 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Question Understanding and Answering with Knowledge Grounding and Semantic Self-Supervision
Sep 30, 2022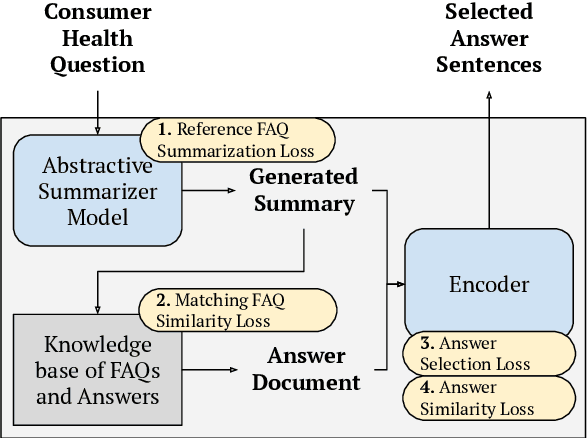
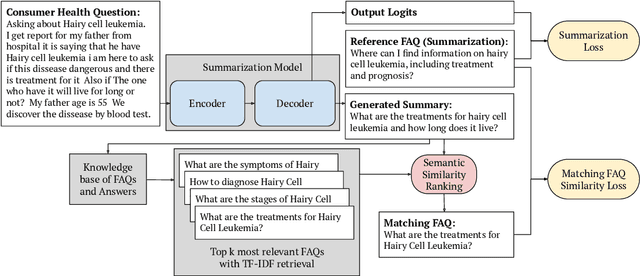

Current medical question answering systems have difficulty processing long, detailed and informally worded questions submitted by patients, called Consumer Health Questions (CHQs). To address this issue, we introduce a medical question understanding and answering system with knowledge grounding and semantic self-supervision. Our system is a pipeline that first summarizes a long, medical, user-written question, using a supervised summarization loss. Then, our system performs a two-step retrieval to return answers. The system first matches the summarized user question with an FAQ from a trusted medical knowledge base, and then retrieves a fixed number of relevant sentences from the corresponding answer document. In the absence of labels for question matching or answer relevance, we design 3 novel, self-supervised and semantically-guided losses. We evaluate our model against two strong retrieval-based question answering baselines. Evaluators ask their own questions and rate the answers retrieved by our baselines and own system according to their relevance. They find that our system retrieves more relevant answers, while achieving speeds 20 times faster. Our self-supervised losses also help the summarizer achieve higher scores in ROUGE, as well as in human evaluation metrics. We release our code to encourage further research.
Few-Shot Intent Detection via Contrastive Pre-Training and Fine-Tuning
Sep 13, 2021
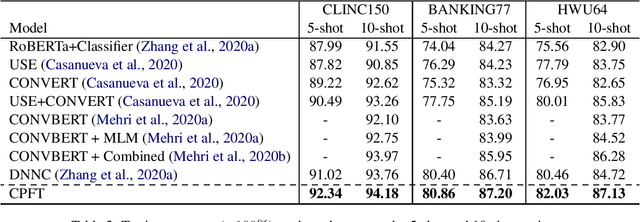

In this work, we focus on a more challenging few-shot intent detection scenario where many intents are fine-grained and semantically similar. We present a simple yet effective few-shot intent detection schema via contrastive pre-training and fine-tuning. Specifically, we first conduct self-supervised contrastive pre-training on collected intent datasets, which implicitly learns to discriminate semantically similar utterances without using any labels. We then perform few-shot intent detection together with supervised contrastive learning, which explicitly pulls utterances from the same intent closer and pushes utterances across different intents farther. Experimental results show that our proposed method achieves state-of-the-art performance on three challenging intent detection datasets under 5-shot and 10-shot settings.
