approach can conduct any-to-many voice conversion. Objective and subjective evaluations shows that the proposed any-to-many approach has superior voice conversion performance in terms of both naturalness and speaker similarity. Ablation studies are conducted to confirm the effectiveness of feature selection and model design strategies in the proposed approach. The proposed VC approach can readily be extended to support any-to-any VC (also known as one/few-shot VC), and achieve high performance according to objective and subjective evaluations.