 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Attentional Framework for License Plate Recognition in the Wild
Jun 09, 2020

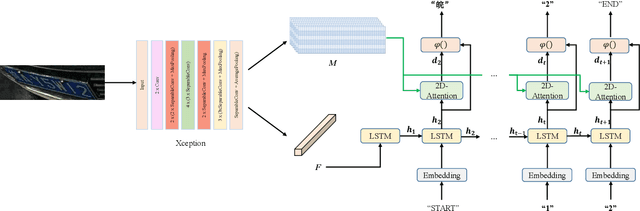
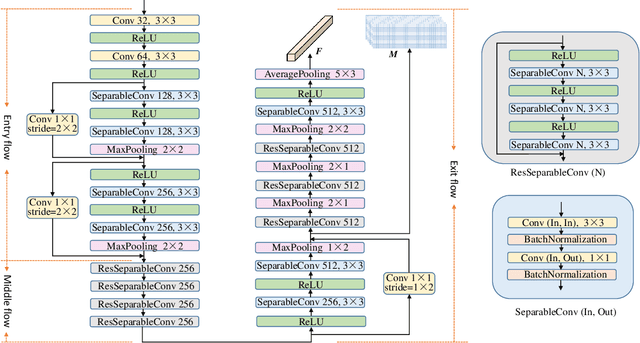
Recognizing car license plates in natural scene images is an important yet still challenging task in realistic applications. Many existing approaches perform well for license plates collected under constrained conditions, eg, shooting in frontal and horizontal view-angles and under good lighting conditions. However, their performance drops significantly in an unconstrained environment that features rotation, distortion, occlusion, blurring, shading or extreme dark or bright conditions. In this work, we propose a robust framework for license plate recognition in the wild. It is composed of a tailored CycleGAN model for license plate image generation and an elaborate designed image-to-sequence network for plate recognition. On one hand, the CycleGAN based plate generation engine alleviates the exhausting human annotation work. Massive amount of training data can be obtained with a more balanced character distribution and various shooting conditions, which helps to boost the recognition accuracy to a large extent. On the other hand, the 2D attentional based license plate recognizer with an Xception-based CNN encoder is capable of recognizing license plates with different patterns under various scenarios accurately and robustly. Without using any heuristics rule or post-processing, our method achieves the state-of-the-art performance on four public datasets, which demonstrates the generality and robustness of our framework. Moreover, we released a new license plate dataset, named "CLPD", with 1200 images from all 31 provinces in mainland China. The dataset can be available from: https://github.com/wangpengnorman/CLPD_dataset.
Unsupervised Depth Learning in Challenging Indoor Video: Weak Rectification to Rescue
Jun 04, 2020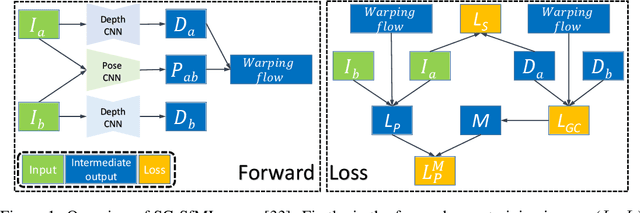
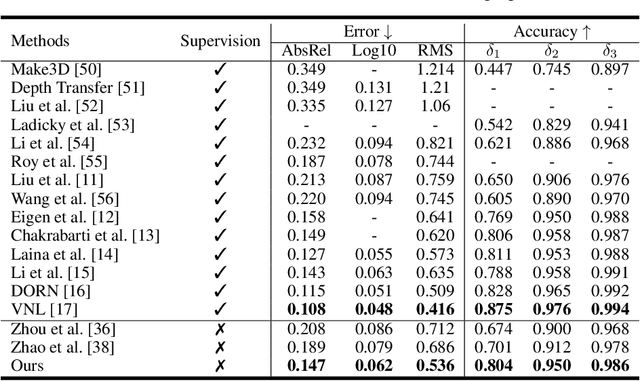
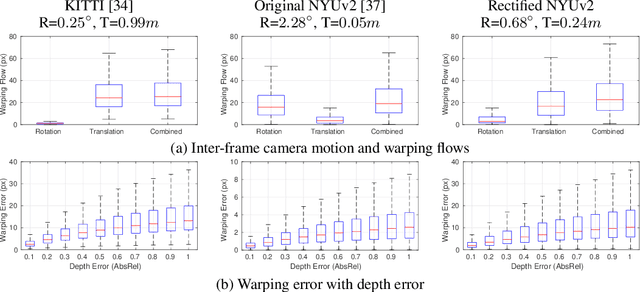
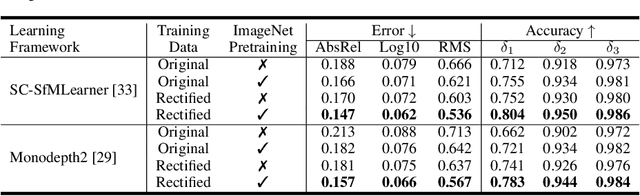
