 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcessBench: Identifying Process Errors in Mathematical Reasoning
Dec 10, 2024



As language models regularly make mistakes when solving math problems, automated identification of errors in the reasoning process becomes increasingly significant for their scalable oversight. In this paper, we introduce ProcessBench for measuring the ability to identify erroneous steps in mathematical reasoning. It consists of 3,400 test cases, primarily focused on competition- and Olympiad-level math problems. Each test case contains a step-by-step solution with error location annotated by human experts. Models are required to identify the earliest step that contains an error, or conclude that all steps are correct. We conduct extensive evaluation on ProcessBench, involving two types of models: process reward models (PRMs) and critic models, where for the latter we prompt general language models to critique each solution step by step. We draw two main observations: (1) Existing PRMs typically fail to generalize to more challenging math problems beyond GSM8K and MATH. They underperform both critic models (i.e., prompted general language models) and our own trained PRM that is straightforwardly fine-tuned on the PRM800K dataset. (2) The best open-source model, QwQ-32B-Preview, has demonstrated the critique capability competitive with the proprietary model GPT-4o, despite that it still lags behind the reasoning-specialized o1-mini. We hope ProcessBench can foster future research in reasoning process assessment, paving the way toward scalable oversight of language models.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
Semantic Search Evaluation
Oct 28, 2024



We propose a novel method for evaluating the performance of a content search system that measures the semantic match between a query and the results returned by the search system. We introduce a metric called "on-topic rate" to measure the percentage of results that are relevant to the query. To achieve this, we design a pipeline that defines a golden query set, retrieves the top K results for each query, and sends calls to GPT 3.5 with formulated prompts. Our semantic evaluation pipeline helps identify common failure patterns and goals against the metric for relevance improvements.
Safe Unlearning: A Surprisingly Effective and Generalizable Solution to Defend Against Jailbreak Attacks
Jul 03, 2024



LLMs are known to be vulnerable to jailbreak attacks, even after safety alignment. An important observation is that, while different types of jailbreak attacks can generate significantly different queries, they mostly result in similar responses that are rooted in the same harmful knowledge (e.g., detailed steps to make a bomb). Therefore, we conjecture that directly unlearn the harmful knowledge in the LLM can be a more effective way to defend against jailbreak attacks than the mainstream supervised fine-tuning (SFT) based approaches. Our extensive experiments confirmed our insight and suggested surprising generalizability of our unlearning-based approach: using only 20 raw harmful questions \emph{without} any jailbreak prompt during training, our solution reduced the Attack Success Rate (ASR) in Vicuna-7B on \emph{out-of-distribution} (OOD) harmful questions wrapped with various complex jailbreak prompts from 82.6\% to 7.7\%. This significantly outperforms Llama2-7B-Chat, which is fine-tuned on about 0.1M safety alignment samples but still has an ASR of 21.9\% even under the help of an additional safety system prompt. Further analysis reveals that the generalization ability of our solution stems from the intrinsic relatedness among harmful responses across harmful questions (e.g., response patterns, shared steps and actions, and similarity among their learned representations in the LLM). Our code is available at \url{https://github.com/thu-coai/SafeUnlearning}.
Weak-to-Strong Extrapolation Expedites Alignment
Apr 25, 2024



Although the capabilities of large language models (LLMs) ideally scale up with increasing data and compute, they are inevitably constrained by limited resources in reality. Suppose we have a moderately trained LLM (e.g., trained to align with human preference) in hand, can we further exploit its potential and cheaply acquire a stronger model? In this paper, we propose a simple method called ExPO to boost LLMs' alignment with human preference. ExPO assumes that a medium-aligned model can be interpolated between a less-aligned (weaker) model, e.g., the initial SFT model, and a better-aligned (stronger) one, thereby directly obtaining this stronger model by extrapolating from the weights of the former two relatively weaker models. On the AlpacaEval 2.0 benchmark, we show that ExPO pushes models trained with less preference data (e.g., 10% or 20%) to reach and even surpass the fully-trained one, without any additional training. Furthermore, ExPO also significantly improves off-the-shelf DPO/RLHF models and exhibits decent scalability across model sizes from 7B to 70B. Our work demonstrates the efficacy of model extrapolation in exploiting LLMs' capabilities, suggesting a promising direction that deserves future exploration.
Prompt-Driven LLM Safeguarding via Directed Representation Optimization
Jan 31, 2024



