 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
May 13, 2026On-policy distillation (OPD) has emerged as an efficient post-training paradigm for large language models. However, existing studies largely attribute this advantage to denser and more stable supervision, while the parameter-level mechanisms underlying OPD's efficiency remain poorly understood. In this work, we argue that OPD's efficiency stems from a form of ``foresight'': it establishes a stable update trajectory toward the final model early in training. This foresight manifests in two aspects. First, at the \textbf{Module-Allocation Level}, OPD identifies regions with low marginal utility and concentrates updates on modules that are more critical to reasoning. Second, at the \textbf{Update-Direction Level}, OPD exhibits stronger low-rank concentration, with its dominant subspaces aligning closely with the final update subspace early in training. Building on these findings, we propose \textbf{EffOPD}, a plug-and-play acceleration method that speeds up OPD by adaptively selecting an extrapolation step size and moving along the current update direction. EffOPD requires no additional trainable modules or complex hyperparameter tuning, and achieves an average training acceleration of $3\times$ while maintaining comparable final performance. Overall, our findings provide a parameter-dynamics perspective for understanding the efficiency of OPD and offer practical insights for designing more efficient post-training methods for large language models.
GCL-Sampler: Discovering Kernel Similarity for Sampled GPU Simulation via Graph Contrastive Learning
Feb 28, 2026GPU architectural simulation is orders of magnitude slower than native execution, necessitating workload sampling for practical speedups. Existing methods rely on hand-crafted features with limited expressiveness, yielding either aggressive sampling with high errors or conservative sampling with constrained speedups. To address these issues, we propose GCL-Sampler, a sampling framework that leverages Relational Graph Convolutional Networks with contrastive learning to automatically discover high-dimensional kernel similarities from trace graphs. By encoding instruction sequences and data dependencies into graph embeddings, GCL-Sampler captures rich structural and semantic properties of program execution, enabling both high fidelity and substantial speedup. Evaluations on extensive benchmarks show that GCL-Sampler achieves 258.94x average speedup against full workload with 0.37% error, outperforming state-of-the-art methods, PKA (129.23x, 20.90%), Sieve (94.90x, 4.10%) and STEM+ROOT (56.57x, 0.38%).
VLA-JEPA: Enhancing Vision-Language-Action Model with Latent World Model
Feb 14, 2026Pretraining Vision-Language-Action (VLA) policies on internet-scale video is appealing, yet current latent-action objectives often learn the wrong thing: they remain anchored to pixel variation rather than action-relevant state transitions, making them vulnerable to appearance bias, nuisance motion, and information leakage. We introduce VLA-JEPA, a JEPA-style pretraining framework that sidesteps these pitfalls by design. The key idea is leakage-free state prediction: a target encoder produces latent representations from future frames, while the student pathway sees only the current observation -- future information is used solely as supervision targets, never as input. By predicting in latent space rather than pixel space, VLA-JEPA learns dynamics abstractions that are robust to camera motion and irrelevant background changes. This yields a simple two-stage recipe -- JEPA pretraining followed by action-head fine-tuning -- without the multi-stage complexity of prior latent-action pipelines. Experiments on LIBERO, LIBERO-Plus, SimplerEnv and real-world manipulation tasks show that VLA-JEPA achieves consistent gains in generalization and robustness over existing methods.
Token Pruning for In-Context Generation in Diffusion Transformers
Feb 02, 2026In-context generation significantly enhances Diffusion Transformers (DiTs) by enabling controllable image-to-image generation through reference examples. However, the resulting input concatenation drastically increases sequence length, creating a substantial computational bottleneck. Existing token reduction techniques, primarily tailored for text-to-image synthesis, fall short in this paradigm as they apply uniform reduction strategies, overlooking the inherent role asymmetry between reference contexts and target latents across spatial, temporal, and functional dimensions. To bridge this gap, we introduce ToPi, a training-free token pruning framework tailored for in-context generation in DiTs. Specifically, ToPi utilizes offline calibration-driven sensitivity analysis to identify pivotal attention layers, serving as a robust proxy for redundancy estimation. Leveraging these layers, we derive a novel influence metric to quantify the contribution of each context token for selective pruning, coupled with a temporal update strategy that adapts to the evolving diffusion trajectory. Empirical evaluations demonstrate that ToPi can achieve over 30\% speedup in inference while maintaining structural fidelity and visual consistency across complex image generation tasks.
