 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSSC-BiMamba: Multimodal Sleep Stage Classification and Early Diagnosis of Sleep Disorders with Bidirectional Mamba
May 31, 2024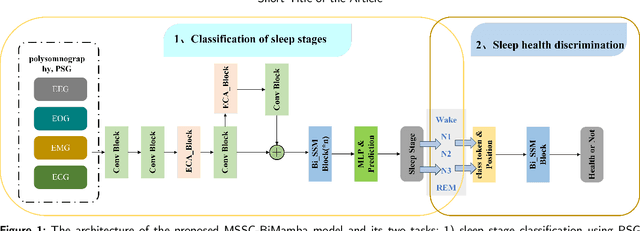
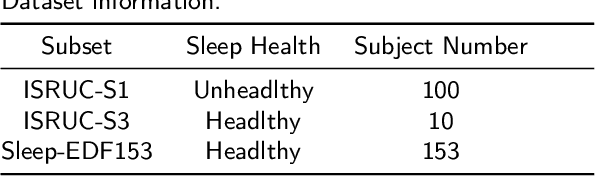
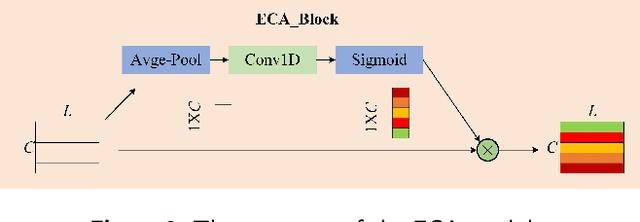

Monitoring sleep states is essential for evaluating sleep quality and diagnosing sleep disorders. Traditional manual staging is time-consuming and prone to subjective bias, often resulting in inconsistent outcomes. Here, we developed an automated model for sleep staging and disorder classification to enhance diagnostic accuracy and efficiency. Considering the characteristics of polysomnography (PSG) multi-lead sleep monitoring, we designed a multimodal sleep state classification model, MSSC-BiMamba, that combines an Efficient Channel Attention (ECA) mechanism with a Bidirectional State Space Model (BSSM). The ECA module allows for weighting data from different sensor channels, thereby amplifying the influence of diverse sensor inputs. Additionally, the implementation of bidirectional Mamba (BiMamba) enables the model to effectively capture the multidimensional features and long-range dependencies of PSG data. The developed model demonstrated impressive performance on sleep stage classification tasks on both the ISRUC-S3 and ISRUC-S1 datasets, respectively containing data with healthy and unhealthy sleep patterns. Also, the model exhibited a high accuracy for sleep health prediction when evaluated on a combined dataset consisting of ISRUC and Sleep-EDF. Our model, which can effectively handle diverse sleep conditions, is the first to apply BiMamba to sleep staging with multimodal PSG data, showing substantial gains in computational and memory efficiency over traditional Transformer-style models. This method enhances sleep health management by making monitoring more accessible and extending advanced healthcare through innovative technology.
NoteLLM-2: Multimodal Large Representation Models for Recommendation
May 27, 2024



Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
Incremental Pseudo-Labeling for Black-Box Unsupervised Domain Adaptation
May 26, 2024Black-Box unsupervised domain adaptation (BBUDA) learns knowledge only with the prediction of target data from the source model without access to the source data and source model, which attempts to alleviate concerns about the privacy and security of data. However, incorrect pseudo-labels are prevalent in the prediction generated by the source model due to the cross-domain discrepancy, which may substantially degrade the performance of the target model. To address this problem, we propose a novel approach that incrementally selects high-confidence pseudo-labels to improve the generalization ability of the target model. Specifically, we first generate pseudo-labels using a source model and train a crude target model by a vanilla BBUDA method. Second, we iteratively select high-confidence data from the low-confidence data pool by thresholding the softmax probabilities, prototype labels, and intra-class similarity. Then, we iteratively train a stronger target network based on the crude target model to correct the wrongly labeled samples to improve the accuracy of the pseudo-label. Experimental results demonstrate that the proposed method achieves state-of-the-art black-box unsupervised domain adaptation performance on three benchmark datasets.
Bayesian WeakS-to-Strong from Text Classification to Generation
May 24, 2024



Advances in large language models raise the question of how alignment techniques will adapt as models become increasingly complex and humans will only be able to supervise them weakly. Weak-to-Strong mimics such a scenario where weak model supervision attempts to harness the full capabilities of a much stronger model. This work extends Weak-to-Strong to WeakS-to-Strong by exploring an ensemble of weak models which simulate the variability in human opinions. Confidence scores are estimated using a Bayesian approach to guide the WeakS-to-Strong generalization. Furthermore, we extend the application of WeakS-to-Strong from text classification tasks to text generation tasks where more advanced strategies are investigated for supervision. Moreover, direct preference optimization is applied to advance the student model's preference learning, beyond the basic learning framework of teacher forcing. Results demonstrate the effectiveness of the proposed approach for the reliability of a strong student model, showing potential for superalignment.
Self-Taught Recognizer: Toward Unsupervised Adaptation for Speech Foundation Models
May 23, 2024



