 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLLM-Searcher: Adapting Diffusion Large Language Model for Search Agents
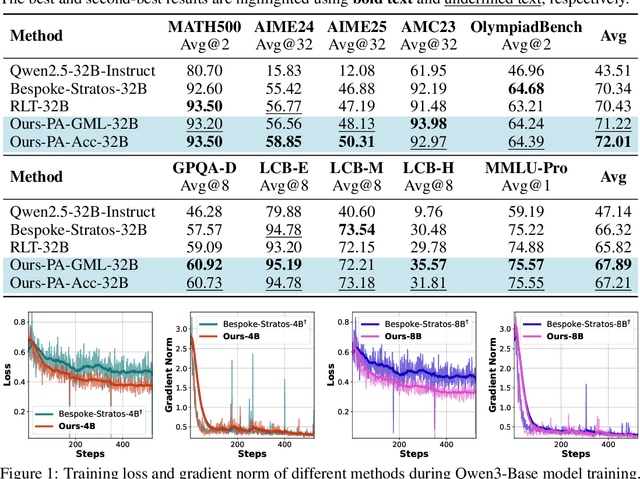
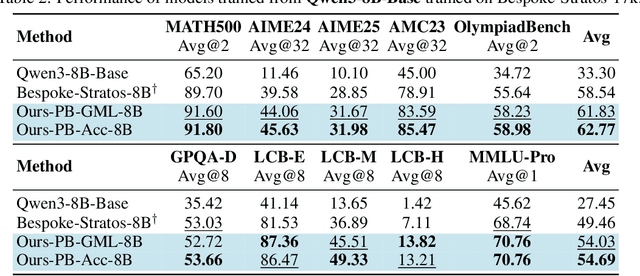
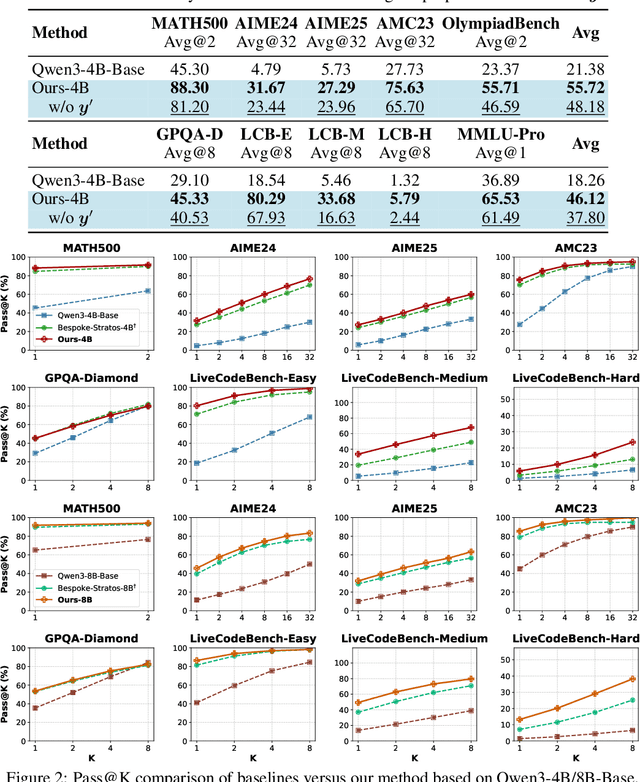
Feb 03, 2026Recently, Diffusion Large Language Models (dLLMs) have demonstrated unique efficiency advantages, enabled by their inherently parallel decoding mechanism and flexible generation paradigm. Meanwhile, despite the rapid advancement of Search Agents, their practical deployment is constrained by a fundamental limitation, termed as 1) Latency Challenge: the serial execution of multi-round reasoning, tool calling, and tool response waiting under the ReAct agent paradigm induces severe end-to-end latency. Intuitively, dLLMs can leverage their distinctive strengths to optimize the operational efficiency of agents under the ReAct agent paradigm. Practically, existing dLLM backbones face the 2) Agent Ability Challenge. That is, existing dLLMs exhibit remarkably weak reasoning and tool-calling capabilities, preventing these advantages from being effectively realized in practice. In this paper, we propose DLLM-Searcher, an optimization framework for dLLM-based Search Agents. To solve the Agent Ability Challenge, we design a two-stage post-training pipeline encompassing Agentic Supervised Fine-Tuning (Agentic SFT) and Agentic Variance-Reduced Preference Optimization Agentic VRPO, which enhances the backbone dLLM's information seeking and reasoning capabilities. To mitigate the Latency Challenge, we leverage the flexible generation mechanism of dLLMs and propose a novel agent paradigm termed Parallel-Reasoning and Acting P-ReAct. P-ReAct guides the model to prioritize decoding tool_call instructions, thereby allowing the model to keep thinking while waiting for the tool's return. Experimental results demonstrate that DLLM-Searcher achieves performance comparable to mainstream LLM-based search agents and P-ReAct delivers approximately 15% inference acceleration. Our code is available at https://anonymous.4open.science/r/DLLM-Searcher-553C
Optimization and Generation in Aerodynamics Inverse Design
Feb 03, 2026Inverse design with physics-based objectives is challenging because it couples high-dimensional geometry with expensive simulations, as exemplified by aerodynamic shape optimization for drag reduction. We revisit inverse design through two canonical solutions, the optimal design point and the optimal design distribution, and relate them to optimization and guided generation. Building on this view, we propose a new training loss for cost predictors and a density-gradient optimization method that improves objectives while preserving plausible shapes. We further unify existing training-free guided generation methods. To address their inability to approximate conditional covariance in high dimensions, we develop a time- and memory-efficient algorithm for approximate covariance estimation. Experiments on a controlled 2D study and high-fidelity 3D aerodynamic benchmarks (car and aircraft), validated by OpenFOAM simulations and miniature wind-tunnel tests with 3D-printed prototypes, demonstrate consistent gains in both optimization and guided generation. Additional offline RL results further support the generality of our approach.
