 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgetMark: Stealthy Fingerprint Embedding via Targeted Unlearning in Language Models
Jan 13, 2026Existing invasive (backdoor) fingerprints suffer from high-perplexity triggers that are easily filtered, fixed response patterns exposed by heuristic detectors, and spurious activations on benign inputs. We introduce \textsc{ForgetMark}, a stealthy fingerprinting framework that encodes provenance via targeted unlearning. It builds a compact, human-readable key--value set with an assistant model and predictive-entropy ranking, then trains lightweight LoRA adapters to suppress the original values on their keys while preserving general capabilities. Ownership is verified under black/gray-box access by aggregating likelihood and semantic evidence into a fingerprint success rate. By relying on probabilistic forgetting traces rather than fixed trigger--response patterns, \textsc{ForgetMark} avoids high-perplexity triggers, reduces detectability, and lowers false triggers. Across diverse architectures and settings, it achieves 100\% ownership verification on fingerprinted models while maintaining standard performance, surpasses backdoor baselines in stealthiness and robustness to model merging, and remains effective under moderate incremental fine-tuning. Our code and data are available at \href{https://github.com/Xuzhenhua55/ForgetMark}{https://github.com/Xuzhenhua55/ForgetMark}.
GMF-Drive: Gated Mamba Fusion with Spatial-Aware BEV Representation for End-to-End Autonomous Driving
Aug 08, 2025



Diffusion-based models are redefining the state-of-the-art in end-to-end autonomous driving, yet their performance is increasingly hampered by a reliance on transformer-based fusion. These architectures face fundamental limitations: quadratic computational complexity restricts the use of high-resolution features, and a lack of spatial priors prevents them from effectively modeling the inherent structure of Bird's Eye View (BEV) representations. This paper introduces GMF-Drive (Gated Mamba Fusion for Driving), an end-to-end framework that overcomes these challenges through two principled innovations. First, we supersede the information-limited histogram-based LiDAR representation with a geometrically-augmented pillar format encoding shape descriptors and statistical features, preserving critical 3D geometric details. Second, we propose a novel hierarchical gated mamba fusion (GM-Fusion) architecture that substitutes an expensive transformer with a highly efficient, spatially-aware state-space model (SSM). Our core BEV-SSM leverages directional sequencing and adaptive fusion mechanisms to capture long-range dependencies with linear complexity, while explicitly respecting the unique spatial properties of the driving scene. Extensive experiments on the challenging NAVSIM benchmark demonstrate that GMF-Drive achieves a new state-of-the-art performance, significantly outperforming DiffusionDrive. Comprehensive ablation studies validate the efficacy of each component, demonstrating that task-specific SSMs can surpass a general-purpose transformer in both performance and efficiency for autonomous driving.
M3Depth: Wavelet-Enhanced Depth Estimation on Mars via Mutual Boosting of Dual-Modal Data
May 20, 2025Depth estimation plays a great potential role in obstacle avoidance and navigation for further Mars exploration missions. Compared to traditional stereo matching, learning-based stereo depth estimation provides a data-driven approach to infer dense and precise depth maps from stereo image pairs. However, these methods always suffer performance degradation in environments with sparse textures and lacking geometric constraints, such as the unstructured terrain of Mars. To address these challenges, we propose M3Depth, a depth estimation model tailored for Mars rovers. Considering the sparse and smooth texture of Martian terrain, which is primarily composed of low-frequency features, our model incorporates a convolutional kernel based on wavelet transform that effectively captures low-frequency response and expands the receptive field. Additionally, we introduce a consistency loss that explicitly models the complementary relationship between depth map and surface normal map, utilizing the surface normal as a geometric constraint to enhance the accuracy of depth estimation. Besides, a pixel-wise refinement module with mutual boosting mechanism is designed to iteratively refine both depth and surface normal predictions. Experimental results on synthetic Mars datasets with depth annotations show that M3Depth achieves a significant 16% improvement in depth estimation accuracy compared to other state-of-the-art methods in depth estimation. Furthermore, the model demonstrates strong applicability in real-world Martian scenarios, offering a promising solution for future Mars exploration missions.
From Image- to Pixel-level: Label-efficient Hyperspectral Image Reconstruction
Mar 10, 2025