StreamHover: Livestream Transcript Summarization and Annotation
Sep 11, 2021
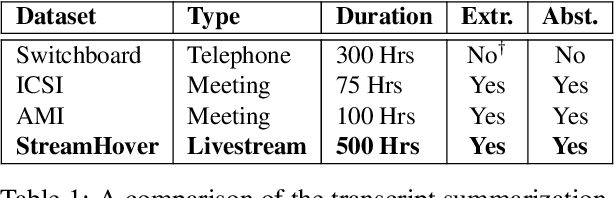

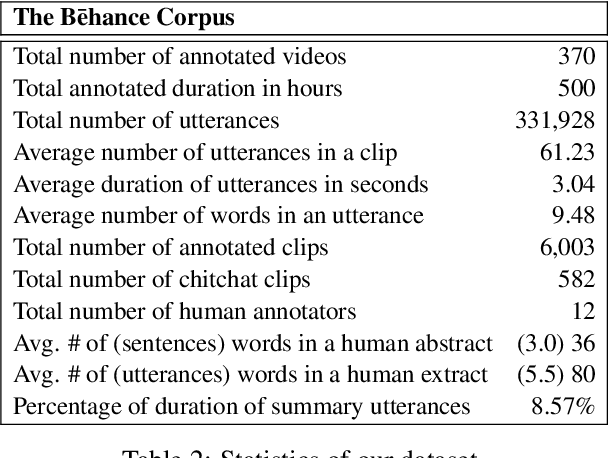
With the explosive growth of livestream broadcasting, there is an urgent need for new summarization technology that enables us to create a preview of streamed content and tap into this wealth of knowledge. However, the problem is nontrivial due to the informal nature of spoken language. Further, there has been a shortage of annotated datasets that are necessary for transcript summarization. In this paper, we present StreamHover, a framework for annotating and summarizing livestream transcripts. With a total of over 500 hours of videos annotated with both extractive and abstractive summaries, our benchmark dataset is significantly larger than currently existing annotated corpora. We explore a neural extractive summarization model that leverages vector-quantized variational autoencoder to learn latent vector representations of spoken utterances and identify salient utterances from the transcripts to form summaries. We show that our model generalizes better and improves performance over strong baselines. The results of this study provide an avenue for future research to improve summarization solutions for efficient browsing of livestreams.
A Context-Dependent Gated Module for Incorporating Symbolic Semantics into Event Coreference Resolution
Apr 04, 2021
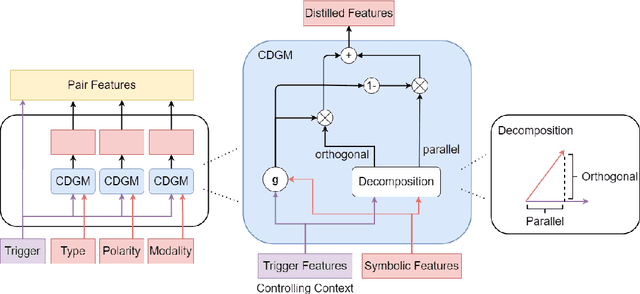
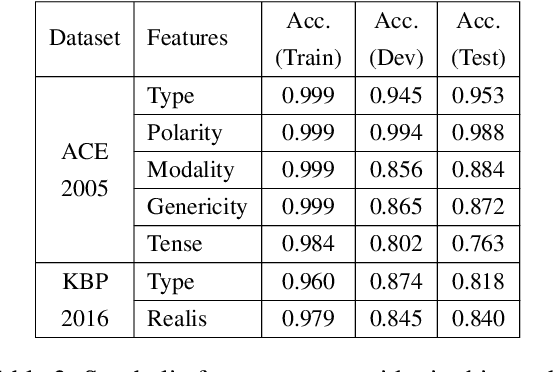
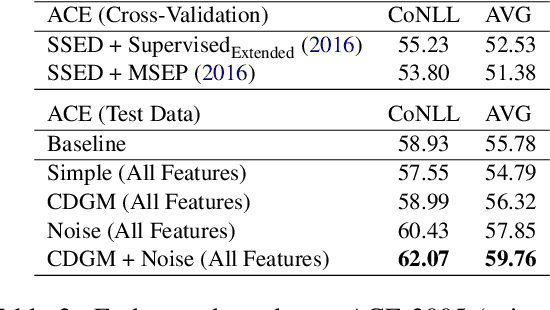
Event coreference resolution is an important research problem with many applications. Despite the recent remarkable success of pretrained language models, we argue that it is still highly beneficial to utilize symbolic features for the task. However, as the input for coreference resolution typically comes from upstream components in the information extraction pipeline, the automatically extracted symbolic features can be noisy and contain errors. Also, depending on the specific context, some features can be more informative than others. Motivated by these observations, we propose a novel context-dependent gated module to adaptively control the information flows from the input symbolic features. Combined with a simple noisy training method, our best models achieve state-of-the-art results on two datasets: ACE 2005 and KBP 2016.
