 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Apr 04, 2024



Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.
Improving Multiple Sclerosis Lesion Segmentation Across Clinical Sites: A Federated Learning Approach with Noise-Resilient Training
Aug 31, 2023



Accurately measuring the evolution of Multiple Sclerosis (MS) with magnetic resonance imaging (MRI) critically informs understanding of disease progression and helps to direct therapeutic strategy. Deep learning models have shown promise for automatically segmenting MS lesions, but the scarcity of accurately annotated data hinders progress in this area. Obtaining sufficient data from a single clinical site is challenging and does not address the heterogeneous need for model robustness. Conversely, the collection of data from multiple sites introduces data privacy concerns and potential label noise due to varying annotation standards. To address this dilemma, we explore the use of the federated learning framework while considering label noise. Our approach enables collaboration among multiple clinical sites without compromising data privacy under a federated learning paradigm that incorporates a noise-robust training strategy based on label correction. Specifically, we introduce a Decoupled Hard Label Correction (DHLC) strategy that considers the imbalanced distribution and fuzzy boundaries of MS lesions, enabling the correction of false annotations based on prediction confidence. We also introduce a Centrally Enhanced Label Correction (CELC) strategy, which leverages the aggregated central model as a correction teacher for all sites, enhancing the reliability of the correction process. Extensive experiments conducted on two multi-site datasets demonstrate the effectiveness and robustness of our proposed methods, indicating their potential for clinical applications in multi-site collaborations.
MS Lesion Segmentation: Revisiting Weighting Mechanisms for Federated Learning
May 03, 2022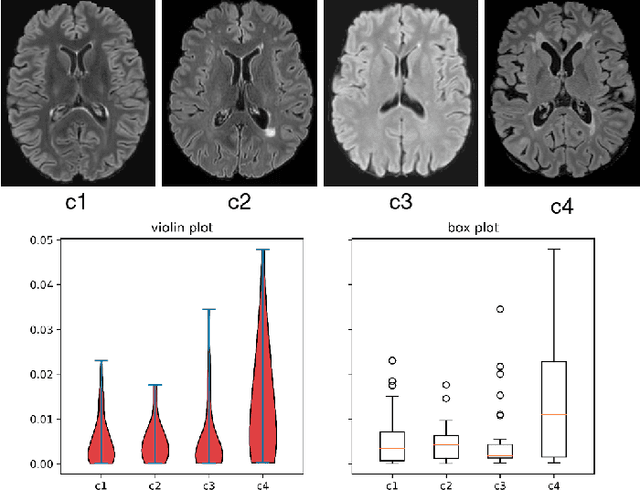
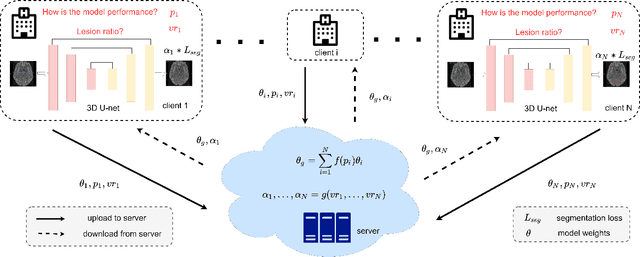
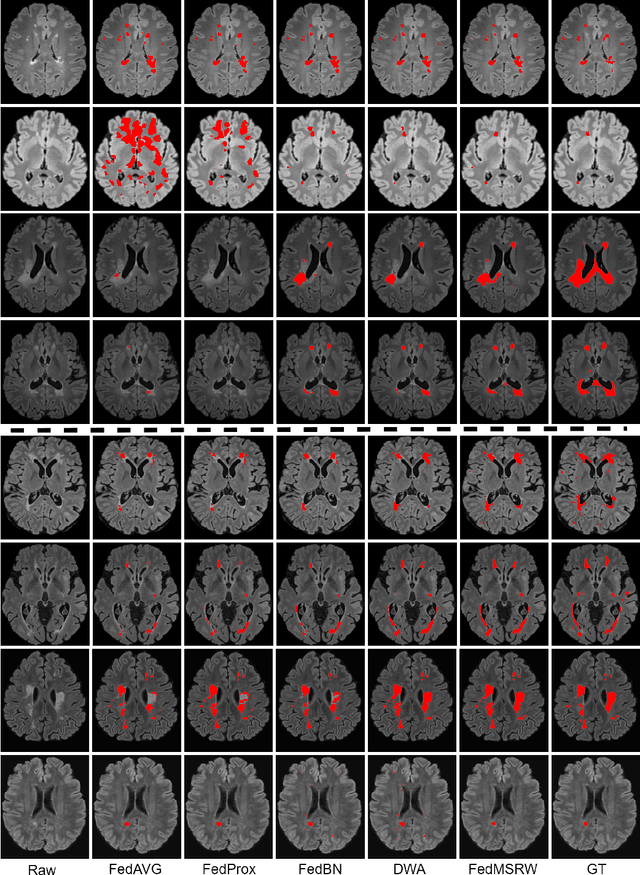

Federated learning (FL) has been widely employed for medical image analysis to facilitate multi-client collaborative learning without sharing raw data. Despite great success, FL's performance is limited for multiple sclerosis (MS) lesion segmentation tasks, due to variance in lesion characteristics imparted by different scanners and acquisition parameters. In this work, we propose the first FL MS lesion segmentation framework via two effective re-weighting mechanisms. Specifically, a learnable weight is assigned to each local node during the aggregation process, based on its segmentation performance. In addition, the segmentation loss function in each client is also re-weighted according to the lesion volume for the data during training. Comparison experiments on two FL MS segmentation scenarios using public and clinical datasets have demonstrated the effectiveness of the proposed method by outperforming other FL methods significantly. Furthermore, the segmentation performance of FL incorporating our proposed aggregation mechanism can exceed centralised training with all the raw data. The extensive evaluation also indicated the superiority of our method when estimating brain volume differences estimation after lesion inpainting.
