 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Diffusion Models as Energy Minimization
Sep 17, 2025



We present a systematic theoretical framework that interprets masked diffusion models (MDMs) as solutions to energy minimization problems in discrete optimal transport. Specifically, we prove that three distinct energy formulations--kinetic, conditional kinetic, and geodesic energy--are mathematically equivalent under the structure of MDMs, and that MDMs minimize all three when the mask schedule satisfies a closed-form optimality condition. This unification not only clarifies the theoretical foundations of MDMs, but also motivates practical improvements in sampling. By parameterizing interpolation schedules via Beta distributions, we reduce the schedule design space to a tractable 2D search, enabling efficient post-training tuning without model modification. Experiments on synthetic and real-world benchmarks demonstrate that our energy-inspired schedules outperform hand-crafted baselines, particularly in low-step sampling settings.
ChineseEEG-2: An EEG Dataset for Multimodal Semantic Alignment and Neural Decoding during Reading and Listening
Aug 06, 2025EEG-based neural decoding requires large-scale benchmark datasets. Paired brain-language data across speaking, listening, and reading modalities are essential for aligning neural activity with the semantic representation of large language models (LLMs). However, such datasets are rare, especially for non-English languages. Here, we present ChineseEEG-2, a high-density EEG dataset designed for benchmarking neural decoding models under real-world language tasks. Building on our previous ChineseEEG dataset, which focused on silent reading, ChineseEEG-2 adds two active modalities: Reading Aloud (RA) and Passive Listening (PL), using the same Chinese corpus. EEG and audio were simultaneously recorded from four participants during ~10.7 hours of reading aloud. These recordings were then played to eight other participants, collecting ~21.6 hours of EEG during listening. This setup enables speech temporal and semantic alignment across the RA and PL modalities. ChineseEEG-2 includes EEG signals, precise audio, aligned semantic embeddings from pre-trained language models, and task labels. Together with ChineseEEG, this dataset supports joint semantic alignment learning across speaking, listening, and reading. It enables benchmarking of neural decoding algorithms and promotes brain-LLM alignment under multimodal language tasks, especially in Chinese. ChineseEEG-2 provides a benchmark dataset for next-generation neural semantic decoding.
Towards Optimal Filter Pruning with Balanced Performance and Pruning Speed
Oct 14, 2020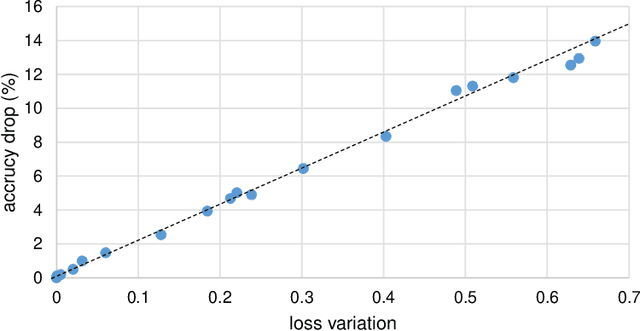

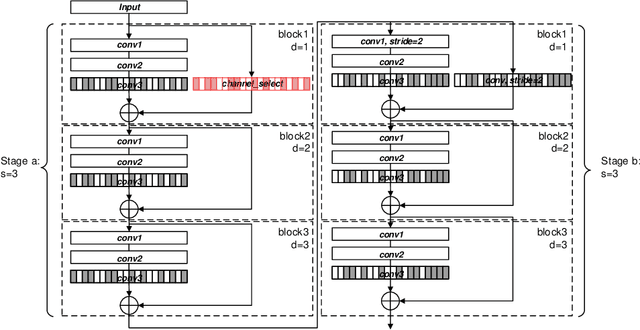
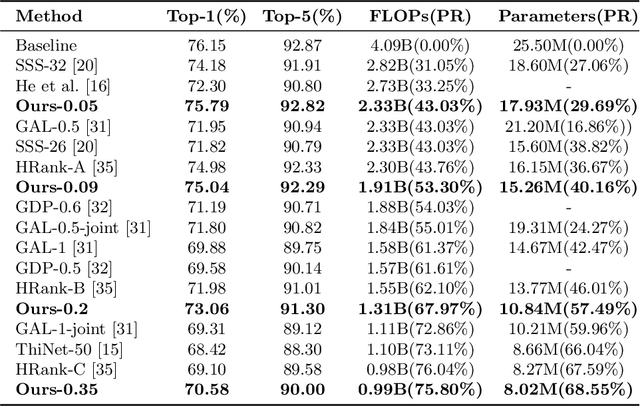
Filter pruning has drawn more attention since resource constrained platform requires more compact model for deployment. However, current pruning methods suffer either from the inferior performance of one-shot methods, or the expensive time cost of iterative training methods. In this paper, we propose a balanced filter pruning method for both performance and pruning speed. Based on the filter importance criteria, our method is able to prune a layer with approximate layer-wise optimal pruning rate at preset loss variation. The network is pruned in the layer-wise way without the time consuming prune-retrain iteration. If a pre-defined pruning rate for the entire network is given, we also introduce a method to find the corresponding loss variation threshold with fast converging speed. Moreover, we propose the layer group pruning and channel selection mechanism for channel alignment in network with short connections. The proposed pruning method is widely applicable to common architectures and does not involve any additional training except the final fine-tuning. Comprehensive experiments show that our method outperforms many state-of-the-art approaches.
