 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoomer: Adaptive Image Focus Optimization for Black-box MLLM
Paper and Code
Apr 30, 2025

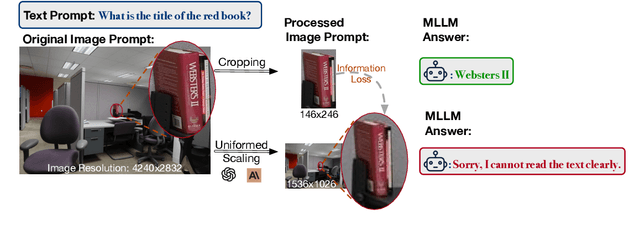
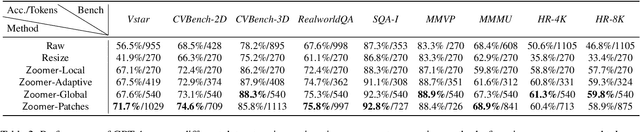
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.