 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Apr 08, 2026Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
Mar 12, 2026We present InSpatio-WorldFM, an open-source real-time frame model for spatial intelligence. Unlike video-based world models that rely on sequential frame generation and incur substantial latency due to window-level processing, InSpatio-WorldFM adopts a frame-based paradigm that generates each frame independently, enabling low-latency real-time spatial inference. By enforcing multi-view spatial consistency through explicit 3D anchors and implicit spatial memory, the model preserves global scene geometry while maintaining fine-grained visual details across viewpoint changes. We further introduce a progressive three-stage training pipeline that transforms a pretrained image diffusion model into a controllable frame model and finally into a real-time generator through few-step distillation. Experimental results show that InSpatio-WorldFM achieves strong multi-view consistency while supporting interactive exploration on consumer-grade GPUs, providing an efficient alternative to traditional video-based world models for real-time world simulation.
Multifaceted Improvements for Conversational Open-Domain Question Answering
Apr 01, 2022
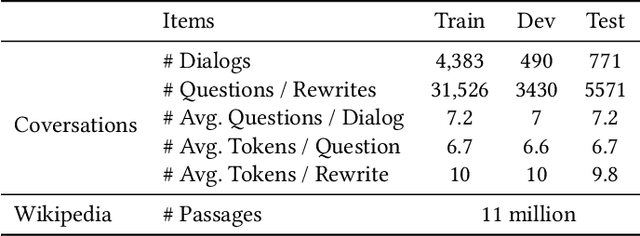
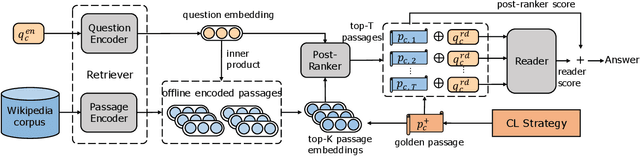
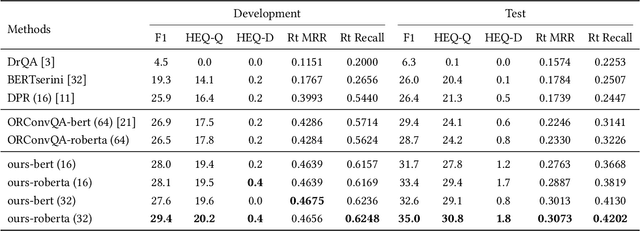
Open-domain question answering (OpenQA) is an important branch of textual QA which discovers answers for the given questions based on a large number of unstructured documents. Effectively mining correct answers from the open-domain sources still has a fair way to go. Existing OpenQA systems might suffer from the issues of question complexity and ambiguity, as well as insufficient background knowledge. Recently, conversational OpenQA is proposed to address these issues with the abundant contextual information in the conversation. Promising as it might be, there exist several fundamental limitations including the inaccurate question understanding, the coarse ranking for passage selection, and the inconsistent usage of golden passage in the training and inference phases. To alleviate these limitations, in this paper, we propose a framework with Multifaceted Improvements for Conversational open-domain Question Answering (MICQA). Specifically, MICQA has three significant advantages. First, the proposed KL-divergence based regularization is able to lead to a better question understanding for retrieval and answer reading. Second, the added post-ranker module can push more relevant passages to the top placements and be selected for reader with a two-aspect constrains. Third, the well designed curriculum learning strategy effectively narrows the gap between the golden passage settings of training and inference, and encourages the reader to find true answer without the golden passage assistance. Extensive experiments conducted on the publicly available dataset OR-QuAC demonstrate the superiority of MICQA over the state-of-the-art model in conversational OpenQA task.