Current hyperspectral image (HSI) reconstruction methods primarily rely on image-level approaches, which are time-consuming to form abundant high-quality HSIs through imagers. In contrast, spectrometers offer a more efficient alternative by capturing high-fidelity point spectra, enabling pixel-level HSI reconstruction that balances accuracy and label efficiency. To this end, we introduce a pixel-level spectral super-resolution (Pixel-SSR) paradigm that reconstructs HSI from RGB and point spectra. Despite its advantages, Pixel-SSR presents two key challenges: 1) generalizability to novel scenes lacking point spectra, and 2) effective information extraction to promote reconstruction accuracy. To address the first challenge, a Gamma-modeled strategy is investigated to synthesize point spectra based on their intrinsic properties, including nonnegativity, a skewed distribution, and a positive correlation. Furthermore, complementary three-branch prompts from RGB and point spectra are extracted with a Dynamic Prompt Mamba (DyPro-Mamba), which progressively directs the reconstruction with global spatial distributions, edge details, and spectral dependency. Comprehensive evaluations, including horizontal comparisons with leading methods and vertical assessments across unsupervised and image-level supervised paradigms, demonstrate that ours achieves competitive reconstruction accuracy with efficient label consumption.
The USTC-NERCSLIP Systems for the CHiME-8 NOTSOFAR-1 Challenge
Sep 03, 2024



This technical report outlines our submission system for the CHiME-8 NOTSOFAR-1 Challenge. The primary difficulty of this challenge is the dataset recorded across various conference rooms, which captures real-world complexities such as high overlap rates, background noises, a variable number of speakers, and natural conversation styles. To address these issues, we optimized the system in several aspects: For front-end speech signal processing, we introduced a data-driven joint training method for diarization and separation (JDS) to enhance audio quality. Additionally, we also integrated traditional guided source separation (GSS) for multi-channel track to provide complementary information for the JDS. For back-end speech recognition, we enhanced Whisper with WavLM, ConvNeXt, and Transformer innovations, applying multi-task training and Noise KLD augmentation, to significantly advance ASR robustness and accuracy. Our system attained a Time-Constrained minimum Permutation Word Error Rate (tcpWER) of 14.265% and 22.989% on the CHiME-8 NOTSOFAR-1 Dev-set-2 multi-channel and single-channel tracks, respectively.
URLBERT:A Contrastive and Adversarial Pre-trained Model for URL Classification
Feb 18, 2024URLs play a crucial role in understanding and categorizing web content, particularly in tasks related to security control and online recommendations. While pre-trained models are currently dominating various fields, the domain of URL analysis still lacks specialized pre-trained models. To address this gap, this paper introduces URLBERT, the first pre-trained representation learning model applied to a variety of URL classification or detection tasks. We first train a URL tokenizer on a corpus of billions of URLs to address URL data tokenization. Additionally, we propose two novel pre-training tasks: (1) self-supervised contrastive learning tasks, which strengthen the model's understanding of URL structure and the capture of category differences by distinguishing different variants of the same URL; (2) virtual adversarial training, aimed at improving the model's robustness in extracting semantic features from URLs. Finally, our proposed methods are evaluated on tasks including phishing URL detection, web page classification, and ad filtering, achieving state-of-the-art performance. Importantly, we also explore multi-task learning with URLBERT, and experimental results demonstrate that multi-task learning model based on URLBERT exhibit equivalent effectiveness compared to independently fine-tuned models, showing the simplicity of URLBERT in handling complex task requirements. The code for our work is available at https://github.com/Davidup1/URLBERT.
SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity
Oct 30, 2023



To address the challenge of increasing network size, researchers have developed sparse models through network pruning. However, maintaining model accuracy while achieving significant speedups on general computing devices remains an open problem. In this paper, we present a novel mobile inference acceleration framework SparseByteNN, which leverages fine-grained kernel sparsity to achieve real-time execution as well as high accuracy. Our framework consists of two parts: (a) A fine-grained kernel sparsity schema with a sparsity granularity between structured pruning and unstructured pruning. It designs multiple sparse patterns for different operators. Combined with our proposed whole network rearrangement strategy, the schema achieves a high compression rate and high precision at the same time. (b) Inference engine co-optimized with the sparse pattern. The conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet-v1 outperform strong dense baselines on the efficiency-accuracy curve. Experimental results on Qualcomm 855 show that for 30% sparse MobileNet-v1, SparseByteNN achieves 1.27x speedup over the dense version and 1.29x speedup over the state-of-the-art sparse inference engine MNN with a slight accuracy drop of 0.224%. The source code of SparseByteNN will be available at https://github.com/lswzjuer/SparseByteNN
MIME: Mutual Information Minimisation Exploration
Jan 16, 2020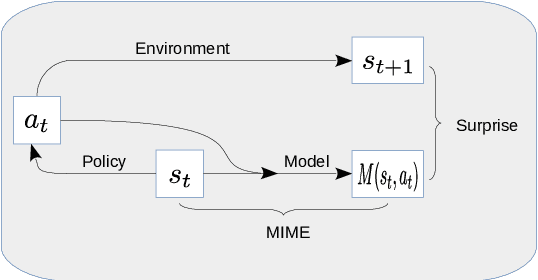

