 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
Preference-grounded Token-level Guidance for Language Model Fine-tuning
Jun 01, 2023



Aligning language models (LMs) with preferences is an important problem in natural language generation. A key challenge is that preferences are typically provided at the sequence level while LM training and generation both occur at the token level. There is, therefore, a granularity mismatch between the preference and the LM training losses, which may complicate the learning problem. In this paper, we address this issue by developing an alternate training process, where we iterate between grounding the sequence-level preference into token-level training guidance, and improving the LM with the learned guidance. For guidance learning, we design a framework that extends the pairwise-preference learning in imitation learning to both variable-length LM generation and utilizing the preference among multiple generations. For LM training, based on the amount of supervised data, we present two minimalist learning objectives that utilize the learned guidance. In experiments, our method performs competitively on two distinct representative LM tasks -- discrete-prompt generation and text summarization.
Learning to Select from Multiple Options
Dec 01, 2022



Many NLP tasks can be regarded as a selection problem from a set of options, such as classification tasks, multi-choice question answering, etc. Textual entailment (TE) has been shown as the state-of-the-art (SOTA) approach to dealing with those selection problems. TE treats input texts as premises (P), options as hypotheses (H), then handles the selection problem by modeling (P, H) pairwise. Two limitations: first, the pairwise modeling is unaware of other options, which is less intuitive since humans often determine the best options by comparing competing candidates; second, the inference process of pairwise TE is time-consuming, especially when the option space is large. To deal with the two issues, this work first proposes a contextualized TE model (Context-TE) by appending other k options as the context of the current (P, H) modeling. Context-TE is able to learn more reliable decision for the H since it considers various context. Second, we speed up Context-TE by coming up with Parallel-TE, which learns the decisions of multiple options simultaneously. Parallel-TE significantly improves the inference speed while keeping comparable performance with Context-TE. Our methods are evaluated on three tasks (ultra-fine entity typing, intent detection and multi-choice QA) that are typical selection problems with different sizes of options. Experiments show our models set new SOTA performance; particularly, Parallel-TE is faster than the pairwise TE by k times in inference. Our code is publicly available at https://github.com/jiangshdd/LearningToSelect.
Continuous Prompt Tuning Based Textual Entailment Model for E-commerce Entity Typing
Nov 04, 2022The explosion of e-commerce has caused the need for processing and analysis of product titles, like entity typing in product titles. However, the rapid activity in e-commerce has led to the rapid emergence of new entities, which is difficult to be solved by general entity typing. Besides, product titles in e-commerce have very different language styles from text data in general domain. In order to handle new entities in product titles and address the special language styles problem of product titles in e-commerce domain, we propose our textual entailment model with continuous prompt tuning based hypotheses and fusion embeddings for e-commerce entity typing. First, we reformulate the entity typing task into a textual entailment problem to handle new entities that are not present during training. Second, we design a model to automatically generate textual entailment hypotheses using a continuous prompt tuning method, which can generate better textual entailment hypotheses without manual design. Third, we utilize the fusion embeddings of BERT embedding and CharacterBERT embedding with a two-layer MLP classifier to solve the problem that the language styles of product titles in e-commerce are different from that of general domain. To analyze the effect of each contribution, we compare the performance of entity typing and textual entailment model, and conduct ablation studies on continuous prompt tuning and fusion embeddings. We also evaluate the impact of different prompt template initialization for the continuous prompt tuning. We show our proposed model improves the average F1 score by around 2% compared to the baseline BERT entity typing model.
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
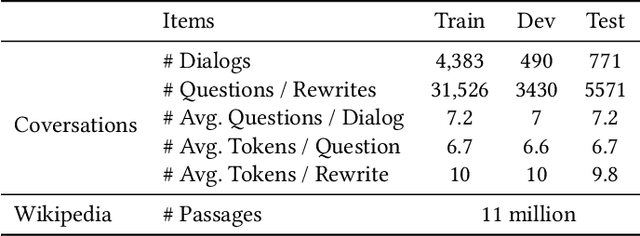
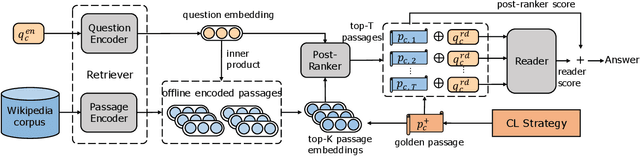
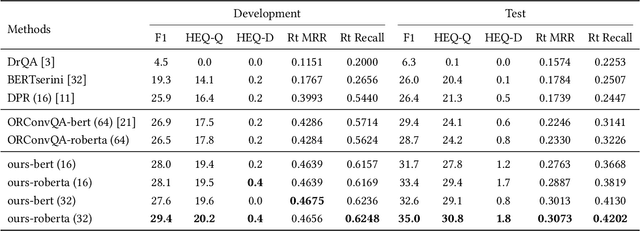
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.