Single-view depth estimation using CNNs trained from unlabelled videos has shown significant promise. However, the excellent results have mostly been obtained in street-scene driving scenarios, and such methods often fail in other settings, particularly indoor videos taken by handheld devices, in which case the ego-motion is often degenerate, i.e., the rotation dominates the translation. In this work, we establish that the degenerate camera motions exhibited in handheld settings are a critical obstacle for unsupervised depth learning. A main contribution of our work is fundamental analysis which shows that the rotation behaves as noise during training, as opposed to the translation (baseline) which provides supervision signals. To capitalise on our findings, we propose a novel data pre-processing method for effective training, i.e., we search for image pairs with modest translation and remove their rotation via the proposed weak image rectification. With our pre-processing, existing unsupervised models can be trained well in challenging scenarios (e.g., NYUv2 dataset), and the results outperform the unsupervised SOTA by a large margin (0.147 vs. 0.189 in the AbsRel error).
Scope Head for Accurate Localization in Object Detection
May 12, 2020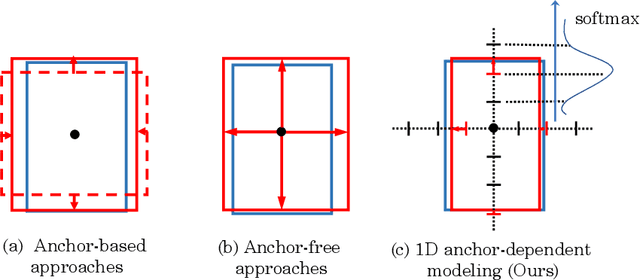

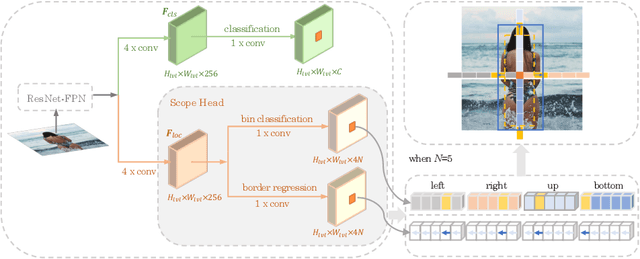
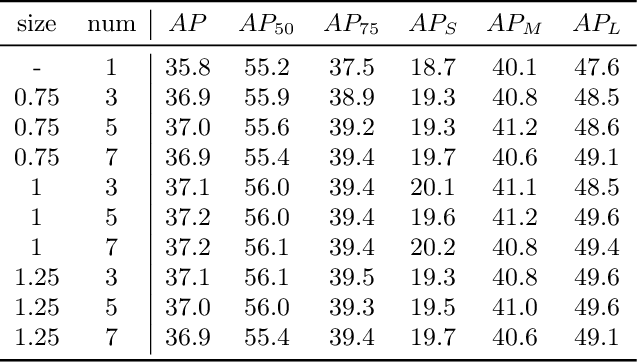
Existing anchor-based and anchor-free object detectors in multi-stage or one-stage pipelines have achieved very promising detection performance. However, they still encounter the design difficulty in hand-crafted 2D anchor definition and the learning complexity in 1D direct location regression. To tackle these issues, in this paper, we propose a novel detector coined as ScopeNet, which models anchors of each location as a mutually dependent relationship. This approach quantizes the prediction space and employs a coarse-to-fine strategy for localization. It achieves superior flexibility as in the regression based anchor-free methods, while produces more precise prediction. Besides, an inherit anchor selection score is learned to indicate the localization quality of the detection result, and we propose to better represent the confidence of a detection box by combining the category-classification score and the anchor-selection score. With our concise and effective design, the proposed ScopeNet achieves state-of-the-art results on COCO