Prepending model inputs with safety prompts is a common practice of safeguarding large language models (LLMs) from complying with queries that contain harmful intents. However, the working mechanisms of safety prompts have not yet been fully understood, which hinders the potential for automatically optimizing them for improved LLM safety. Motivated by this problem, we investigate the impact of safety prompts from the perspective of model representations. We find that in models' representation space, harmful and harmless queries can be largely distinguished, but this is not noticeably enhanced by safety prompts. Instead, the queries' representations are moved by different safety prompts in similar directions, where models become more prone to refusal (i.e., refusing to provide assistance) even when the queries are harmless. Inspired by these findings, we propose a method called DRO (Directed Representation Optimization) for automatic safety prompt optimization. DRO treats safety prompts as continuous, trainable embeddings and learns to move the representations of harmful/harmless queries along/opposite the direction in which the model's refusal probability increases. We demonstrate that DRO remarkably improves the safeguarding performance of human-crafted safety prompts and outperforms strong baselines, as evaluated on out-of-domain benchmarks, without compromising the general model capability.
On Large Language Models' Selection Bias in Multi-Choice Questions
Sep 08, 2023



Multi-choice questions (MCQs) serve as a common yet important task format in the research of large language models (LLMs). Our work shows that LLMs exhibit an inherent "selection bias" in MCQs, which refers to LLMs' preferences to select options located at specific positions (like "Option C"). This bias is prevalent across various LLMs, making their performance vulnerable to option position changes in MCQs. We identify that one primary cause resulting in selection bias is option numbering, i.e., the ID symbols A/B/C/D associated with the options. To mitigate selection bias, we propose a new method called PriDe. PriDe first decomposes the observed model prediction distribution into an intrinsic prediction over option contents and a prior distribution over option IDs. It then estimates the prior by permutating option contents on a small number of test samples, which is used to debias the subsequent test samples. We demonstrate that, as a label-free, inference-time method, PriDe achieves a more effective and computation-efficient debiasing than strong baselines. We further show that the priors estimated by PriDe generalize well across different domains, highlighting its practical potential in broader scenarios.
Click: Controllable Text Generation with Sequence Likelihood Contrastive Learning
Jun 06, 2023



It has always been an important yet challenging problem to control language models to avoid generating texts with undesirable attributes, such as toxic language and unnatural repetition. We introduce Click for controllable text generation, which needs no modification to the model architecture and facilitates out-of-the-box use of trained models. It employs a contrastive loss on sequence likelihood, which fundamentally decreases the generation probability of negative samples (i.e., generations with undesirable attributes). It also adopts a novel likelihood ranking-based strategy to construct contrastive samples from model generations. On the tasks of language detoxification, sentiment steering, and repetition reduction, we show that Click outperforms strong baselines of controllable text generation and demonstrate the superiority of Click's sample construction strategy.
CDConv: A Benchmark for Contradiction Detection in Chinese Conversations
Oct 16, 2022
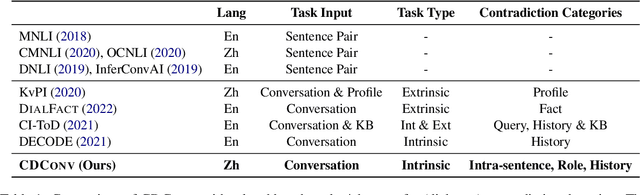