We show that reinforcement learning agents that learn by surprise (surprisal) get stuck at abrupt environmental transition boundaries because these transitions are difficult to learn. We propose a counter-intuitive solution that we call Mutual Information Minimising Exploration (MIME) where an agent learns a latent representation of the environment without trying to predict the future states. We show that our agent performs significantly better over sharp transition boundaries while matching the performance of surprisal driven agents elsewhere. In particular, we show state-of-the-art performance on difficult learning games such as Gravitar, Montezuma's Revenge and Doom.
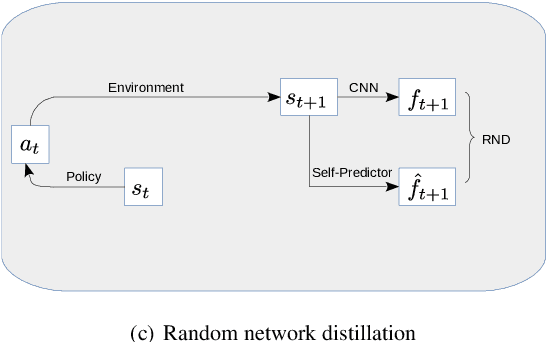
VASE: Variational Assorted Surprise Exploration for Reinforcement Learning
Oct 31, 2019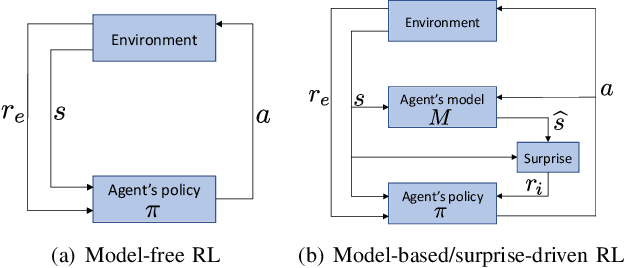
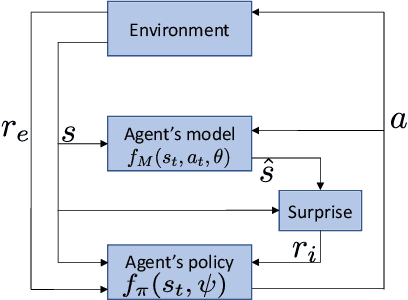
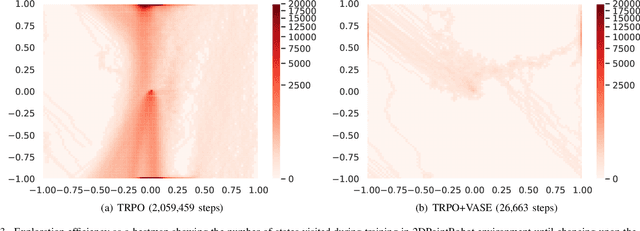
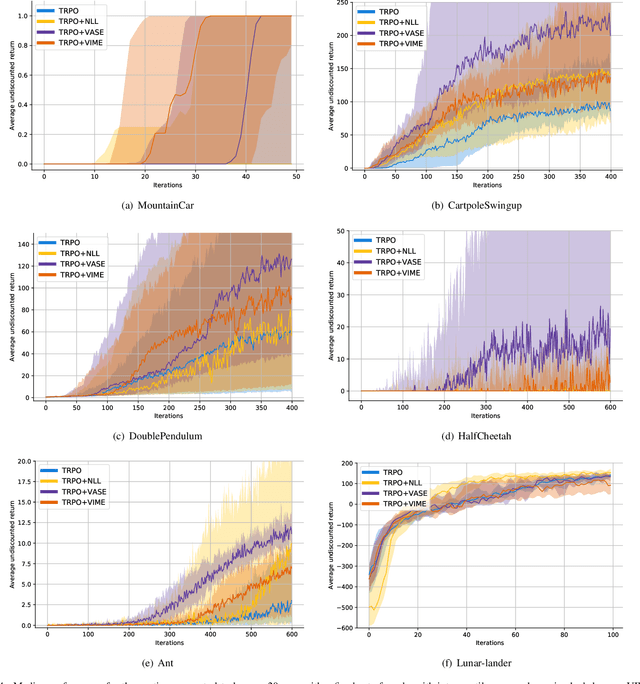
Exploration in environments with continuous control and sparse rewards remains a key challenge in reinforcement learning (RL). Recently, surprise has been used as an intrinsic reward that encourages systematic and efficient exploration. We introduce a new definition of surprise and its RL implementation named Variational Assorted Surprise Exploration (VASE). VASE uses a Bayesian neural network as a model of the environment dynamics and is trained using variational inference, alternately updating the accuracy of the agent's model and policy. Our experiments show that in continuous control sparse reward environments VASE outperforms other surprise-based exploration techniques.