 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Grad: Reinforcement Learning from Natural Language Feedback
May 28, 2025Traditional RLHF optimizes language models with coarse, scalar rewards that mask the fine-grained reasons behind success or failure, leading to slow and opaque learning. Recent work augments RL with textual critiques through prompting or reflection, improving interpretability but leaving model parameters untouched. We introduce Text2Grad, a reinforcement-learning paradigm that turns free-form textual feedback into span-level gradients. Given human (or programmatic) critiques, Text2Grad aligns each feedback phrase with the relevant token spans, converts these alignments into differentiable reward signals, and performs gradient updates that directly refine the offending portions of the model's policy. This yields precise, feedback-conditioned adjustments instead of global nudges. Text2Grad is realized through three components: (1) a high-quality feedback-annotation pipeline that pairs critiques with token spans; (2) a fine-grained reward model that predicts span-level reward on answer while generating explanatory critiques; and (3) a span-level policy optimizer that back-propagates natural-language gradients. Across summarization, code generation, and question answering, Text2Grad consistently surpasses scalar-reward RL and prompt-only baselines, providing both higher task metrics and richer interpretability. Our results demonstrate that natural-language feedback, when converted to gradients, is a powerful signal for fine-grained policy optimization. The code for our method is available at https://github.com/microsoft/Text2Grad
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025

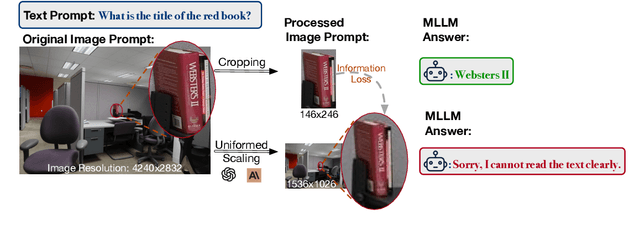
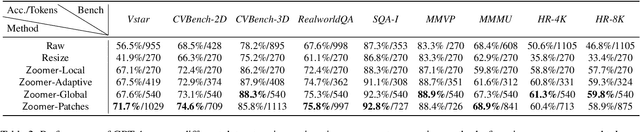
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
I$^2$KD-SLU: An Intra-Inter Knowledge Distillation Framework for Zero-Shot Cross-Lingual Spoken Language Understanding
Oct 04, 2023Spoken language understanding (SLU) typically includes two subtasks: intent detection and slot filling. Currently, it has achieved great success in high-resource languages, but it still remains challenging in low-resource languages due to the scarcity of labeled training data. Hence, there is a growing interest in zero-shot cross-lingual SLU. Despite of the success of existing zero-shot cross-lingual SLU models, most of them neglect to achieve the mutual guidance between intent and slots. To address this issue, we propose an Intra-Inter Knowledge Distillation framework for zero-shot cross-lingual Spoken Language Understanding (I$^2$KD-SLU) to model the mutual guidance. Specifically, we not only apply intra-knowledge distillation between intent predictions or slot predictions of the same utterance in different languages, but also apply inter-knowledge distillation between intent predictions and slot predictions of the same utterance. Our experimental results demonstrate that our proposed framework significantly improves the performance compared with the strong baselines and achieves the new state-of-the-art performance on the MultiATIS++ dataset, obtaining a significant improvement over the previous best model in overall accuracy.