Scene Text Image Super-Resolution in the Wild
May 07, 2020
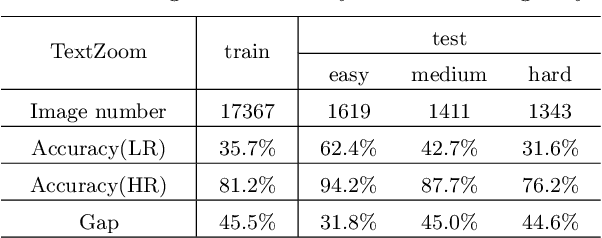
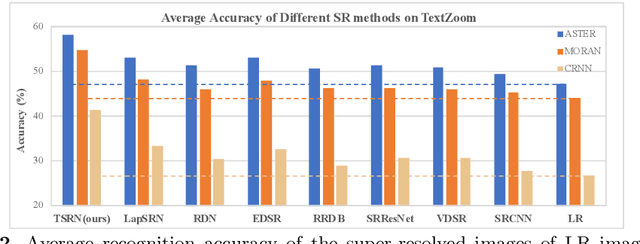
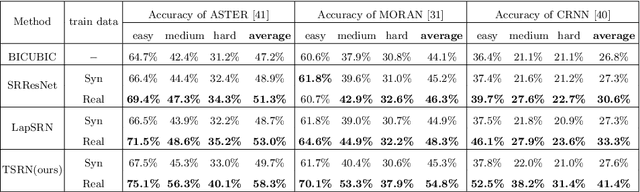
Low-resolution text images are often seen in natural scenes such as documents captured by mobile phones. Recognizing low-resolution text images is challenging because they lose detailed content information, leading to poor recognition accuracy. An intuitive solution is to introduce super-resolution (SR) techniques as pre-processing. However, previous single image super-resolution (SISR) methods are trained on synthetic low-resolution images (e.g.Bicubic down-sampling), which is simple and not suitable for real low-resolution text recognition. To this end, we pro-pose a real scene text SR dataset, termed TextZoom. It contains paired real low-resolution and high-resolution images which are captured by cameras with different focal length in the wild. It is more authentic and challenging than synthetic data, as shown in Fig. 1. We argue improv-ing the recognition accuracy is the ultimate goal for Scene Text SR. In this purpose, a new Text Super-Resolution Network termed TSRN, with three novel modules is developed. (1) A sequential residual block is proposed to extract the sequential information of the text images. (2) A boundary-aware loss is designed to sharpen the character boundaries. (3) A central alignment module is proposed to relieve the misalignment problem in TextZoom. Extensive experiments on TextZoom demonstrate that our TSRN largely improves the recognition accuracy by over 13%of CRNN, and by nearly 9.0% of ASTER and MORAN compared to synthetic SR data. Furthermore, our TSRN clearly outperforms 7 state-of-the-art SR methods in boosting the recognition accuracy of LR images in TextZoom. For example, it outperforms LapSRN by over 5% and 8%on the recognition accuracy of ASTER and CRNN. Our results suggest that low-resolution text recognition in the wild is far from being solved, thus more research effort is needed.
BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
Apr 05, 2020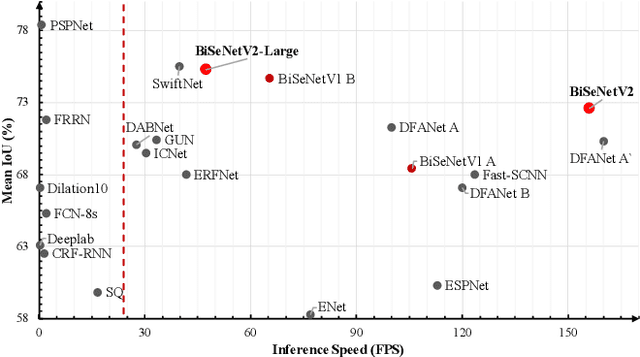
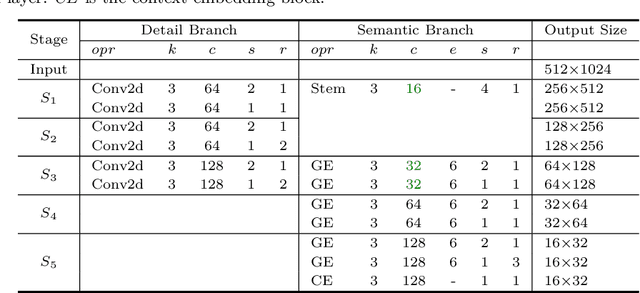
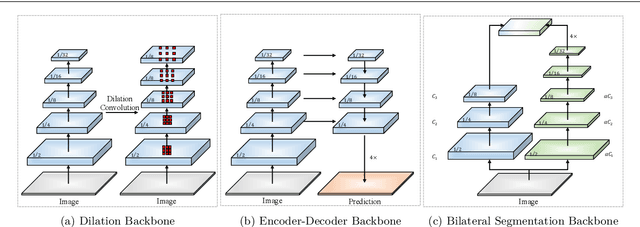
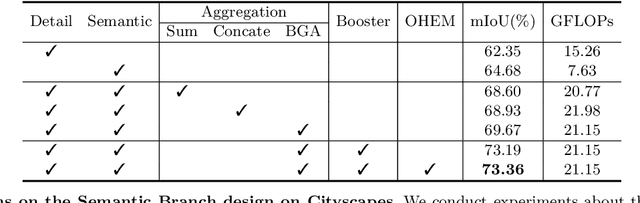
The low-level details and high-level semantics are both essential to the semantic segmentation task. However, to speed up the model inference, current approaches almost always sacrifice the low-level details, which leads to a considerable accuracy decrease. We propose to treat these spatial details and categorical semantics separately to achieve high accuracy and high efficiency for realtime semantic segmentation. To this end, we propose an efficient and effective architecture with a good trade-off between speed and accuracy, termed Bilateral Segmentation Network (BiSeNet V2). This architecture involves: (i) a Detail Branch, with wide channels and shallow layers to capture low-level details and generate high-resolution feature representation; (ii) a Semantic Branch, with narrow channels and deep layers to obtain high-level semantic context. The Semantic Branch is lightweight due to reducing the channel capacity and a fast-downsampling strategy. Furthermore, we design a Guided Aggregation Layer to enhance mutual connections and fuse both types of feature representation. Besides, a booster training strategy is designed to improve the segmentation performance without any extra inference cost. Extensive quantitative and qualitative evaluations demonstrate that the proposed architecture performs favourably against a few state-of-the-art real-time semantic segmentation approaches. Specifically, for a 2,048x1,024 input, we achieve 72.6% Mean IoU on the Cityscapes test set with a speed of 156 FPS on one NVIDIA GeForce GTX 1080 Ti card, which is significantly faster than existing methods, yet we achieve better segmentation accuracy.
