 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-Guided Robust Counterfactual Explanations on Tabular Data under Model Multiplicity
May 29, 2026Counterfactual explanations (CEs) are essential for actionable recourse, yet their reliability is often compromised in low-density regions, where classifiers exhibit high variance. Unlike existing methods that rely on expensive ensemble intersections to define stability, we propose \textit{DensityFlow}, a generative framework that constructs robust CEs by adhering to the high-confidence data manifold. Specifically, we model the counterfactual generation as continuous-time dynamics parameterized by Neural ODE, guided by a differentiable density score to actively avoid uncertain, low-density areas. This density score is learned via Noise Contrastive Estimation, effectively leveraging a $(K{+}1)$-way discriminator to estimate density ratios. For black-box settings, we introduce a local proxy distillation mechanism that aligns a lightweight surrogate with the target model strictly within the trajectory of CE generation, enabling efficient gradient-based optimization with minimal queries. Experiments demonstrate that \textit{DensityFlow} achieves superior validity under model multiplicity while significantly reducing query costs compared to ensemble-based baselines. Our implementation is available at https://github.com/G-AILab/DensityFlow.
Parametric Prior Mapping Framework for Non-stationary Probabilistic Time Series Forecasting
May 22, 2026Effectively modeling non-stationary dynamics in probabilistic multivariate time series(MTS) forecasting requires balancing expressiveness with robustness. Existing parametric approaches benefit from strong inductive biases but lack flexibility, whereas deep generative models struggle to capture complex temporal dependencies without extensive data and computation. We introduce Parametric Prior Mapping (PPM), a framework that injects parametric structural priors into a generative modeling process. Specifically, PPM utilizes a parametric estimator to derive a dynamic, adaptive prior that guides the learning of a complex predictive distribution via a learnable mapping. This design allows the model to retain the efficiency of parametric methods while exploiting the expressive power of generative models. Trained with a hybrid objective, PPM yields precise forecasts with well-calibrated uncertainty estimates. Empirical results show that PPM outperforms existing baselines in handling non-stationary data, offering a superior trade-off between accuracy and computational efficiency. The code is available at https://github.com/ljl8336/PPM.
Non-stationary Diffusion For Probabilistic Time Series Forecasting
May 07, 2025



Due to the dynamics of underlying physics and external influences, the uncertainty of time series often varies over time. However, existing Denoising Diffusion Probabilistic Models (DDPMs) often fail to capture this non-stationary nature, constrained by their constant variance assumption from the additive noise model (ANM). In this paper, we innovatively utilize the Location-Scale Noise Model (LSNM) to relax the fixed uncertainty assumption of ANM. A diffusion-based probabilistic forecasting framework, termed Non-stationary Diffusion (NsDiff), is designed based on LSNM that is capable of modeling the changing pattern of uncertainty. Specifically, NsDiff combines a denoising diffusion-based conditional generative model with a pre-trained conditional mean and variance estimator, enabling adaptive endpoint distribution modeling. Furthermore, we propose an uncertainty-aware noise schedule, which dynamically adjusts the noise levels to accurately reflect the data uncertainty at each step and integrates the time-varying variances into the diffusion process. Extensive experiments conducted on nine real-world and synthetic datasets demonstrate the superior performance of NsDiff compared to existing approaches. Code is available at https://github.com/wwy155/NsDiff.
Ordering-Based Causal Discovery for Linear and Nonlinear Relations
Oct 08, 2024



Identifying causal relations from purely observational data typically requires additional assumptions on relations and/or noise. Most current methods restrict their analysis to datasets that are assumed to have pure linear or nonlinear relations, which is often not reflective of real-world datasets that contain a combination of both. This paper presents CaPS, an ordering-based causal discovery algorithm that effectively handles linear and nonlinear relations. CaPS introduces a novel identification criterion for topological ordering and incorporates the concept of "parent score" during the post-processing optimization stage. These scores quantify the strength of the average causal effect, helping to accelerate the pruning process and correct inaccurate predictions in the pruning step. Experimental results demonstrate that our proposed solutions outperform state-of-the-art baselines on synthetic data with varying ratios of linear and nonlinear relations. The results obtained from real-world data also support the competitiveness of CaPS. Code and datasets are available at https://github.com/E2real/CaPS.