Causal Forcing: Autoregressive Diffusion Distillation Done Right for High-Quality Real-Time Interactive Video Generation
Feb 02, 2026To achieve real-time interactive video generation, current methods distill pretrained bidirectional video diffusion models into few-step autoregressive (AR) models, facing an architectural gap when full attention is replaced by causal attention. However, existing approaches do not bridge this gap theoretically. They initialize the AR student via ODE distillation, which requires frame-level injectivity, where each noisy frame must map to a unique clean frame under the PF-ODE of an AR teacher. Distilling an AR student from a bidirectional teacher violates this condition, preventing recovery of the teacher's flow map and instead inducing a conditional-expectation solution, which degrades performance. To address this issue, we propose Causal Forcing that uses an AR teacher for ODE initialization, thereby bridging the architectural gap. Empirical results show that our method outperforms all baselines across all metrics, surpassing the SOTA Self Forcing by 19.3\% in Dynamic Degree, 8.7\% in VisionReward, and 16.7\% in Instruction Following. Project page and the code: \href{https://thu-ml.github.io/CausalForcing.github.io/}{https://thu-ml.github.io/CausalForcing.github.io/}
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
Dec 15, 2025



Autoregressive models (ARMs) are hindered by slow sequential inference. While masked diffusion models (MDMs) offer a parallel alternative, they suffer from critical drawbacks: high computational overhead from precluding Key-Value (KV) caching, and incoherent generation arising from learning dependencies over an intractable space of token combinations. To address these limitations, we introduce ReFusion, a novel masked diffusion model that achieves superior performance and efficiency by elevating parallel decoding from the token level to a higher slot level, where each slot is a fixed-length, contiguous sub-sequence. This is achieved through an iterative ``plan-and-infill'' decoding process: a diffusion-based planning step first identifies a set of weakly dependent slots, and an autoregressive infilling step then decodes these selected slots in parallel. The slot-based design simultaneously unlocks full KV cache reuse with a unified causal framework and reduces the learning complexity from the token combination space to a manageable slot-level permutation space. Extensive experiments on seven diverse benchmarks show that ReFusion not only overwhelmingly surpasses prior MDMs with 34% performance gains and an over 18$\times$ speedup on average, but also bridges the performance gap to strong ARMs while maintaining a 2.33$\times$ average speedup.