Context Prior for Scene Segmentation
Apr 03, 2020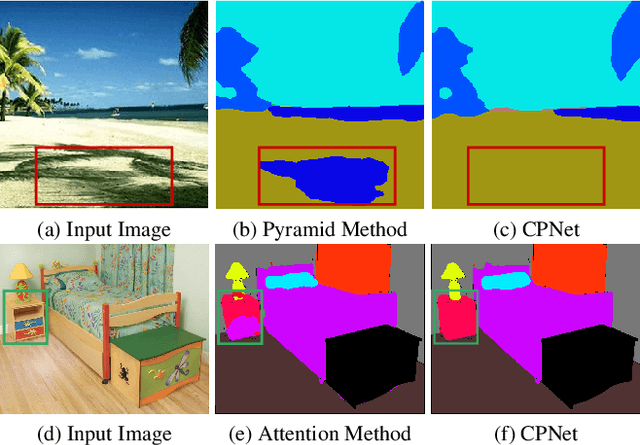
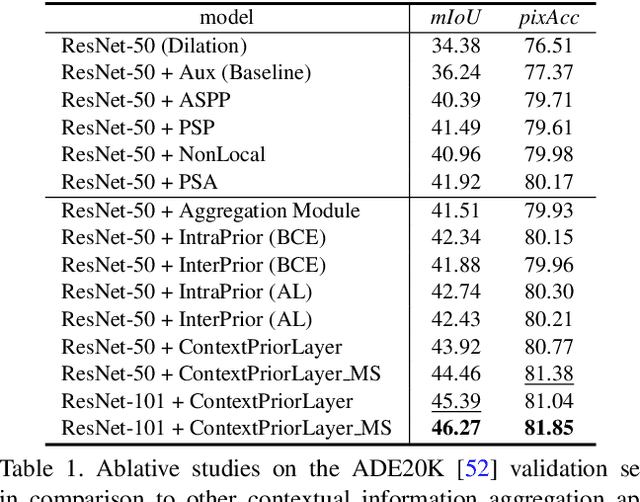
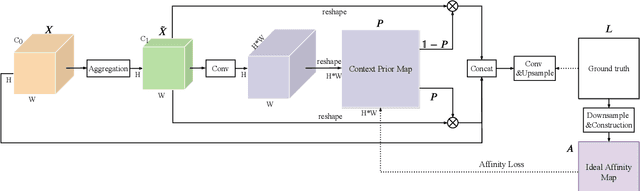
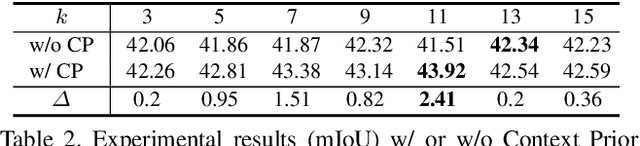
Recent works have widely explored the contextual dependencies to achieve more accurate segmentation results. However, most approaches rarely distinguish different types of contextual dependencies, which may pollute the scene understanding. In this work, we directly supervise the feature aggregation to distinguish the intra-class and inter-class context clearly. Specifically, we develop a Context Prior with the supervision of the Affinity Loss. Given an input image and corresponding ground truth, Affinity Loss constructs an ideal affinity map to supervise the learning of Context Prior. The learned Context Prior extracts the pixels belonging to the same category, while the reversed prior focuses on the pixels of different classes. Embedded into a conventional deep CNN, the proposed Context Prior Layer can selectively capture the intra-class and inter-class contextual dependencies, leading to robust feature representation. To validate the effectiveness, we design an effective Context Prior Network (CPNet). Extensive quantitative and qualitative evaluations demonstrate that the proposed model performs favorably against state-of-the-art semantic segmentation approaches. More specifically, our algorithm achieves 46.3% mIoU on ADE20K, 53.9% mIoU on PASCAL-Context, and 81.3% mIoU on Cityscapes. Code is available at https://git.io/ContextPrior.