Frequency Adaptive Normalization For Non-stationary Time Series Forecasting
Sep 30, 2024



Time series forecasting typically needs to address non-stationary data with evolving trend and seasonal patterns. To address the non-stationarity, reversible instance normalization has been recently proposed to alleviate impacts from the trend with certain statistical measures, e.g., mean and variance. Although they demonstrate improved predictive accuracy, they are limited to expressing basic trends and are incapable of handling seasonal patterns. To address this limitation, this paper proposes a new instance normalization solution, called frequency adaptive normalization (FAN), which extends instance normalization in handling both dynamic trend and seasonal patterns. Specifically, we employ the Fourier transform to identify instance-wise predominant frequent components that cover most non-stationary factors. Furthermore, the discrepancy of those frequency components between inputs and outputs is explicitly modeled as a prediction task with a simple MLP model. FAN is a model-agnostic method that can be applied to arbitrary predictive backbones. We instantiate FAN on four widely used forecasting models as the backbone and evaluate their prediction performance improvements on eight benchmark datasets. FAN demonstrates significant performance advancement, achieving 7.76% ~ 37.90% average improvements in MSE.
Are Large Language Models Really Robust to Word-Level Perturbations?
Sep 27, 2023



The swift advancement in the scales and capabilities of Large Language Models (LLMs) positions them as promising tools for a variety of downstream tasks. In addition to the pursuit of better performance and the avoidance of violent feedback on a certain prompt, to ensure the responsibility of the LLM, much attention is drawn to the robustness of LLMs. However, existing evaluation methods mostly rely on traditional question answering datasets with predefined supervised labels, which do not align with the superior generation capabilities of contemporary LLMs. To address this issue, we propose a novel rational evaluation approach that leverages pre-trained reward models as diagnostic tools to evaluate the longer conversation generated from more challenging open questions by LLMs, which we refer to as the Reward Model for Reasonable Robustness Evaluation (TREvaL). Longer conversations manifest the comprehensive grasp of language models in terms of their proficiency in understanding questions, a capability not entirely encompassed by individual words or letters, which may exhibit oversimplification and inherent biases. Our extensive empirical experiments demonstrate that TREvaL provides an innovative method for evaluating the robustness of an LLM. Furthermore, our results demonstrate that LLMs frequently exhibit vulnerability to word-level perturbations that are commonplace in daily language usage. Notably, we are surprised to discover that robustness tends to decrease as fine-tuning (SFT and RLHF) is conducted. The code of TREval is available in https://github.com/Harry-mic/TREvaL.
Multi-View Graph Representation Learning Beyond Homophily
Apr 15, 2023Unsupervised graph representation learning(GRL) aims to distill diverse graph information into task-agnostic embeddings without label supervision. Due to a lack of support from labels, recent representation learning methods usually adopt self-supervised learning, and embeddings are learned by solving a handcrafted auxiliary task(so-called pretext task). However, partially due to the irregular non-Euclidean data in graphs, the pretext tasks are generally designed under homophily assumptions and cornered in the low-frequency signals, which results in significant loss of other signals, especially high-frequency signals widespread in graphs with heterophily. Motivated by this limitation, we propose a multi-view perspective and the usage of diverse pretext tasks to capture different signals in graphs into embeddings. A novel framework, denoted as Multi-view Graph Encoder(MVGE), is proposed, and a set of key designs are identified. More specifically, a set of new pretext tasks are designed to encode different types of signals, and a straightforward operation is propxwosed to maintain both the commodity and personalization in both the attribute and the structural levels. Extensive experiments on synthetic and real-world network datasets show that the node representations learned with MVGE achieve significant performance improvements in three different downstream tasks, especially on graphs with heterophily. Source code is available at \url{https://github.com/G-AILab/MVGE}.