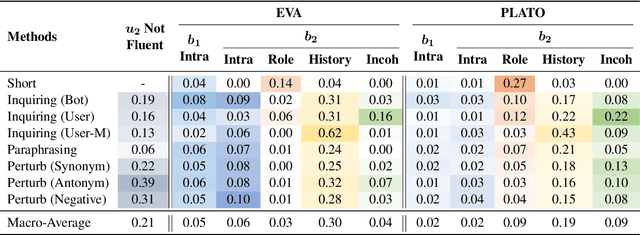
Dialogue contradiction is a critical issue in open-domain dialogue systems. The contextualization nature of conversations makes dialogue contradiction detection rather challenging. In this work, we propose a benchmark for Contradiction Detection in Chinese Conversations, namely CDConv. It contains 12K multi-turn conversations annotated with three typical contradiction categories: Intra-sentence Contradiction, Role Confusion, and History Contradiction. To efficiently construct the CDConv conversations, we devise a series of methods for automatic conversation generation, which simulate common user behaviors that trigger chatbots to make contradictions. We conduct careful manual quality screening of the constructed conversations and show that state-of-the-art Chinese chatbots can be easily goaded into making contradictions. Experiments on CDConv show that properly modeling contextual information is critical for dialogue contradiction detection, but there are still unresolved challenges that require future research.
CASE: Aligning Coarse-to-Fine Cognition and Affection for Empathetic Response Generation
Aug 18, 2022
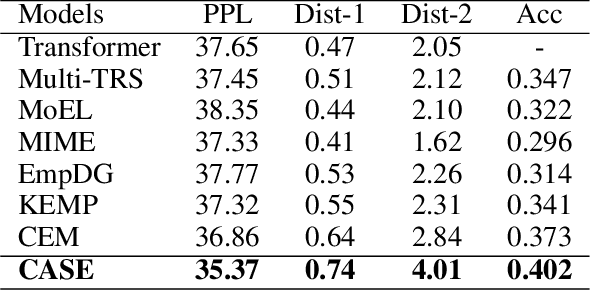
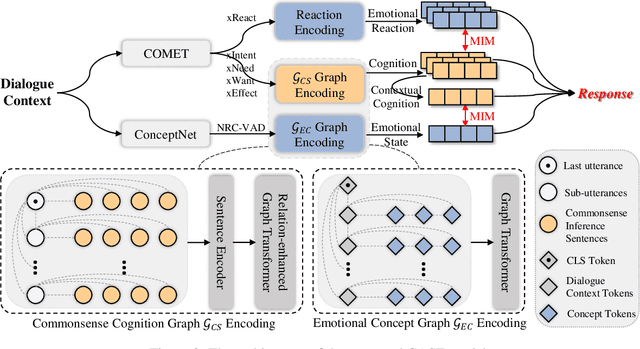
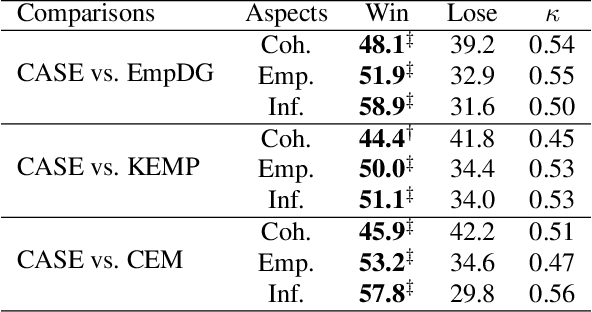
Empathy is a trait that naturally manifests in human conversation. Theoretically, the birth of empathetic responses results from conscious alignment and interaction between cognition and affection of empathy. However, existing works rely solely on a single affective aspect or model cognition and affection independently, limiting the empathetic capabilities of the generated responses. To this end, based on the commonsense cognition graph and emotional concept graph constructed involving commonsense and concept knowledge, we design a two-level strategy to align coarse-grained (between contextual cognition and contextual emotional state) and fine-grained (between each specific cognition and corresponding emotional reaction) Cognition and Affection for reSponding Empathetically (CASE). Extensive experiments demonstrate that CASE outperforms the state-of-the-art baselines on automatic and human evaluation. Our code will be released.