Clinical XLNet: Modeling Sequential Clinical Notes and Predicting Prolonged Mechanical Ventilation
Dec 27, 2019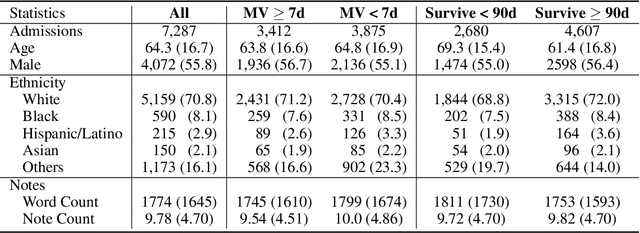
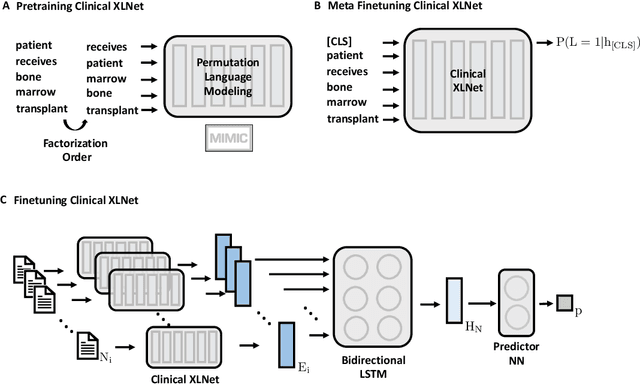
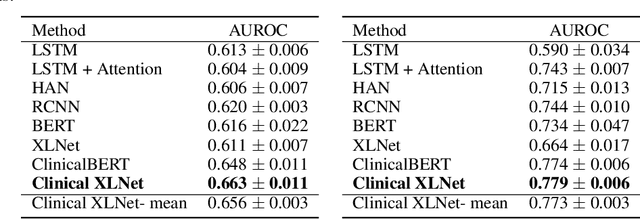
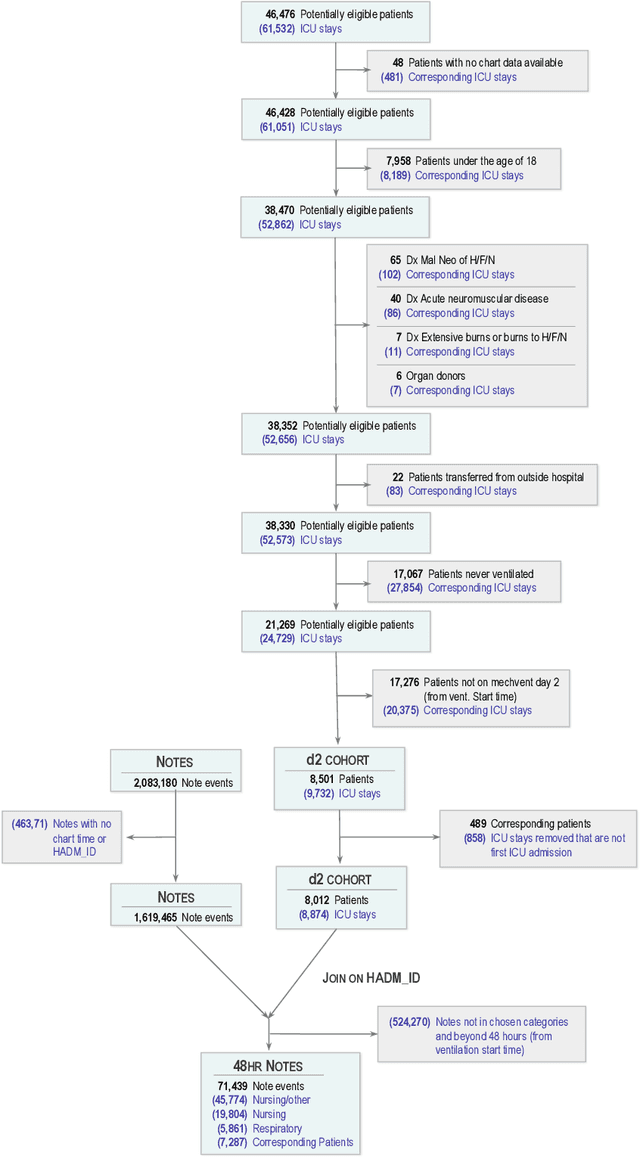
Clinical notes contain rich data, which is unexploited in predictive modeling compared to structured data. In this work, we developed a new text representation Clinical XLNet for clinical notes which also leverages the temporal information of the sequence of the notes. We evaluated our models on prolonged mechanical ventilation prediction problem and our experiments demonstrated that Clinical XLNet outperforms the best baselines consistently.