* Accepted to CVPR 2020. Code is available at https://git.io/ContextPrior
Real-Time High-Performance Semantic Image Segmentation of Urban Street Scenes
Apr 03, 2020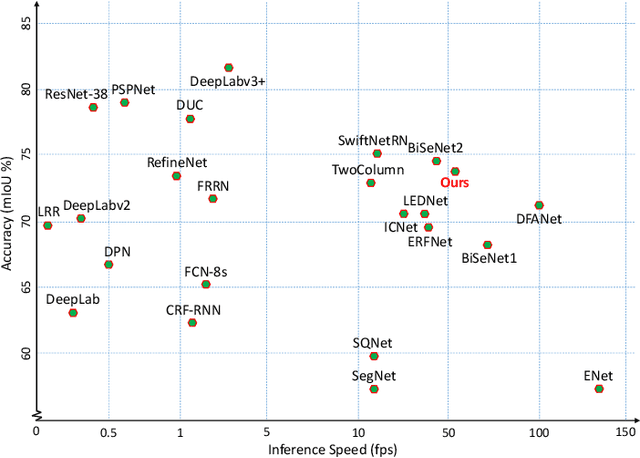


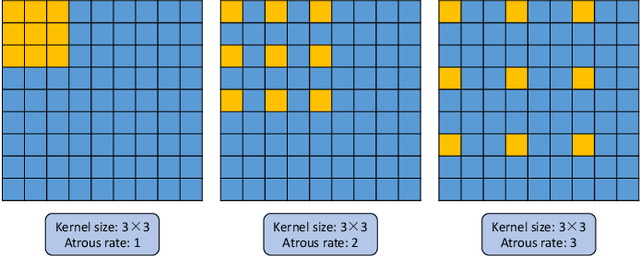
Deep Convolutional Neural Networks (DCNNs) have recently shown outstanding performance in semantic image segmentation. However, state-of-the-art DCNN-based semantic segmentation methods usually suffer from high computational complexity due to the use of complex network architectures. This greatly limits their applications in the real-world scenarios that require real-time processing. In this paper, we propose a real-time high-performance DCNN-based method for robust semantic segmentation of urban street scenes, which achieves a good trade-off between accuracy and speed. Specifically, a Lightweight Baseline Network with Atrous convolution and Attention (LBN-AA) is firstly used as our baseline network to efficiently obtain dense feature maps. Then, the Distinctive Atrous Spatial Pyramid Pooling (DASPP), which exploits the different sizes of pooling operations to encode the rich and distinctive semantic information, is developed to detect objects at multiple scales. Meanwhile, a Spatial detail-Preserving Network (SPN) with shallow convolutional layers is designed to generate high-resolution feature maps preserving the detailed spatial information. Finally, a simple but practical Feature Fusion Network (FFN) is used to effectively combine both shallow and deep features from the semantic branch (DASPP) and the spatial branch (SPN), respectively. Extensive experimental results show that the proposed method respectively achieves the accuracy of 73.6% and 68.0% mean Intersection over Union (mIoU) with the inference speed of 51.0 fps and 39.3 fps on the challenging Cityscapes and CamVid test datasets (by only using a single NVIDIA TITAN X card). This demonstrates that the proposed method offers excellent performance at the real-time speed for semantic segmentation of urban street scenes.