Scope Head for Accurate Localization in Object Detection
May 12, 2020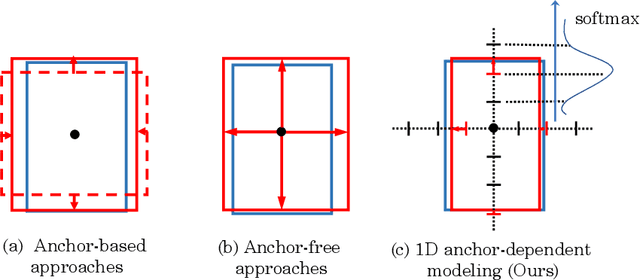

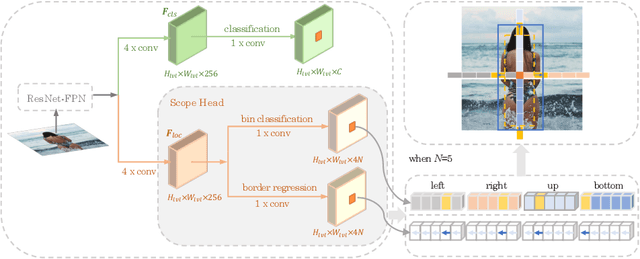
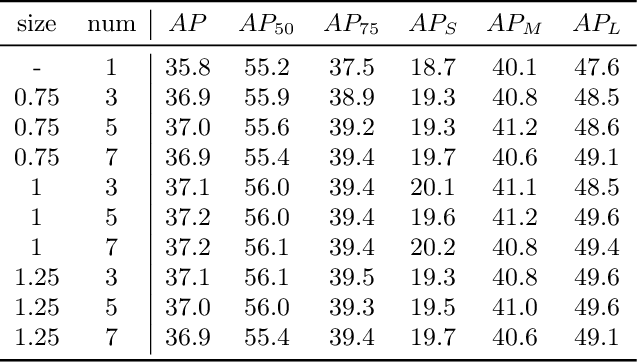
Existing anchor-based and anchor-free object detectors in multi-stage or one-stage pipelines have achieved very promising detection performance. However, they still encounter the design difficulty in hand-crafted 2D anchor definition and the learning complexity in 1D direct location regression. To tackle these issues, in this paper, we propose a novel detector coined as ScopeNet, which models anchors of each location as a mutually dependent relationship. This approach quantizes the prediction space and employs a coarse-to-fine strategy for localization. It achieves superior flexibility as in the regression based anchor-free methods, while produces more precise prediction. Besides, an inherit anchor selection score is learned to indicate the localization quality of the detection result, and we propose to better represent the confidence of a detection box by combining the category-classification score and the anchor-selection score. With our concise and effective design, the proposed ScopeNet achieves state-of-the-art results on COCO
ACFM: A Dynamic Spatial-Temporal Network for Traffic Prediction
Sep 02, 2019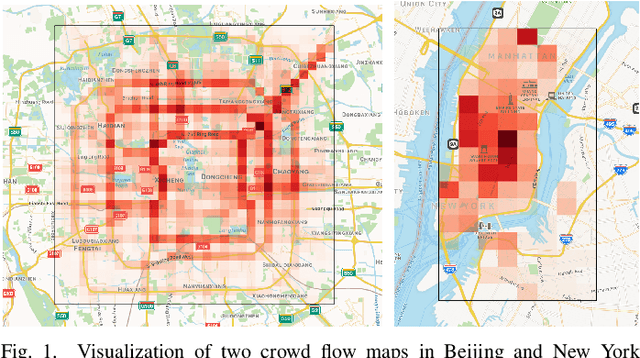
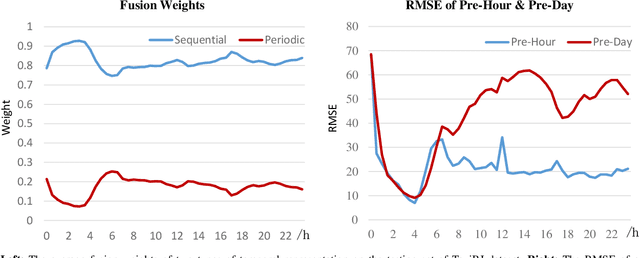
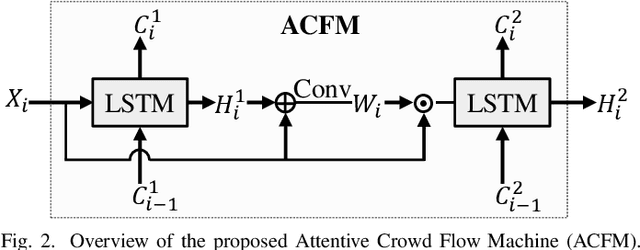
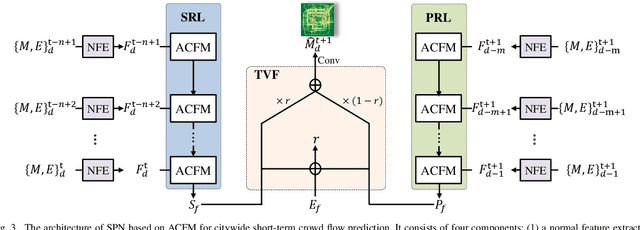
As a crucial component in intelligent transportation systems, crowd flow prediction has recently attracted widespread research interest in the field of artificial intelligence (AI) with the increasing availability of large-scale traffic mobility data. Its key challenge lies in how to integrate