Data Imputation with Iterative Graph Reconstruction
Dec 06, 2022



Effective data imputation demands rich latent ``structure" discovery capabilities from ``plain" tabular data. Recent advances in graph neural networks-based data imputation solutions show their strong structure learning potential by directly translating tabular data as bipartite graphs. However, due to a lack of relations between samples, those solutions treat all samples equally which is against one important observation: ``similar sample should give more information about missing values." This paper presents a novel Iterative graph Generation and Reconstruction framework for Missing data imputation(IGRM). Instead of treating all samples equally, we introduce the concept: ``friend networks" to represent different relations among samples. To generate an accurate friend network with missing data, an end-to-end friend network reconstruction solution is designed to allow for continuous friend network optimization during imputation learning. The representation of the optimized friend network, in turn, is used to further optimize the data imputation process with differentiated message passing. Experiment results on eight benchmark datasets show that IGRM yields 39.13% lower mean absolute error compared with nine baselines and 9.04% lower than the second-best.
A-SFS: Semi-supervised Feature Selection based on Multi-task Self-supervision
Jul 19, 2022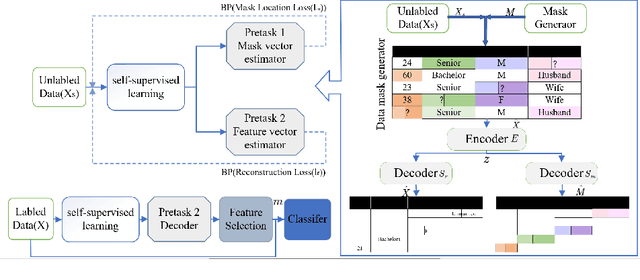
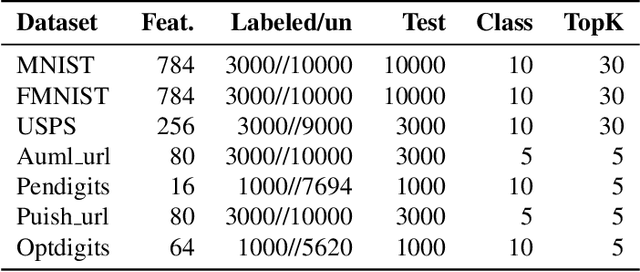
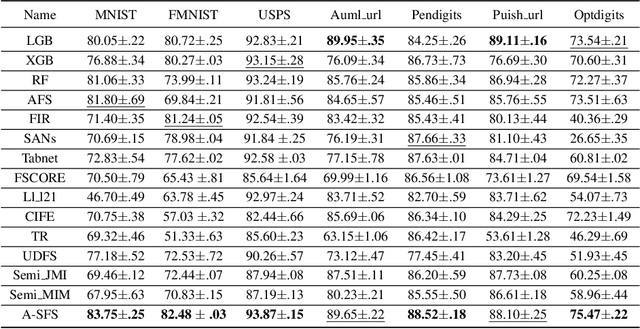
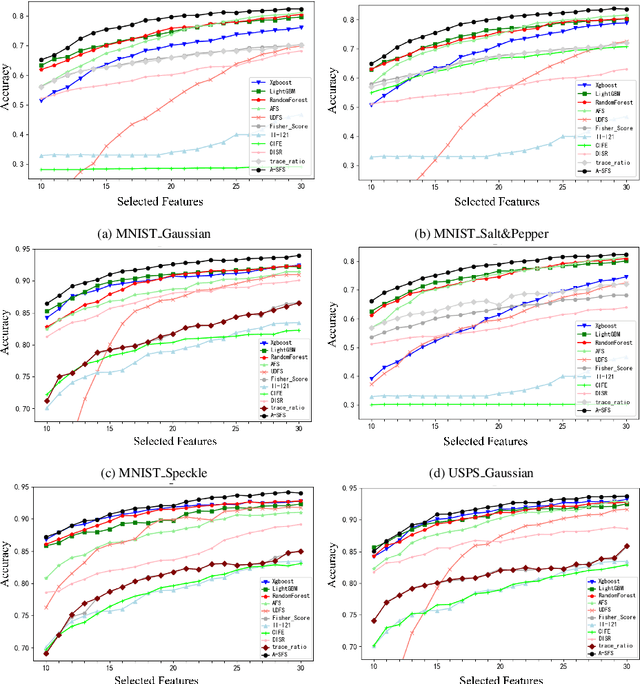
Feature selection is an important process in machine learning. It builds an interpretable and robust model by selecting the features that contribute the most to the prediction target. However, most mature feature selection algorithms, including supervised and semi-supervised, fail to fully exploit the complex potential structure between features. We believe that these structures are very important for the feature selection process, especially when labels are lacking and data is noisy. To this end, we innovatively introduce a deep learning-based self-supervised mechanism into feature selection problems, namely batch-Attention-based Self-supervision Feature Selection(A-SFS). Firstly, a multi-task self-supervised autoencoder is designed to uncover the hidden structure among features with the support of two pretext tasks. Guided by the integrated information from the multi-self-supervised learning model, a batch-attention mechanism is designed to generate feature weights according to batch-based feature selection patterns to alleviate the impacts introduced by a handful of noisy data. This method is compared to 14 major strong benchmarks, including LightGBM and XGBoost. Experimental results show that A-SFS achieves the highest accuracy in most datasets. Furthermore, this design significantly reduces the reliance on labels, with only 1/10 labeled data needed to achieve the same performance as those state of art baselines. Results show that A-SFS is also most robust to the noisy and missing data.