HETFORMER: Heterogeneous Transformer with Sparse Attention for Long-Text Extractive Summarization
Oct 19, 2021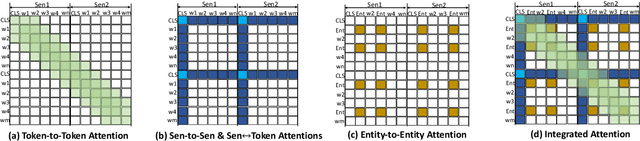
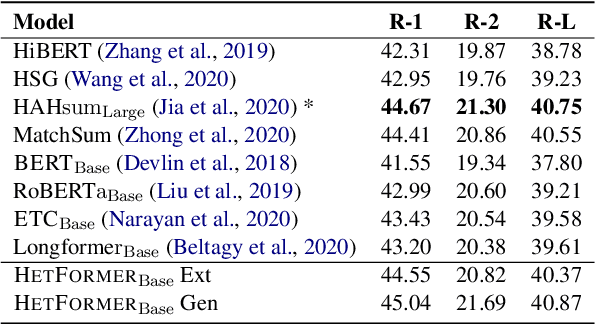
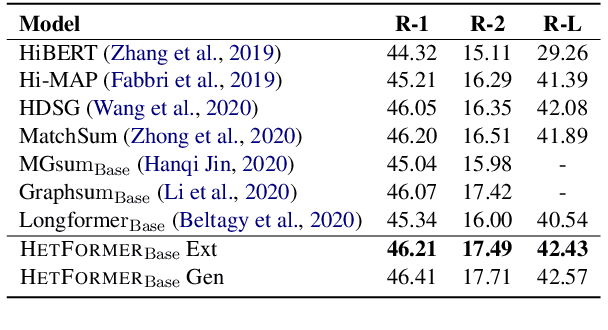

To capture the semantic graph structure from raw text, most existing summarization approaches are built on GNNs with a pre-trained model. However, these methods suffer from cumbersome procedures and inefficient computations for long-text documents. To mitigate these issues, this paper proposes HETFORMER, a Transformer-based pre-trained model with multi-granularity sparse attentions for long-text extractive summarization. Specifically, we model different types of semantic nodes in raw text as a potential heterogeneous graph and directly learn heterogeneous relationships (edges) among nodes by Transformer. Extensive experiments on both single- and multi-document summarization tasks show that HETFORMER achieves state-of-the-art performance in Rouge F1 while using less memory and fewer parameters.