diverse factors (such as temporal laws and spatial dependencies) to infer the evolution trend of crowd flow. To address this problem, we propose a unified neural network called Attentive Crowd Flow Machine (ACFM), which can effectively learn the spatial-temporal feature representations of crowd flow with an attention mechanism. In particular, our ACFM is composed of two progressive ConvLSTM units connected with a convolutional layer. Specifically, the first LSTM unit takes normal crowd flow features as input and generates a hidden state at each time-step, which is further fed into the connected convolutional layer for spatial attention map inference. The second LSTM unit aims at learning the dynamic spatial-temporal representations from the attentionally weighted crowd flow features. Further, we develop two deep frameworks based on ACFM to predict citywide short-term/long-term crowd flow by adaptively incorporating the sequential and periodic data as well as other external influences. Extensive experiments on two standard benchmarks well demonstrate the superiority of the proposed method for crowd flow prediction. Moreover, to verify the generalization of our method, we also apply the customized framework to forecast the passenger pickup/dropoff demands and show its superior performance in this traffic prediction task.
Extended Local Binary Patterns for Efficient and Robust Spontaneous Facial Micro-Expression Recognition
Jul 22, 2019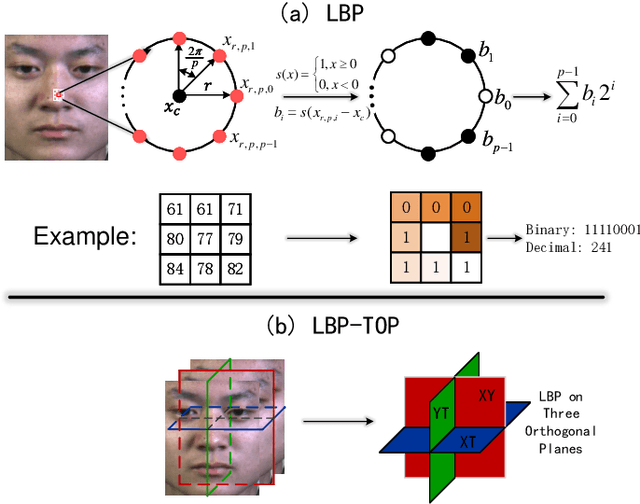
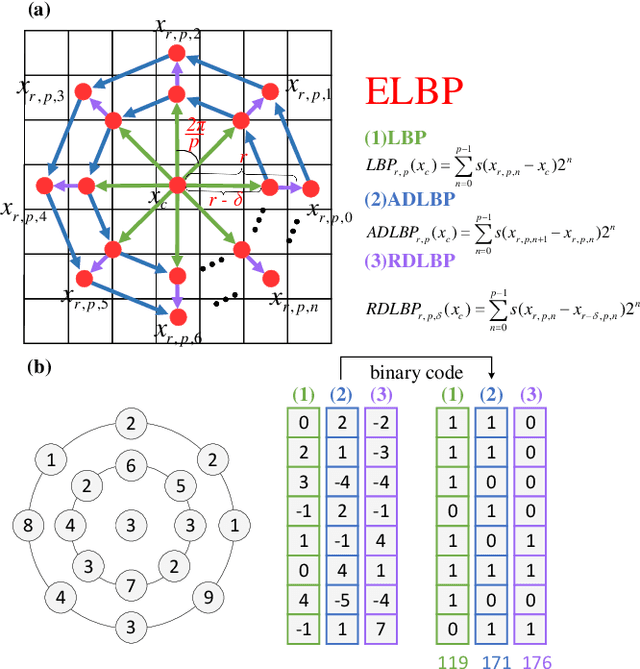
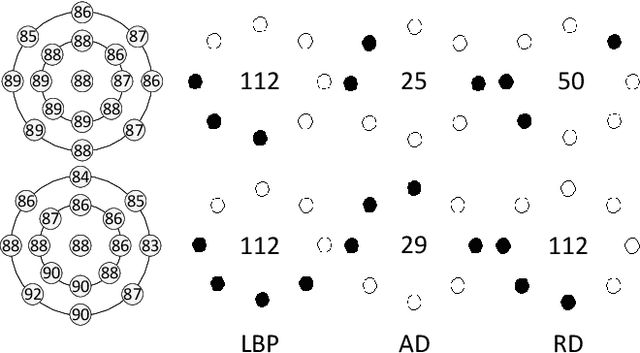
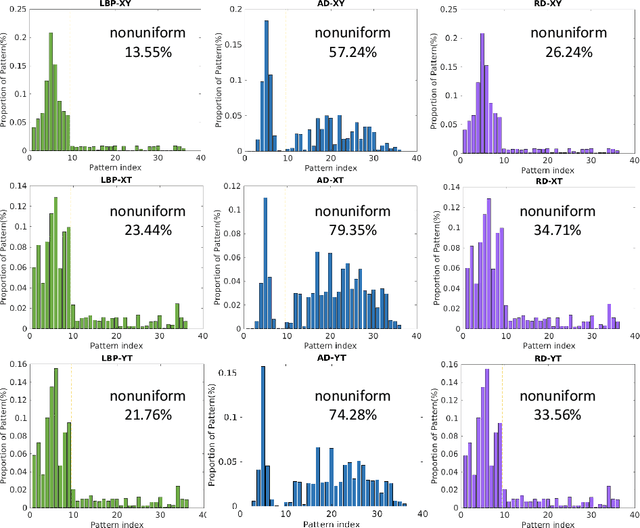