MadDog: A Web-based System for Acronym Identification and Disambiguation
Jan 25, 2021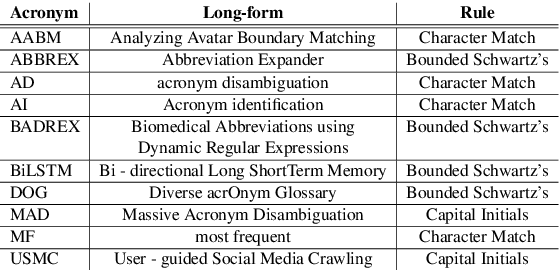

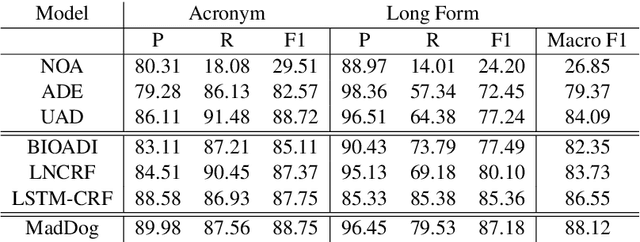
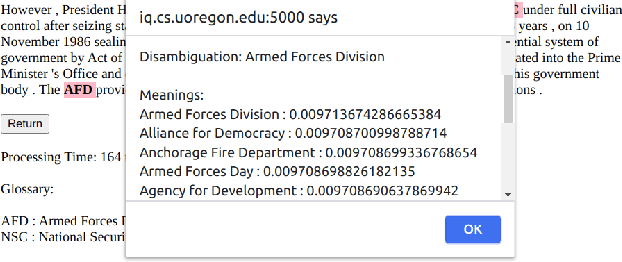
Acronyms and abbreviations are the short-form of longer phrases and they are ubiquitously employed in various types of writing. Despite their usefulness to save space in writing and reader's time in reading, they also provide challenges for understanding the text especially if the acronym is not defined in the text or if it is used far from its definition in long texts. To alleviate this issue, there are considerable efforts both from the research community and software developers to build systems for identifying acronyms and finding their correct meanings in the text. However, none of the existing works provide a unified solution capable of processing acronyms in various domains and to be publicly available. Thus, we provide the first web-based acronym identification and disambiguation system which can process acronyms from various domains including scientific, biomedical, and general domains. The web-based system is publicly available at http://iq.cs.uoregon.edu:5000 and a demo video is available at https://youtu.be/IkSh7LqI42M. The system source code is also available at https://github.com/amirveyseh/MadDog.
Acronym Identification and Disambiguation Shared Tasks for Scientific Document Understanding
Jan 06, 2021

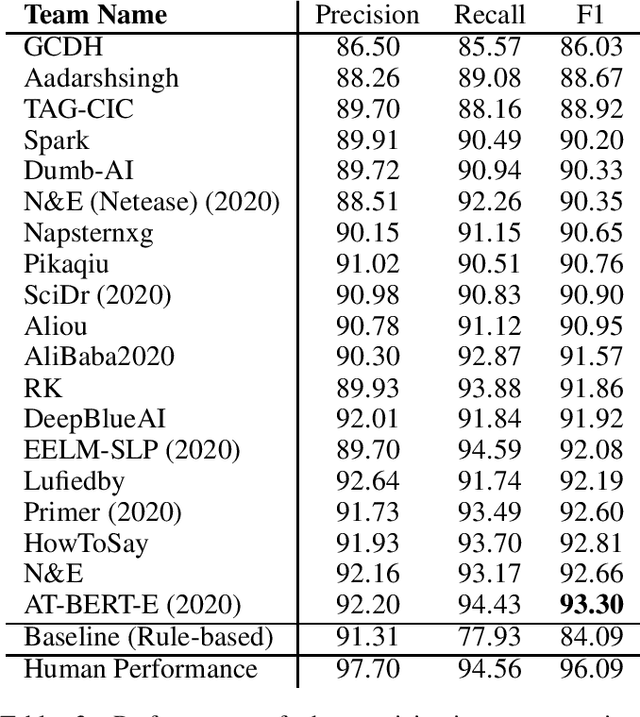
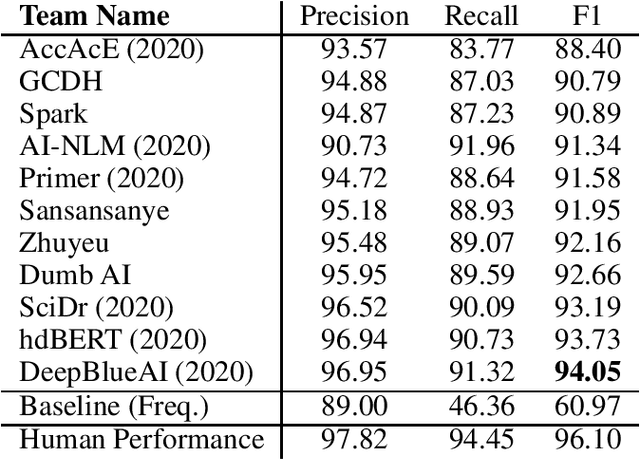
Acronyms are the short forms of longer phrases and they are frequently used in writing, especially scholarly writing, to save space and facilitate the communication of information. As such, every text understanding tool should be capable of recognizing acronyms in text (i.e., acronym identification) and also finding their correct meaning (i.e., acronym disambiguation). As most of the prior works on these tasks are restricted to the biomedical domain and use unsupervised methods or models trained on limited datasets, they fail to perform well for scientific document understanding. To push forward research in this direction, we have organized two shared task for acronym identification and acronym disambiguation in scientific documents, named AI@SDU and AD@SDU, respectively. The two shared tasks have attracted 52 and 43 participants, respectively. While the submitted systems make substantial improvements compared to the existing baselines, there are still far from the human-level performance. This paper reviews the two shared tasks and the prominent participating systems for each of them.