Segmenting Transparent Objects in the Wild
Mar 31, 2020

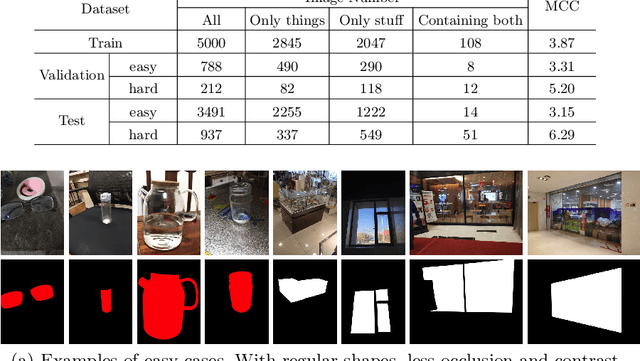
Transparent objects such as windows and bottles made by glass widely exist in the real world. Segmenting transparent objects is challenging because these objects have diverse appearance inherited from the image background, making them had similar appearance with their surroundings. Besides the technical difficulty of this task, only a few previous datasets were specially designed and collected to explore this task and most of the existing datasets have major drawbacks. They either possess limited sample size such as merely a thousand of images without manual annotations, or they generate all images by using computer graphics method (i.e. not real image). To address this important problem, this work proposes a large-scale dataset for transparent object segmentation, named Trans10K, consisting of 10,428 images of real scenarios with carefully manual annotations, which are 10 times larger than the existing datasets. The transparent objects in Trans10K are extremely challenging due to high diversity in scale, viewpoint and occlusion as shown in Fig. 1. To evaluate the effectiveness of Trans10K, we propose a novel boundary-aware segmentation method, termed TransLab, which exploits boundary as the clue to improve segmentation of transparent objects. Extensive experiments and ablation studies demonstrate the effectiveness of Trans10K and validate the practicality of learning object boundary in TransLab. For example, TransLab significantly outperforms 20 recent object segmentation methods based on deep learning, showing that this task is largely unsolved. We believe that both Trans10K and TransLab have important contributions to both the academia and industry, facilitating future researches and applications.
COVID-19 Screening on Chest X-ray Images Using Deep Learning based Anomaly Detection
Mar 27, 2020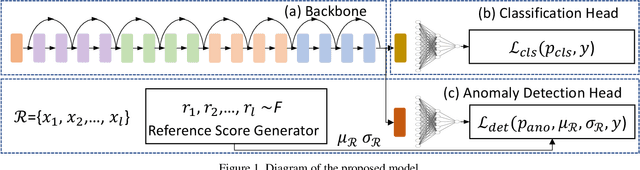
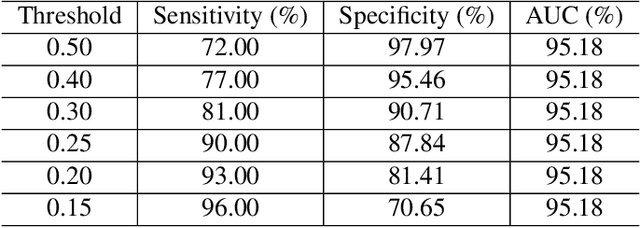
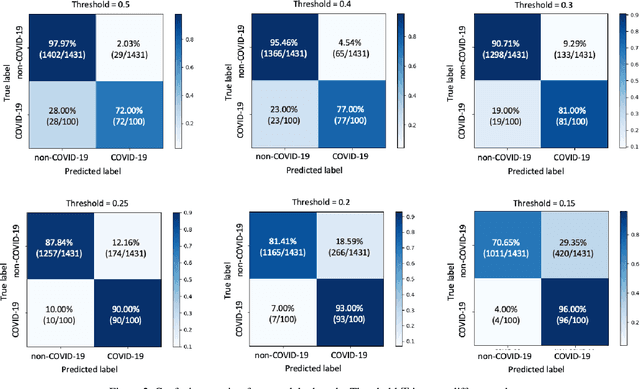
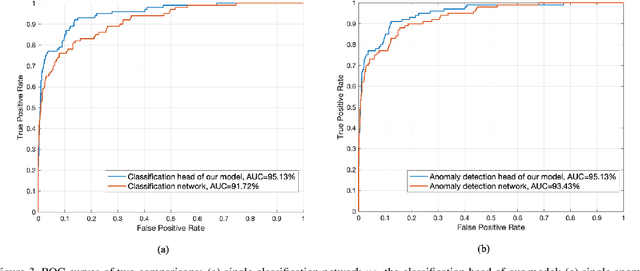