Facial MicroExpressions (MEs) are spontaneous, involuntary facial movements when a person experiences an emotion but deliberately or unconsciously attempts to conceal his or her genuine emotions. Recently, ME recognition has attracted increasing attention due to its potential applications such as clinical diagnosis, business negotiation, interrogations and security. However, it is expensive to build large scale ME datasets, mainly due to the difficulty of naturally inducing spontaneous MEs. This limits the application of deep learning techniques which require lots of training data. In this paper, we propose a simple, efficient yet robust descriptor called Extended Local Binary Patterns on Three Orthogonal Planes (ELBPTOP) for ME recognition. ELBPTOP consists of three complementary binary descriptors: LBPTOP and two novel ones Radial Difference LBPTOP (RDLBPTOP) and Angular Difference LBPTOP (ADLBPTOP), which explore the local second order information along radial and angular directions contained in ME video sequences. ELBPTOP is a novel ME descriptor inspired by the unique and subtle facial movements. It is computationally efficient and only marginally increases the cost of computing LBPTOP, yet is extremely effective for ME recognition. In addition, by firstly introducing Whitened Principal Component Analysis (WPCA) to ME recognition, we can further obtain more compact and discriminative feature representations, and achieve significantly computational savings. Extensive experimental evaluation on three popular spontaneous ME datasets SMIC, CASMEII and SAMM show that our proposed ELBPTOP approach significantly outperforms previous state of the art on all three evaluated datasets. Our proposed ELBPTOP achieves 73.94% on CASMEII, which is 6.6% higher than state of the art on this dataset. More impressively, ELBPTOP increases recognition accuracy from 44.7% to 63.44% on the SAMM dataset.