Saying the Unsaid: Revealing the Hidden Language of Multimodal Systems Through Telephone Games
Nov 12, 2025



Recent closed-source multimodal systems have made great advances, but their hidden language for understanding the world remains opaque because of their black-box architectures. In this paper, we use the systems' preference bias to study their hidden language: During the process of compressing the input images (typically containing multiple concepts) into texts and then reconstructing them into images, the systems' inherent preference bias introduces specific shifts in the outputs, disrupting the original input concept co-occurrence. We employ the multi-round "telephone game" to strategically leverage this bias. By observing the co-occurrence frequencies of concepts in telephone games, we quantitatively investigate the concept connection strength in the understanding of multimodal systems, i.e., "hidden language." We also contribute Telescope, a dataset of 10,000+ concept pairs, as the database of our telephone game framework. Our telephone game is test-time scalable: By iteratively running telephone games, we can construct a global map of concept connections in multimodal systems' understanding. Here we can identify preference bias inherited from training, assess generalization capability advancement, and discover more stable pathways for fragile concept connections. Furthermore, we use Reasoning-LLMs to uncover unexpected concept relationships that transcend textual and visual similarities, inferring how multimodal systems understand and simulate the world. This study offers a new perspective on the hidden language of multimodal systems and lays the foundation for future research on the interpretability and controllability of multimodal systems.
LLaDA-Rec: Discrete Diffusion for Parallel Semantic ID Generation in Generative Recommendation
Nov 09, 2025Generative recommendation represents each item as a semantic ID, i.e., a sequence of discrete tokens, and generates the next item through autoregressive decoding. While effective, existing autoregressive models face two intrinsic limitations: (1) unidirectional constraints, where causal attention restricts each token to attend only to its predecessors, hindering global semantic modeling; and (2) error accumulation, where the fixed left-to-right generation order causes prediction errors in early tokens to propagate to the predictions of subsequent token. To address these issues, we propose LLaDA-Rec, a discrete diffusion framework that reformulates recommendation as parallel semantic ID generation. By combining bidirectional attention with the adaptive generation order, the approach models inter-item and intra-item dependencies more effectively and alleviates error accumulation. Specifically, our approach comprises three key designs: (1) a parallel tokenization scheme that produces semantic IDs for bidirectional modeling, addressing the mismatch between residual quantization and bidirectional architectures; (2) two masking mechanisms at the user-history and next-item levels to capture both inter-item sequential dependencies and intra-item semantic relationships; and (3) an adapted beam search strategy for adaptive-order discrete diffusion decoding, resolving the incompatibility of standard beam search with diffusion-based generation. Experiments on three real-world datasets show that LLaDA-Rec consistently outperforms both ID-based and state-of-the-art generative recommenders, establishing discrete diffusion as a new paradigm for generative recommendation.
Variational Reasoning for Language Models
Sep 26, 2025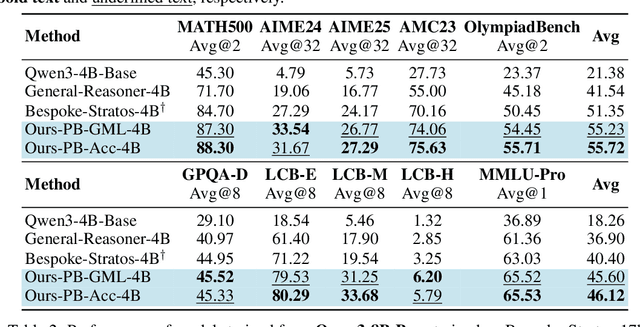
We introduce a variational reasoning framework for language models that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. We further show that rejection sampling finetuning and binary-reward RL, including GRPO, can be interpreted as local forward-KL objectives, where an implicit weighting by model accuracy naturally arises from the derivation and reveals a previously unnoticed bias toward easier questions. We empirically validate our method on the Qwen 2.5 and Qwen 3 model families across a wide range of reasoning tasks. Overall, our work provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of language models. Our code is available at https://github.com/sail-sg/variational-reasoning.
Masked Diffusion Models as Energy Minimization
Sep 17, 2025



We present a systematic theoretical framework that interprets masked diffusion models (MDMs) as solutions to energy minimization problems in discrete optimal transport. Specifically, we prove that three distinct energy formulations--kinetic, conditional kinetic, and geodesic energy--are mathematically equivalent under the structure of MDMs, and that MDMs minimize all three when the mask schedule satisfies a closed-form optimality condition. This unification not only clarifies the theoretical foundations of MDMs, but also motivates practical improvements in sampling. By parameterizing interpolation schedules via Beta distributions, we reduce the schedule design space to a tractable 2D search, enabling efficient post-training tuning without model modification. Experiments on synthetic and real-world benchmarks demonstrate that our energy-inspired schedules outperform hand-crafted baselines, particularly in low-step sampling settings.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.