 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
Feb 13, 2026Current unified multimodal models for image generation and editing typically rely on massive parameter scales (e.g., >10B), entailing prohibitive training costs and deployment footprints. In this work, we present DeepGen 1.0, a lightweight 5B unified model that achieves comprehensive capabilities competitive with or surpassing much larger counterparts. To overcome the limitations of compact models in semantic understanding and fine-grained control, we introduce Stacked Channel Bridging (SCB), a deep alignment framework that extracts hierarchical features from multiple VLM layers and fuses them with learnable 'think tokens' to provide the generative backbone with structured, reasoning-rich guidance. We further design a data-centric training strategy spanning three progressive stages: (1) Alignment Pre-training on large-scale image-text pairs and editing triplets to synchronize VLM and DiT representations, (2) Joint Supervised Fine-tuning on a high-quality mixture of generation, editing, and reasoning tasks to foster omni-capabilities, and (3) Reinforcement Learning with MR-GRPO, which leverages a mixture of reward functions and supervision signals, resulting in substantial gains in generation quality and alignment with human preferences, while maintaining stable training progress and avoiding visual artifacts. Despite being trained on only ~50M samples, DeepGen 1.0 achieves leading performance across diverse benchmarks, surpassing the 80B HunyuanImage by 28% on WISE and the 27B Qwen-Image-Edit by 37% on UniREditBench. By open-sourcing our training code, weights, and datasets, we provide an efficient, high-performance alternative to democratize unified multimodal research.
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Aug 13, 2024



Stable Diffusion Models (SDMs) have shown remarkable proficiency in image synthesis. However, their broad application is impeded by their large model sizes and intensive computational requirements, which typically require expensive cloud servers for deployment. On the flip side, while there are many compact models tailored for edge devices that can reduce these demands, they often compromise on semantic integrity and visual quality when compared to full-sized SDMs. To bridge this gap, we introduce Hybrid SD, an innovative, training-free SDMs inference framework designed for edge-cloud collaborative inference. Hybrid SD distributes the early steps of the diffusion process to the large models deployed on cloud servers, enhancing semantic planning. Furthermore, small efficient models deployed on edge devices can be integrated for refining visual details in the later stages. Acknowledging the diversity of edge devices with differing computational and storage capacities, we employ structural pruning to the SDMs U-Net and train a lightweight VAE. Empirical evaluations demonstrate that our compressed models achieve state-of-the-art parameter efficiency (225.8M) on edge devices with competitive image quality. Additionally, Hybrid SD reduces the cloud cost by 66% with edge-cloud collaborative inference.
SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Mar 03, 2024



The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
Reinforcement Learning for Robot Navigation with Adaptive ExecutionDuration (AED) in a Semi-Markov Model
Aug 30, 2021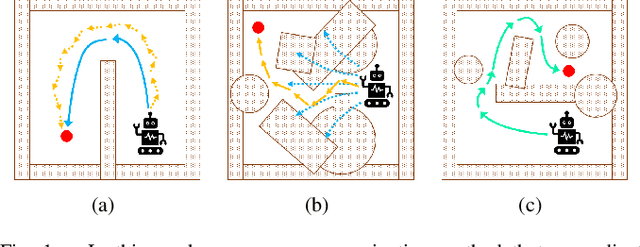
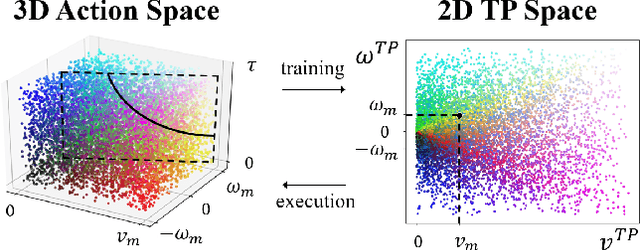
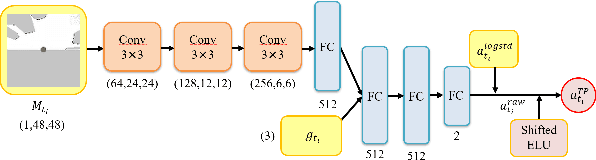
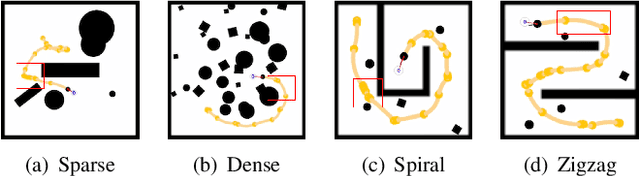
Deep reinforcement learning (DRL) algorithms have proven effective in robot navigation, especially in unknown environments, through directly mapping perception inputs into robot control commands. Most existing methods adopt uniform execution duration with robots taking commands at fixed intervals. As such, the length of execution duration becomes a crucial parameter to the navigation algorithm. In particular, if the duration is too short, then the navigation policy would be executed at a high frequency, with increased training difficulty and high computational cost. Meanwhile, if the duration is too long, then the policy becomes unable to handle complex situations, like those with crowded obstacles. It is thus tricky to find the "sweet" duration range; some duration values may render a DRL model to fail to find a navigation path. In this paper, we propose to employ adaptive execution duration to overcome this problem. Specifically, we formulate the navigation task as a Semi-Markov Decision Process (SMDP) problem to handle adaptive execution duration. We also improve the distributed proximal policy optimization (DPPO) algorithm and provide its theoretical guarantee for the specified SMDP problem. We evaluate our approach both in the simulator and on an actual robot. The results show that our approach outperforms the other DRL-based method (with fixed execution duration) by 10.3% in terms of the navigation success rate.