 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Multimodal Large Language Model Capabilities and Modalities via Model Merging
May 26, 2025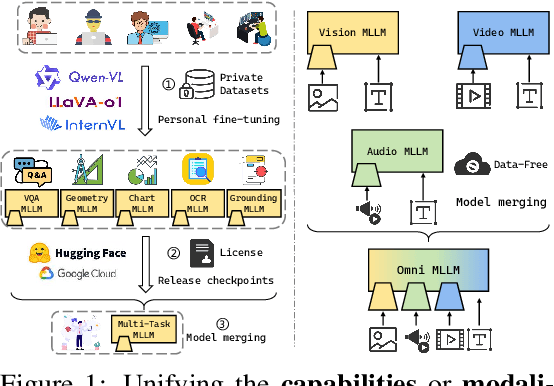

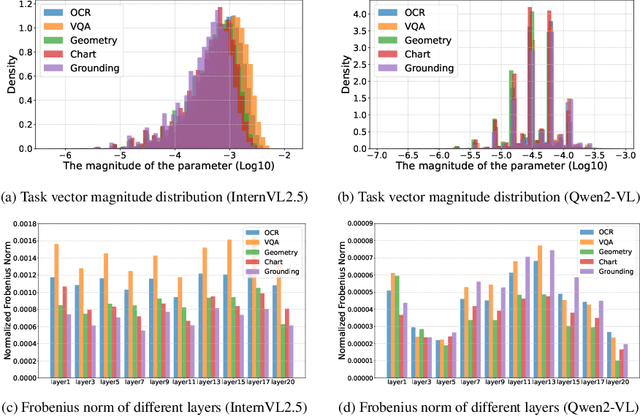
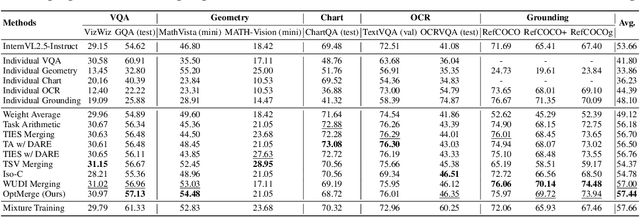
While foundation models update slowly due to resource-intensive training requirements, domain-specific models evolve between updates. Model merging aims to combine multiple expert models into a single, more capable model, thereby reducing storage and serving costs while supporting decentralized model development. Despite its potential, previous studies have primarily focused on merging visual classification models or Large Language Models (LLMs) for code and math tasks. Multimodal Large Language Models (MLLMs), which extend the capabilities of LLMs through large-scale multimodal training, have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, (i) we introduce the model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, providing both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-language models), moving toward the Omni-language model. (ii) We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. (iii) We find that model merging offers a promising way for building improved MLLMs without requiring data training. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.
Multimodal Reasoning Agent for Zero-Shot Composed Image Retrieval
May 26, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve target images given a compositional query, consisting of a reference image and a modifying text-without relying on annotated training data. Existing approaches often generate a synthetic target text using large language models (LLMs) to serve as an intermediate anchor between the compositional query and the target image. Models are then trained to align the compositional query with the generated text, and separately align images with their corresponding texts using contrastive learning. However, this reliance on intermediate text introduces error propagation, as inaccuracies in query-to-text and text-to-image mappings accumulate, ultimately degrading retrieval performance. To address these problems, we propose a novel framework by employing a Multimodal Reasoning Agent (MRA) for ZS-CIR. MRA eliminates the dependence on textual intermediaries by directly constructing triplets, <reference image, modification text, target image>, using only unlabeled image data. By training on these synthetic triplets, our model learns to capture the relationships between compositional queries and candidate images directly. Extensive experiments on three standard CIR benchmarks demonstrate the effectiveness of our approach. On the FashionIQ dataset, our method improves Average R@10 by at least 7.5\% over existing baselines; on CIRR, it boosts R@1 by 9.6\%; and on CIRCO, it increases mAP@5 by 9.5\%.