Cross-lingual COVID-19 Fake News Detection
Oct 14, 2021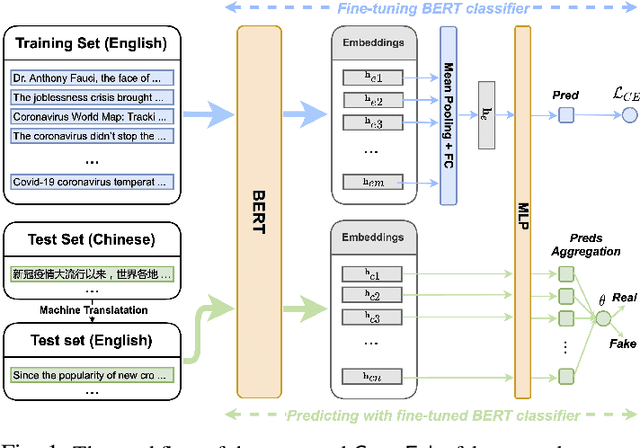

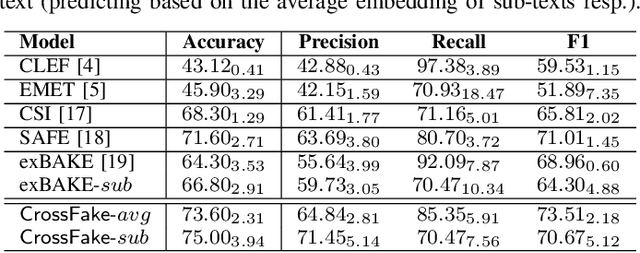
The COVID-19 pandemic poses a great threat to global public health. Meanwhile, there is massive misinformation associated with the pandemic which advocates unfounded or unscientific claims. Even major social media and news outlets have made an extra effort in debunking COVID-19 misinformation, most of the fact-checking information is in English, whereas some unmoderated COVID-19 misinformation is still circulating in other languages, threatening the health of less-informed people in immigrant communities and developing countries. In this paper, we make the first attempt to detect COVID-19 misinformation in a low-resource language (Chinese) only using the fact-checked news in a high-resource language (English). We start by curating a Chinese real&fake news dataset according to existing fact-checking information. Then, we propose a deep learning framework named CrossFake to jointly encode the cross-lingual news body texts and capture the news content as much as possible. Empirical results on our dataset demonstrate the effectiveness of CrossFake under the cross-lingual setting and it also outperforms several monolingual and cross-lingual fake news detectors. The dataset is available at https://github.com/YingtongDou/CrossFake.
Few-Shot Intent Detection via Contrastive Pre-Training and Fine-Tuning
Sep 13, 2021
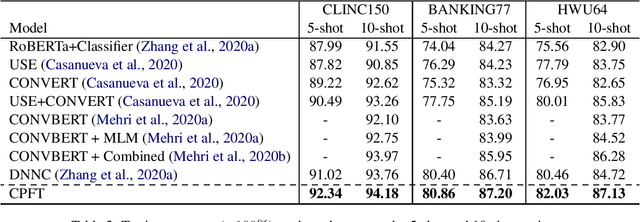

In this work, we focus on a more challenging few-shot intent detection scenario where many intents are fine-grained and semantically similar. We present a simple yet effective few-shot intent detection schema via contrastive pre-training and fine-tuning. Specifically, we first conduct self-supervised contrastive pre-training on collected intent datasets, which implicitly learns to discriminate semantically similar utterances without using any labels. We then perform few-shot intent detection together with supervised contrastive learning, which explicitly pulls utterances from the same intent closer and pushes utterances across different intents farther. Experimental results show that our proposed method achieves state-of-the-art performance on three challenging intent detection datasets under 5-shot and 10-shot settings.
Pseudo Siamese Network for Few-shot Intent Generation
May 03, 2021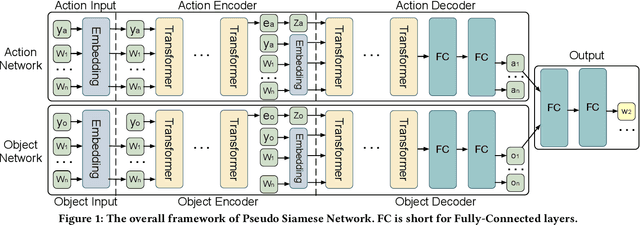
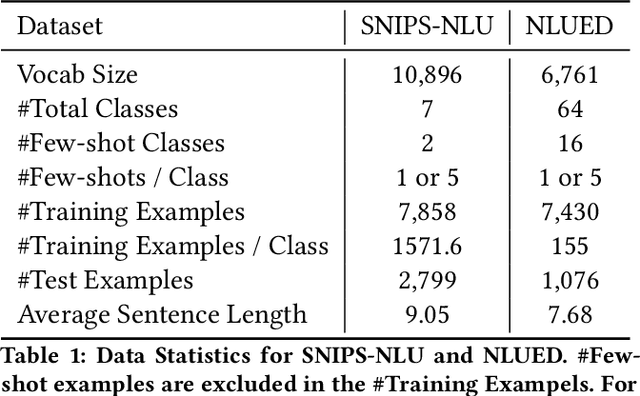