Coronaviruses are important human and animal pathogens. To date the novel COVID-19 coronavirus is rapidly spreading worldwide and subsequently threatening health of billions of humans. Clinical studies have shown that most COVID-19 patients suffer from the lung infection. Although chest CT has been shown to be an effective imaging technique for lung-related disease diagnosis, chest Xray is more widely available due to its faster imaging time and considerably lower cost than CT. Deep learning, one of the most successful AI techniques, is an effective means to assist radiologists to analyze the vast amount of chest X-ray images, which can be critical for efficient and reliable COVID-19 screening. In this work, we aim to develop a new deep anomaly detection model for fast, reliable screening. To evaluate the model performance, we have collected 100 chest X-ray images of 70 patients confirmed with COVID-19 from the Github repository. To facilitate deep learning, more data are needed. Thus, we have also collected 1431 additional chest X-ray images confirmed as other pneumonia of 1008 patients from the public ChestX-ray14 dataset. Our initial experimental results show that the model developed here can reliably detect 96.00% COVID-19 cases (sensitivity being 96.00%) and 70.65% non-COVID-19 cases (specificity being 70.65%) when evaluated on 1531 Xray images with two splits of the dataset.
Mask Encoding for Single Shot Instance Segmentation
Mar 26, 2020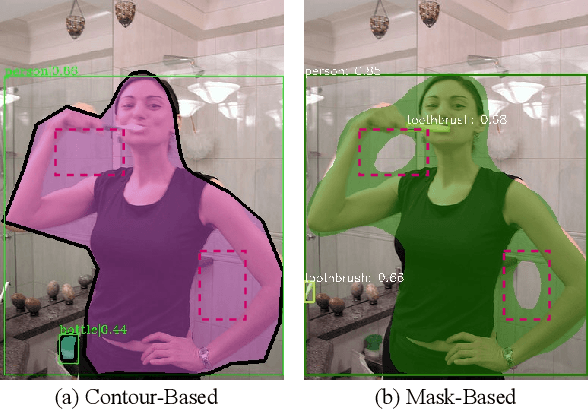

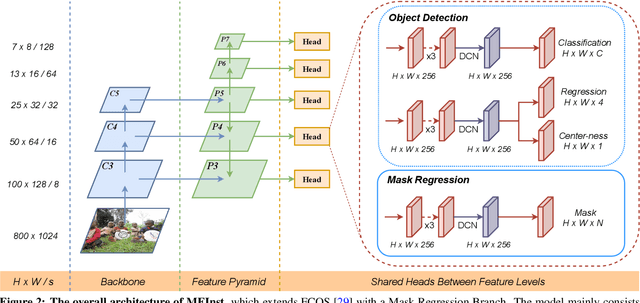

To date, instance segmentation is dominated by twostage methods, as pioneered by Mask R-CNN. In contrast, one-stage alternatives cannot compete with Mask R-CNN in mask AP, mainly due to the difficulty of compactly representing masks, making the design of one-stage methods very challenging. In this work, we propose a simple singleshot instance segmentation framework, termed mask encoding based instance segmentation (MEInst). Instead of predicting the two-dimensional mask directly, MEInst distills it into a compact and fixed-dimensional representation vector, which allows the instance segmentation task to be incorporated into one-stage bounding-box detectors and results in a simple yet efficient instance segmentation framework. The proposed one-stage MEInst achieves 36.4% in mask AP with single-model (ResNeXt-101-FPN backbone) and single-scale testing on the MS-COCO benchmark. We show that the much simpler and flexible one-stage instance segmentation method, can also achieve competitive performance. This framework can be easily adapted for other instance-level recognition tasks. Code is available at: https://git.io/AdelaiDet