SeRL: Self-Play Reinforcement Learning for Large Language Models with Limited Data
May 25, 2025



Recent advances have demonstrated the effectiveness of Reinforcement Learning (RL) in improving the reasoning capabilities of Large Language Models (LLMs). However, existing works inevitably rely on high-quality instructions and verifiable rewards for effective training, both of which are often difficult to obtain in specialized domains. In this paper, we propose Self-play Reinforcement Learning(SeRL) to bootstrap LLM training with limited initial data. Specifically, SeRL comprises two complementary modules: self-instruction and self-rewarding. The former module generates additional instructions based on the available data at each training step, employing robust online filtering strategies to ensure instruction quality, diversity, and difficulty. The latter module introduces a simple yet effective majority-voting mechanism to estimate response rewards for additional instructions, eliminating the need for external annotations. Finally, SeRL performs conventional RL based on the generated data, facilitating iterative self-play learning. Extensive experiments on various reasoning benchmarks and across different LLM backbones demonstrate that the proposed SeRL yields results superior to its counterparts and achieves performance on par with those obtained by high-quality data with verifiable rewards. Our code is available at https://github.com/wantbook-book/SeRL.
VORTA: Efficient Video Diffusion via Routing Sparse Attention
May 24, 2025



Video Diffusion Transformers (VDiTs) have achieved remarkable progress in high-quality video generation, but remain computationally expensive due to the quadratic complexity of attention over high-dimensional video sequences. Recent attention acceleration methods leverage the sparsity of attention patterns to improve efficiency; however, they often overlook inefficiencies of redundant long-range interactions. To address this problem, we propose \textbf{VORTA}, an acceleration framework with two novel components: 1) a sparse attention mechanism that efficiently captures long-range dependencies, and 2) a routing strategy that adaptively replaces full 3D attention with specialized sparse attention variants throughout the sampling process. It achieves a $1.76\times$ end-to-end speedup without quality loss on VBench. Furthermore, VORTA can seamlessly integrate with various other acceleration methods, such as caching and step distillation, reaching up to $14.41\times$ speedup with negligible performance degradation. VORTA demonstrates its efficiency and enhances the practicality of VDiTs in real-world settings.
MLLMs are Deeply Affected by Modality Bias
May 24, 2025



Recent advances in Multimodal Large Language Models (MLLMs) have shown promising results in integrating diverse modalities such as texts and images. MLLMs are heavily influenced by modality bias, often relying on language while under-utilizing other modalities like visual inputs. This position paper argues that MLLMs are deeply affected by modality bias. Firstly, we diagnose the current state of modality bias, highlighting its manifestations across various tasks. Secondly, we propose a systematic research road-map related to modality bias in MLLMs. Thirdly, we identify key factors of modality bias in MLLMs and offer actionable suggestions for future research to mitigate it. To substantiate these findings, we conduct experiments that demonstrate the influence of each factor: 1. Data Characteristics: Language data is compact and abstract, while visual data is redundant and complex, creating an inherent imbalance in learning dynamics. 2. Imbalanced Backbone Capabilities: The dominance of pretrained language models in MLLMs leads to overreliance on language and neglect of visual information. 3. Training Objectives: Current objectives often fail to promote balanced cross-modal alignment, resulting in shortcut learning biased toward language. These findings highlight the need for balanced training strategies and model architectures to better integrate multiple modalities in MLLMs. We call for interdisciplinary efforts to tackle these challenges and drive innovation in MLLM research. Our work provides a fresh perspective on modality bias in MLLMs and offers insights for developing more robust and generalizable multimodal systems-advancing progress toward Artificial General Intelligence.