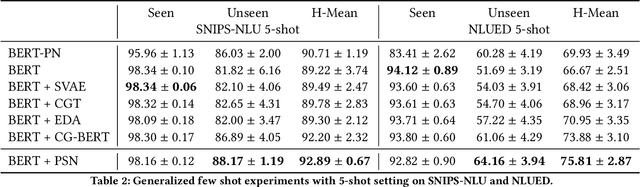
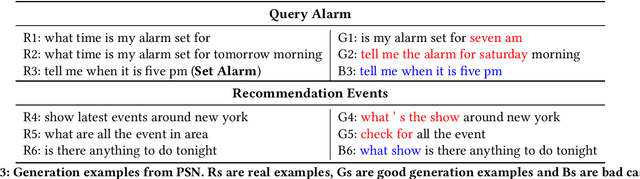
Few-shot intent detection is a challenging task due to the scare annotation problem. In this paper, we propose a Pseudo Siamese Network (PSN) to generate labeled data for few-shot intents and alleviate this problem. PSN consists of two identical subnetworks with the same structure but different weights: an action network and an object network. Each subnetwork is a transformer-based variational autoencoder that tries to model the latent distribution of different components in the sentence. The action network is learned to understand action tokens and the object network focuses on object-related expressions. It provides an interpretable framework for generating an utterance with an action and an object existing in a given intent. Experiments on two real-world datasets show that PSN achieves state-of-the-art performance for the generalized few shot intent detection task.
User Preference-aware Fake News Detection
Apr 25, 2021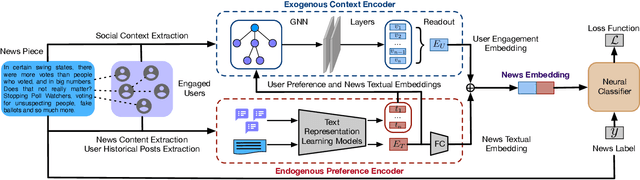
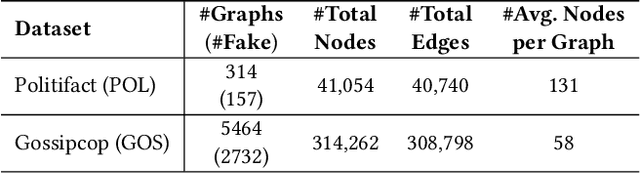
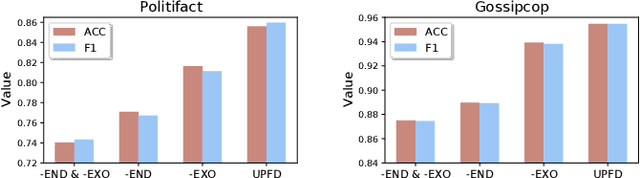
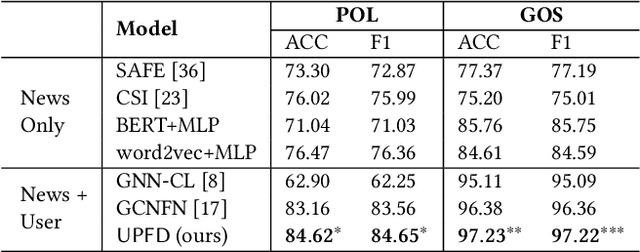
Disinformation and fake news have posed detrimental effects on individuals and society in recent years, attracting broad attention to fake news detection. The majority of existing fake news detection algorithms focus on mining news content and/or the surrounding exogenous context for discovering deceptive signals; while the endogenous preference of a user when he/she decides to spread a piece of fake news or not is ignored. The confirmation bias theory has indicated that a user is more likely to spread a piece of fake news when it confirms his/her existing beliefs/preferences. Users' historical, social engagements such as posts provide rich information about users' preferences toward news and have great potential to advance fake news detection. However, the work on exploring user preference for fake news detection is somewhat limited. Therefore, in this paper, we study the novel problem of exploiting user preference for fake news detection. We propose a new framework, UPFD, which simultaneously captures various signals from user preferences by joint content and graph modeling. Experimental results on real-world datasets demonstrate the effectiveness of the proposed framework. We release our code and data as a benchmark for GNN-based fake news detection: https://github.com/safe-graph/GNN-FakeNews.