Learning to Fuse Sentences with Transformers for Summarization
Oct 08, 2020
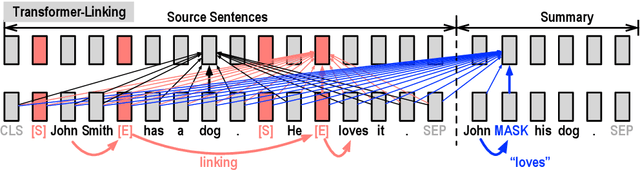

The ability to fuse sentences is highly attractive for summarization systems because it is an essential step to produce succinct abstracts. However, to date, summarizers can fail on fusing sentences. They tend to produce few summary sentences by fusion or generate incorrect fusions that lead the summary to fail to retain the original meaning. In this paper, we explore the ability of Transformers to fuse sentences and propose novel algorithms to enhance their ability to perform sentence fusion by leveraging the knowledge of points of correspondence between sentences. Through extensive experiments, we investigate the effects of different design choices on Transformer's performance. Our findings highlight the importance of modeling points of correspondence between sentences for effective sentence fusion.
A Cascade Approach to Neural Abstractive Summarization with Content Selection and Fusion
Oct 08, 2020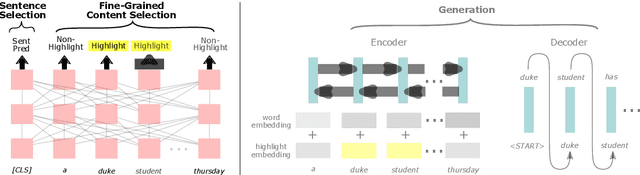
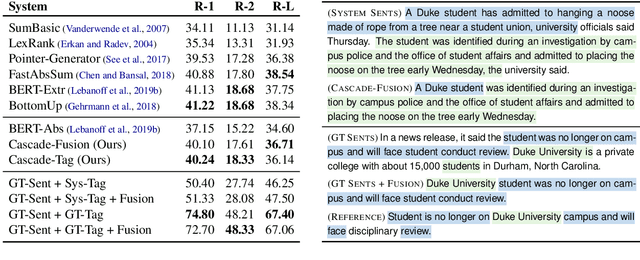
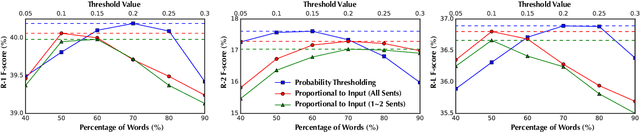
We present an empirical study in favor of a cascade architecture to neural text summarization. Summarization practices vary widely but few other than news summarization can provide a sufficient amount of training data enough to meet the requirement of end-to-end neural abstractive systems which perform content selection and surface realization jointly to generate abstracts. Such systems also pose a challenge to summarization evaluation, as they force content selection to be evaluated along with text generation, yet evaluation of the latter remains an unsolved problem. In this paper, we present empirical results showing that the performance of a cascaded pipeline that separately identifies important content pieces and stitches them together into a coherent text is comparable to or outranks that of end-to-end systems, whereas a pipeline architecture allows for flexible content selection. We finally discuss how we can take advantage of a cascaded pipeline in neural text summarization and shed light on important directions for future research.