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Jul 03, 2025



We propose MoGe-2, an advanced open-domain geometry estimation model that recovers a metric scale 3D point map of a scene from a single image. Our method builds upon the recent monocular geometry estimation approach, MoGe, which predicts affine-invariant point maps with unknown scales. We explore effective strategies to extend MoGe for metric geometry prediction without compromising the relative geometry accuracy provided by the affine-invariant point representation. Additionally, we discover that noise and errors in real data diminish fine-grained detail in the predicted geometry. We address this by developing a unified data refinement approach that filters and completes real data from different sources using sharp synthetic labels, significantly enhancing the granularity of the reconstructed geometry while maintaining the overall accuracy. We train our model on a large corpus of mixed datasets and conducted comprehensive evaluations, demonstrating its superior performance in achieving accurate relative geometry, precise metric scale, and fine-grained detail recovery -- capabilities that no previous methods have simultaneously achieved.
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models
Dec 21, 2023Recent remarkable advancements in large language models (LLMs) have led to their widespread adoption in various applications. A key feature of these applications is the combination of LLMs with external content, where user instructions and third-party content are combined to create prompts for LLM processing. These applications, however, are vulnerable to indirect prompt injection attacks, where malicious instructions embedded within external content compromise LLM's output, causing their responses to deviate from user expectations. Despite the discovery of this security issue, no comprehensive analysis of indirect prompt injection attacks on different LLMs is available due to the lack of a benchmark. Furthermore, no effective defense has been proposed. In this work, we introduce the first benchmark, BIPIA, to measure the robustness of various LLMs and defenses against indirect prompt injection attacks. Our experiments reveal that LLMs with greater capabilities exhibit more vulnerable to indirect prompt injection attacks for text tasks, resulting in a higher ASR. We hypothesize that indirect prompt injection attacks are mainly due to the LLMs' inability to distinguish between instructions and external content. Based on this conjecture, we propose four black-box methods based on prompt learning and a white-box defense methods based on fine-tuning with adversarial training to enable LLMs to distinguish between instructions and external content and ignore instructions in the external content. Our experimental results show that our black-box defense methods can effectively reduce ASR but cannot completely thwart indirect prompt injection attacks, while our white-box defense method can reduce ASR to nearly zero with little adverse impact on the LLM's performance on general tasks. We hope that our benchmark and defenses can inspire future work in this important area.
FedLALR: Client-Specific Adaptive Learning Rates Achieve Linear Speedup for Non-IID Data
Sep 18, 2023Federated learning is an emerging distributed machine learning method, enables a large number of clients to train a model without exchanging their local data. The time cost of communication is an essential bottleneck in federated learning, especially for training large-scale deep neural networks. Some communication-efficient federated learning methods, such as FedAvg and FedAdam, share the same learning rate across different clients. But they are not efficient when data is heterogeneous. To maximize the performance of optimization methods, the main challenge is how to adjust the learning rate without hurting the convergence. In this paper, we propose a heterogeneous local variant of AMSGrad, named FedLALR, in which each client adjusts its learning rate based on local historical gradient squares and synchronized learning rates. Theoretical analysis shows that our client-specified auto-tuned learning rate scheduling can converge and achieve linear speedup with respect to the number of clients, which enables promising scalability in federated optimization. We also empirically compare our method with several communication-efficient federated optimization methods. Extensive experimental results on Computer Vision (CV) tasks and Natural Language Processing (NLP) task show the efficacy of our proposed FedLALR method and also coincides with our theoretical findings.
Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark
May 17, 2023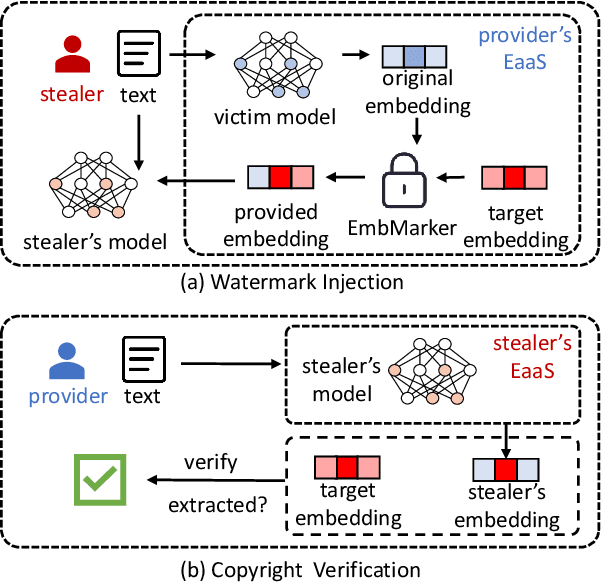
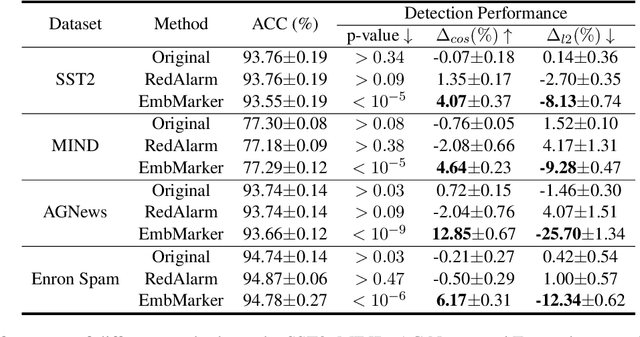
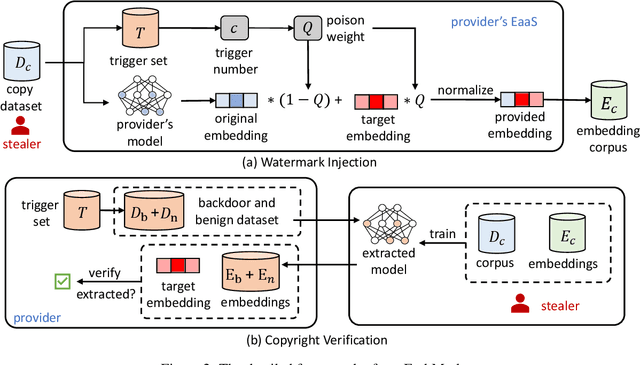
Large language models (LLMs) have demonstrated powerful capabilities in both text understanding and generation. Companies have begun to offer Embedding as a Service (EaaS) based on these LLMs, which can benefit various natural language processing (NLP) tasks for customers. However, previous studies have shown that EaaS is vulnerable to model extraction attacks, which can cause significant losses for the owners of LLMs, as training these models is extremely expensive. To protect the copyright of LLMs for EaaS, we propose an Embedding Watermark method called EmbMarker that implants backdoors on embeddings. Our method selects a group of moderate-frequency words from a general text corpus to form a trigger set, then selects a target embedding as the watermark, and inserts it into the embeddings of texts containing trigger words as the backdoor. The weight of insertion is proportional to the number of trigger words included in the text. This allows the watermark backdoor to be effectively transferred to EaaS-stealer's model for copyright verification while minimizing the adverse impact on the original embeddings' utility. Our extensive experiments on various datasets show that our method can effectively protect the copyright of EaaS models without compromising service quality.
