 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiSkill: Skill-Aware Reflection for Self-Evolving Embodied Agents
May 11, 2026Embodied agents can benefit from skills that guide object search, action execution, and state changes across diverse environments. Since embodied environments vary across layouts, object states, and other execution factors, these skills must self-evolve from trajectories generated during task execution. However, existing skill self-evolution methods are mainly developed in digital environments and often convert trajectories into coarse skill updates. Directly applying this paradigm to embodied settings is problematic, because a failed task execution may reflect not only incorrect skill content, but also an execution lapse in which the agent fails to follow valid guidance. We propose EmbodiSkill, a training-free framework for embodied skill self-evolution through skill-aware reflection and targeted revision. EmbodiSkill interprets each trajectory with respect to the current skill, uses skill-changing evidence to update the skill body, and uses execution-lapse evidence to preserve and emphasize valid guidance. Experiments on ALFWorld and EmbodiedBench show that EmbodiSkill consistently improves embodied task success. On ALFWorld, EmbodiSkill enables a frozen Qwen3.5-27B executor to reach 93.28% task success, outperforming GPT-5.2 used as a direct agent without skills by 31.58%. These results show that skill-aware self-evolution helps embodied agents accumulate reusable procedural knowledge from their own trajectories.
Em-Garde: A Propose-Match Framework for Proactive Streaming Video Understanding
Mar 19, 2026Recent advances in Streaming Video Understanding has enabled a new interaction paradigm where models respond proactively to user queries. Current proactive VideoLLMs rely on per-frame triggering decision making, which suffers from an efficiency-accuracy dilemma. We propose Em-Garde, a novel framework that decouples semantic understanding from streaming perception. At query time, the Instruction-Guided Proposal Parser transforms user queries into structured, perceptually grounded visual proposals; during streaming, a Lightweight Proposal Matching Module performs efficient embedding-based matching to trigger responses. Experiments on StreamingBench and OVO-Bench demonstrate consistent improvements over prior models in proactive response accuracy and efficiency, validating an effective solution for proactive video understanding under strict computational constraints.
MPJudge: Towards Perceptual Assessment of Music-Induced Paintings
Nov 10, 2025Music induced painting is a unique artistic practice, where visual artworks are created under the influence of music. Evaluating whether a painting faithfully reflects the music that inspired it poses a challenging perceptual assessment task. Existing methods primarily rely on emotion recognition models to assess the similarity between music and painting, but such models introduce considerable noise and overlook broader perceptual cues beyond emotion. To address these limitations, we propose a novel framework for music induced painting assessment that directly models perceptual coherence between music and visual art. We introduce MPD, the first large scale dataset of music painting pairs annotated by domain experts based on perceptual coherence. To better handle ambiguous cases, we further collect pairwise preference annotations. Building on this dataset, we present MPJudge, a model that integrates music features into a visual encoder via a modulation based fusion mechanism. To effectively learn from ambiguous cases, we adopt Direct Preference Optimization for training. Extensive experiments demonstrate that our method outperforms existing approaches. Qualitative results further show that our model more accurately identifies music relevant regions in paintings.
Diffusion^2: Turning 3D Environments into Radio Frequency Heatmaps
Oct 02, 2025Modeling radio frequency (RF) signal propagation is essential for understanding the environment, as RF signals offer valuable insights beyond the capabilities of RGB cameras, which are limited by the visible-light spectrum, lens coverage, and occlusions. It is also useful for supporting wireless diagnosis, deployment, and optimization. However, accurately predicting RF signals in complex environments remains a challenge due to interactions with obstacles such as absorption and reflection. We introduce Diffusion^2, a diffusion-based approach that uses 3D point clouds to model the propagation of RF signals across a wide range of frequencies, from Wi-Fi to millimeter waves. To effectively capture RF-related features from 3D data, we present the RF-3D Encoder, which encapsulates the complexities of 3D geometry along with signal-specific details. These features undergo multi-scale embedding to simulate the actual RF signal dissemination process. Our evaluation, based on synthetic and real-world measurements, demonstrates that Diffusion^2 accurately estimates the behavior of RF signals in various frequency bands and environmental conditions, with an error margin of just 1.9 dB and 27x faster than existing methods, marking a significant advancement in the field. Refer to https://rfvision-project.github.io/ for more information.
STQE: Spatial-Temporal Quality Enhancement for G-PCC Compressed Dynamic Point Clouds
Jul 23, 2025Very few studies have addressed quality enhancement for compressed dynamic point clouds. In particular, the effective exploitation of spatial-temporal correlations between point cloud frames remains largely unexplored. Addressing this gap, we propose a spatial-temporal attribute quality enhancement (STQE) network that exploits both spatial and temporal correlations to improve the visual quality of G-PCC compressed dynamic point clouds. Our contributions include a recoloring-based motion compensation module that remaps reference attribute information to the current frame geometry to achieve precise inter-frame geometric alignment, a channel-aware temporal attention module that dynamically highlights relevant regions across bidirectional reference frames, a Gaussian-guided neighborhood feature aggregation module that efficiently captures spatial dependencies between geometry and color attributes, and a joint loss function based on the Pearson correlation coefficient, designed to alleviate over-smoothing effects typical of point-wise mean squared error optimization. When applied to the latest G-PCC test model, STQE achieved improvements of 0.855 dB, 0.682 dB, and 0.828 dB in delta PSNR, with Bj{\o}ntegaard Delta rate (BD-rate) reductions of -25.2%, -31.6%, and -32.5% for the Luma, Cb, and Cr components, respectively.
LPCM: Learning-based Predictive Coding for LiDAR Point Cloud Compression
May 26, 2025Since the data volume of LiDAR point clouds is very huge, efficient compression is necessary to reduce their storage and transmission costs. However, existing learning-based compression methods do not exploit the inherent angular resolution of LiDAR and ignore the significant differences in the correlation of geometry information at different bitrates. The predictive geometry coding method in the geometry-based point cloud compression (G-PCC) standard uses the inherent angular resolution to predict the azimuth angles. However, it only models a simple linear relationship between the azimuth angles of neighboring points. Moreover, it does not optimize the quantization parameters for residuals on each coordinate axis in the spherical coordinate system. We propose a learning-based predictive coding method (LPCM) with both high-bitrate and low-bitrate coding modes. LPCM converts point clouds into predictive trees using the spherical coordinate system. In high-bitrate coding mode, we use a lightweight Long-Short-Term Memory-based predictive (LSTM-P) module that captures long-term geometry correlations between different coordinates to efficiently predict and compress the elevation angles. In low-bitrate coding mode, where geometry correlation degrades, we introduce a variational radius compression (VRC) module to directly compress the point radii. Then, we analyze why the quantization of spherical coordinates differs from that of Cartesian coordinates and propose a differential evolution (DE)-based quantization parameter selection method, which improves rate-distortion performance without increasing coding time. Experimental results on the LiDAR benchmark \textit{SemanticKITTI} and the MPEG-specified \textit{Ford} datasets show that LPCM outperforms G-PCC and other learning-based methods.
Empowering Agentic Video Analytics Systems with Video Language Models
May 02, 2025



AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025

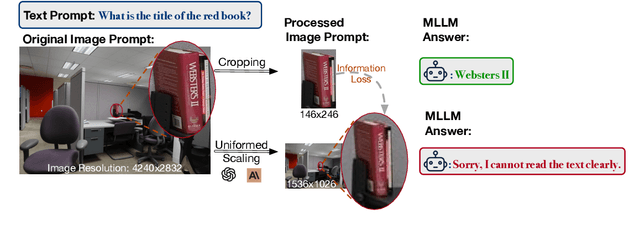
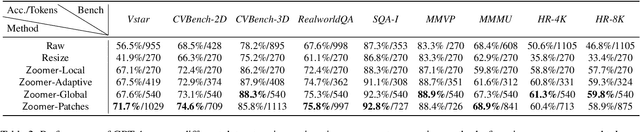
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
Apr 11, 2025Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.
Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment
Mar 21, 2025



We propose V-Droid, a mobile GUI task automation agent. Unlike previous mobile agents that utilize Large Language Models (LLMs) as generators to directly generate actions at each step, V-Droid employs LLMs as verifiers to evaluate candidate actions before making final decisions. To realize this novel paradigm, we introduce a comprehensive framework for constructing verifier-driven mobile agents: the discretized action space construction coupled with the prefilling-only workflow to accelerate the verification process, the pair-wise progress preference training to significantly enhance the verifier's decision-making capabilities, and the scalable human-agent joint annotation scheme to efficiently collect the necessary data at scale. V-Droid sets a new state-of-the-art task success rate across several public mobile task automation benchmarks: 59.5% on AndroidWorld, 38.3% on AndroidLab, and 49% on MobileAgentBench, surpassing existing agents by 9.5%, 2.1%, and 9%, respectively. Furthermore, V-Droid achieves an impressively low latency of 0.7 seconds per step, making it the first mobile agent capable of delivering near-real-time, effective decision-making capabilities.