Scene Graph Modification Based on Natural Language Commands
Oct 06, 2020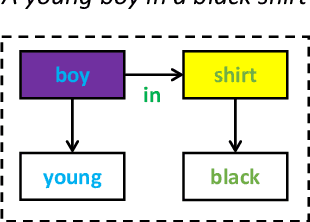
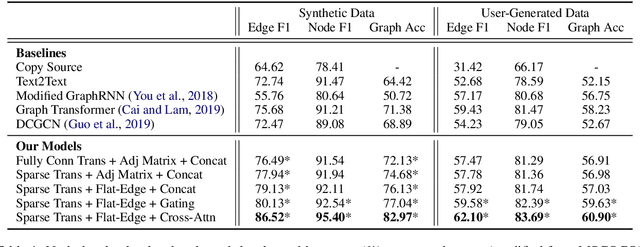
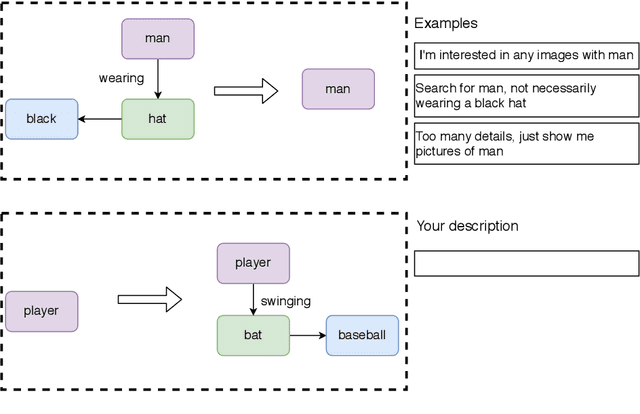
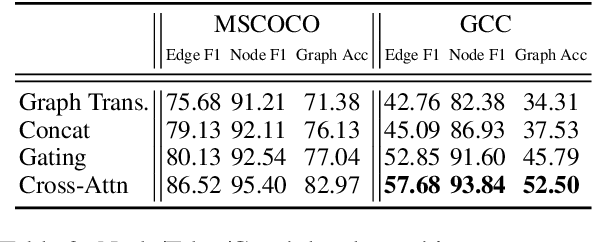
Structured representations like graphs and parse trees play a crucial role in many Natural Language Processing systems. In recent years, the advancements in multi-turn user interfaces necessitate the need for controlling and updating these structured representations given new sources of information. Although there have been many efforts focusing on improving the performance of the parsers that map text to graphs or parse trees, very few have explored the problem of directly manipulating these representations. In this paper, we explore the novel problem of graph modification, where the systems need to learn how to update an existing scene graph given a new user's command. Our novel models based on graph-based sparse transformer and cross attention information fusion outperform previous systems adapted from the machine translation and graph generation literature. We further contribute our large graph modification datasets to the research community to encourage future research for this new problem.
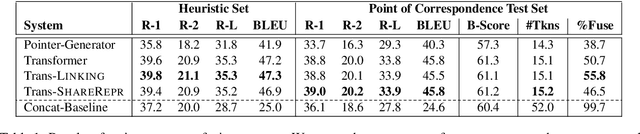
Understanding Points of Correspondence between Sentences for Abstractive Summarization
Jun 10, 2020
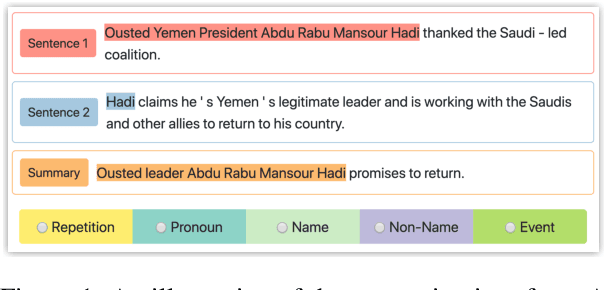
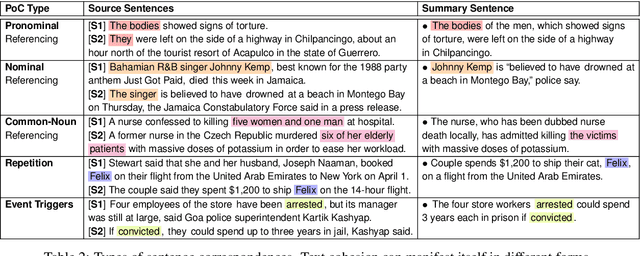

Fusing sentences containing disparate content is a remarkable human ability that helps create informative and succinct summaries. Such a simple task for humans has remained challenging for modern abstractive summarizers, substantially restricting their applicability in real-world scenarios. In this paper, we present an investigation into fusing sentences drawn from a document by introducing the notion of points of correspondence, which are cohesive devices that tie any two sentences together into a coherent text. The types of points of correspondence are delineated by text cohesion theory, covering pronominal and nominal referencing, repetition and beyond. We create a dataset containing the documents, source and fusion sentences, and human annotations of points of correspondence between sentences. Our dataset bridges the gap between coreference resolution and summarization. It is publicly shared to serve as a basis for future work to measure the success of sentence fusion systems. (https://github.com/ucfnlp/points-of-correspondence)