AdaSAM: Boosting Sharpness-Aware Minimization with Adaptive Learning Rate and Momentum for Training Deep Neural Networks
Mar 01, 2023Sharpness aware minimization (SAM) optimizer has been extensively explored as it can generalize better for training deep neural networks via introducing extra perturbation steps to flatten the landscape of deep learning models. Integrating SAM with adaptive learning rate and momentum acceleration, dubbed AdaSAM, has already been explored empirically to train large-scale deep neural networks without theoretical guarantee due to the triple difficulties in analyzing the coupled perturbation step, adaptive learning rate and momentum step. In this paper, we try to analyze the convergence rate of AdaSAM in the stochastic non-convex setting. We theoretically show that AdaSAM admits a $\mathcal{O}(1/\sqrt{bT})$ convergence rate, which achieves linear speedup property with respect to mini-batch size $b$. Specifically, to decouple the stochastic gradient steps with the adaptive learning rate and perturbed gradient, we introduce the delayed second-order momentum term to decompose them to make them independent while taking an expectation during the analysis. Then we bound them by showing the adaptive learning rate has a limited range, which makes our analysis feasible. To the best of our knowledge, we are the first to provide the non-trivial convergence rate of SAM with an adaptive learning rate and momentum acceleration. At last, we conduct several experiments on several NLP tasks, which show that AdaSAM could achieve superior performance compared with SGD, AMSGrad, and SAM optimizers.
Effective and Efficient Query-aware Snippet Extraction for Web Search
Oct 17, 2022
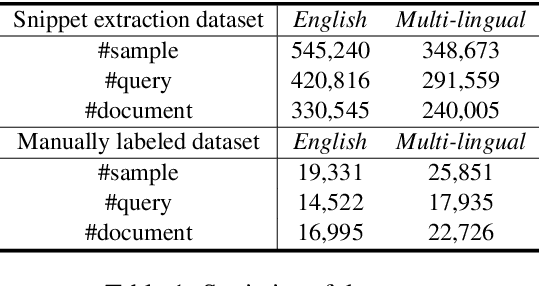
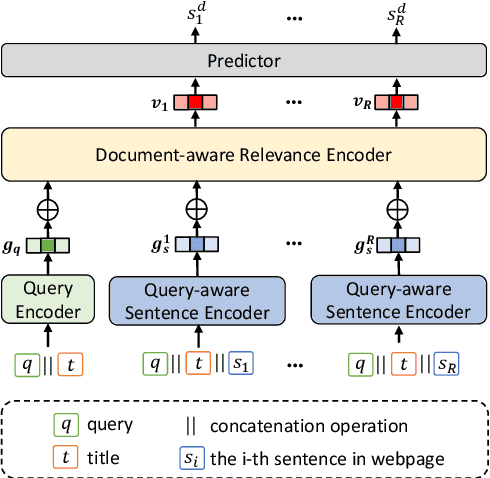
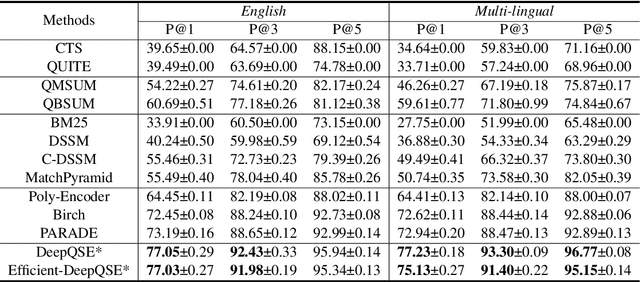
Query-aware webpage snippet extraction is widely used in search engines to help users better understand the content of the returned webpages before clicking. Although important, it is very rarely studied. In this paper, we propose an effective query-aware webpage snippet extraction method named DeepQSE, aiming to select a few sentences which can best summarize the webpage content in the context of input query. DeepQSE first learns query-aware sentence representations for each sentence to capture the fine-grained relevance between query and sentence, and then learns document-aware query-sentence relevance representations for snippet extraction. Since the query and each sentence are jointly modeled in DeepQSE, its online inference may be slow. Thus, we further propose an efficient version of DeepQSE, named Efficient-DeepQSE, which can significantly improve the inference speed of DeepQSE without affecting its performance. The core idea of Efficient-DeepQSE is to decompose the query-aware snippet extraction task into two stages, i.e., a coarse-grained candidate sentence selection stage where sentence representations can be cached, and a fine-grained relevance modeling stage. Experiments on two real-world datasets validate the effectiveness and efficiency of our methods.