Runaway is Ashamed, But Helpful: On the Early-Exit Behavior of Large Language Model-based Agents in Embodied Environments
May 23, 2025Agents powered by large language models (LLMs) have demonstrated strong planning and decision-making capabilities in complex embodied environments. However, such agents often suffer from inefficiencies in multi-turn interactions, frequently trapped in repetitive loops or issuing ineffective commands, leading to redundant computational overhead. Instead of relying solely on learning from trajectories, we take a first step toward exploring the early-exit behavior for LLM-based agents. We propose two complementary approaches: 1. an $\textbf{intrinsic}$ method that injects exit instructions during generation, and 2. an $\textbf{extrinsic}$ method that verifies task completion to determine when to halt an agent's trial. To evaluate early-exit mechanisms, we introduce two metrics: one measures the reduction of $\textbf{redundant steps}$ as a positive effect, and the other evaluates $\textbf{progress degradation}$ as a negative effect. Experiments with 4 different LLMs across 5 embodied environments show significant efficiency improvements, with only minor drops in agent performance. We also validate a practical strategy where a stronger agent assists after an early-exit agent, achieving better performance with the same total steps. We will release our code to support further research.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
R1-Compress: Long Chain-of-Thought Compression via Chunk Compression and Search
May 22, 2025Chain-of-Thought (CoT) reasoning enhances large language models (LLMs) by enabling step-by-step problem-solving, yet its extension to Long-CoT introduces substantial computational overhead due to increased token length. Existing compression approaches -- instance-level and token-level -- either sacrifice essential local reasoning signals like reflection or yield incoherent outputs. To address these limitations, we propose R1-Compress, a two-stage chunk-level compression framework that preserves both local information and coherence. Our method segments Long-CoT into manageable chunks, applies LLM-driven inner-chunk compression, and employs an inter-chunk search mechanism to select the short and coherent sequence. Experiments on Qwen2.5-Instruct models across MATH500, AIME24, and GPQA-Diamond demonstrate that R1-Compress significantly reduces token usage while maintaining comparable reasoning accuracy. On MATH500, R1-Compress achieves an accuracy of 92.4%, with only a 0.6% drop compared to the Long-CoT baseline, while reducing token usage by about 20%. Source code will be available at https://github.com/w-yibo/R1-Compress
KaFT: Knowledge-aware Fine-tuning for Boosting LLMs' Domain-specific Question-Answering Performance
May 21, 2025Supervised fine-tuning (SFT) is a common approach to improve the domain-specific question-answering (QA) performance of large language models (LLMs). However, recent literature reveals that due to the conflicts between LLMs' internal knowledge and the context knowledge of training data, vanilla SFT using the full QA training set is usually suboptimal. In this paper, we first design a query diversification strategy for robust conflict detection and then conduct a series of experiments to analyze the impact of knowledge conflict. We find that 1) training samples with varied conflicts contribute differently, where SFT on the data with large conflicts leads to catastrophic performance drops; 2) compared to directly filtering out the conflict data, appropriately applying the conflict data would be more beneficial. Motivated by this, we propose a simple-yet-effective Knowledge-aware Fine-tuning (namely KaFT) approach to effectively boost LLMs' performance. The core of KaFT is to adapt the training weight by assigning different rewards for different training samples according to conflict level. Extensive experiments show that KaFT brings consistent and significant improvements across four LLMs. More analyses prove that KaFT effectively improves the model generalization and alleviates the hallucination.
Cross-Domain Diffusion with Progressive Alignment for Efficient Adaptive Retrieval
May 20, 2025Unsupervised efficient domain adaptive retrieval aims to transfer knowledge from a labeled source domain to an unlabeled target domain, while maintaining low storage cost and high retrieval efficiency. However, existing methods typically fail to address potential noise in the target domain, and directly align high-level features across domains, thus resulting in suboptimal retrieval performance. To address these challenges, we propose a novel Cross-Domain Diffusion with Progressive Alignment method (COUPLE). This approach revisits unsupervised efficient domain adaptive retrieval from a graph diffusion perspective, simulating cross-domain adaptation dynamics to achieve a stable target domain adaptation process. First, we construct a cross-domain relationship graph and leverage noise-robust graph flow diffusion to simulate the transfer dynamics from the source domain to the target domain, identifying lower noise clusters. We then leverage the graph diffusion results for discriminative hash code learning, effectively learning from the target domain while reducing the negative impact of noise. Furthermore, we employ a hierarchical Mixup operation for progressive domain alignment, which is performed along the cross-domain random walk paths. Utilizing target domain discriminative hash learning and progressive domain alignment, COUPLE enables effective domain adaptive hash learning. Extensive experiments demonstrate COUPLE's effectiveness on competitive benchmarks.
* IEEE TIP