An Embedded Feature Selection Framework for Control
Jun 19, 2022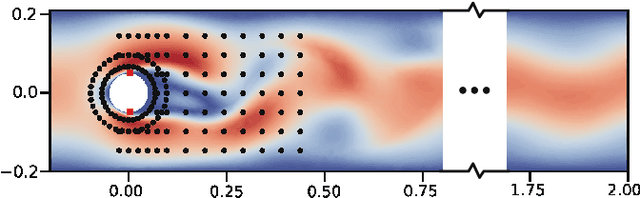

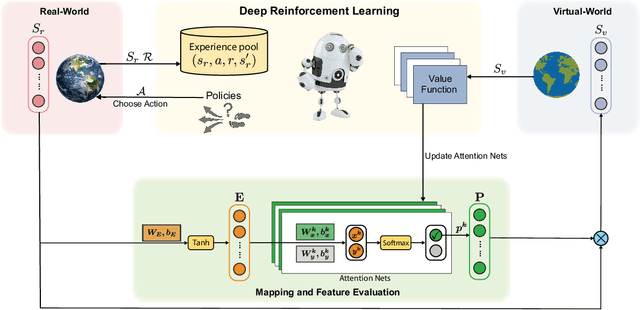
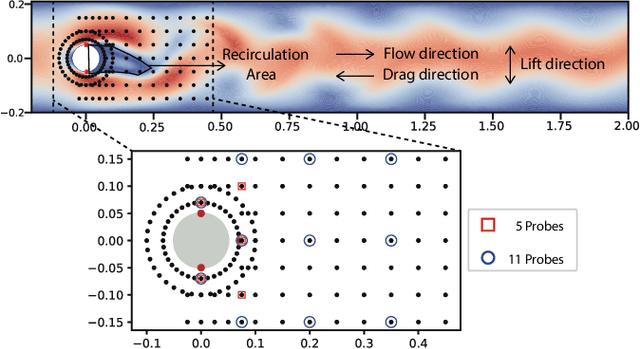
Reducing sensor requirements while keeping optimal control performance is crucial to many industrial control applications to achieve robust, low-cost, and computation-efficient controllers. However, existing feature selection solutions for the typical machine learning domain can hardly be applied in the domain of control with changing dynamics. In this paper, a novel framework, namely the Dual-world embedded Attentive Feature Selection (D-AFS), can efficiently select the most relevant sensors for the system under dynamic control. Rather than the one world used in most Deep Reinforcement Learning (DRL) algorithms, D-AFS has both the real world and its virtual peer with twisted features. By analyzing the DRL's response in two worlds, D-AFS can quantitatively identify respective features' importance towards control. A well-known active flow control problem, cylinder drag reduction, is used for evaluation. Results show that D-AFS successfully finds an optimized five-probes layout with 18.7\% drag reduction than the state-of-the-art solution with 151 probes and 49.2\% reduction than five-probes layout by human experts. We also apply this solution to four OpenAI classical control cases. In all cases, D-AFS achieves the same or better sensor configurations than originally provided solutions. Results highlight, we argued, a new way to achieve efficient and optimal sensor designs for experimental or industrial systems. Our source codes are made publicly available at https://github.com/G-AILab/DAFSFluid.