We propose an unsupervised adaptation framework, Self-TAught Recognizer (STAR), which leverages unlabeled data to enhance the robustness of automatic speech recognition (ASR) systems in diverse target domains, such as noise and accents. STAR is developed for prevalent speech foundation models based on Transformer-related architecture with auto-regressive decoding (e.g., Whisper, Canary). Specifically, we propose a novel indicator that empirically integrates step-wise information during decoding to assess the token-level quality of pseudo labels without ground truth, thereby guiding model updates for effective unsupervised adaptation. Experimental results show that STAR achieves an average of 13.5% relative reduction in word error rate across 14 target domains, and it sometimes even approaches the upper-bound performance of supervised adaptation. Surprisingly, we also observe that STAR prevents the adapted model from the common catastrophic forgetting problem without recalling source-domain data. Furthermore, STAR exhibits high data efficiency that only requires less than one-hour unlabeled data, and seamless generality to alternative large speech models and speech translation tasks. Our code aims to open source to the research communities.
CrossCheckGPT: Universal Hallucination Ranking for Multimodal Foundation Models
May 22, 2024Multimodal foundation models are prone to hallucination, generating outputs that either contradict the input or are not grounded by factual information. Given the diversity in architectures, training data and instruction tuning techniques, there can be large variations in systems' susceptibility to hallucinations. To assess system hallucination robustness, hallucination ranking approaches have been developed for specific tasks such as image captioning, question answering, summarization, or biography generation. However, these approaches typically compare model outputs to gold-standard references or labels, limiting hallucination benchmarking for new domains. This work proposes "CrossCheckGPT", a reference-free universal hallucination ranking for multimodal foundation models. The core idea of CrossCheckGPT is that the same hallucinated content is unlikely to be generated by different independent systems, hence cross-system consistency can provide meaningful and accurate hallucination assessment scores. CrossCheckGPT can be applied to any model or task, provided that the information consistency between outputs can be measured through an appropriate distance metric. Focusing on multimodal large language models that generate text, we explore two information consistency measures: CrossCheck-explicit and CrossCheck-implicit. We showcase the applicability of our method for hallucination ranking across various modalities, namely the text, image, and audio-visual domains. Further, we propose the first audio-visual hallucination benchmark, "AVHalluBench", and illustrate the effectiveness of CrossCheckGPT, achieving correlations of 98% and 89% with human judgements on MHaluBench and AVHalluBench, respectively.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
BMRetriever: Tuning Large Language Models as Better Biomedical Text Retrievers
Apr 29, 2024



Developing effective biomedical retrieval models is important for excelling at knowledge-intensive biomedical tasks but still challenging due to the deficiency of sufficient publicly annotated biomedical data and computational resources. We present BMRetriever, a series of dense retrievers for enhancing biomedical retrieval via unsupervised pre-training on large biomedical corpora, followed by instruction fine-tuning on a combination of labeled datasets and synthetic pairs. Experiments on 5 biomedical tasks across 11 datasets verify BMRetriever's efficacy on various biomedical applications. BMRetriever also exhibits strong parameter efficiency, with the 410M variant outperforming baselines up to 11.7 times larger, and the 2B variant matching the performance of models with over 5B parameters. The training data and model checkpoints are released at \url{https://huggingface.co/BMRetriever} to ensure transparency, reproducibility, and application to new domains.
Frequency-Guided Multi-Level Human Action Anomaly Detection with Normalizing Flows
Apr 26, 2024



We introduce the task of human action anomaly detection (HAAD), which aims to identify anomalous motions in an unsupervised manner given only the pre-determined normal category of training action samples. Compared to prior human-related anomaly detection tasks which primarily focus on unusual events from videos, HAAD involves the learning of specific action labels to recognize semantically anomalous human behaviors. To address this task, we propose a normalizing flow (NF)-based detection framework where the sample likelihood is effectively leveraged to indicate anomalies. As action anomalies often occur in some specific body parts, in addition to the full-body action feature learning, we incorporate extra encoding streams into our framework for a finer modeling of body subsets. Our framework is thus multi-level to jointly discover global and local motion anomalies. Furthermore, to show awareness of the potentially jittery data during recording, we resort to discrete cosine transformation by converting the action samples from the temporal to the frequency domain to mitigate the issue of data instability. Extensive experimental results on two human action datasets demonstrate that our method outperforms the baselines formed by adapting state-of-the-art human activity AD approaches to our task of HAAD.
Bayesian Example Selection Improves In-Context Learning for Speech, Text, and Visual Modalities
Apr 23, 2024Large language models (LLMs) can adapt to new tasks through in-context learning (ICL) based on a few examples presented in dialogue history without any model parameter update. Despite such convenience, the performance of ICL heavily depends on the quality of the in-context examples presented, which makes the in-context example selection approach a critical choice. This paper proposes a novel Bayesian in-Context example Selection method (ByCS) for ICL. Extending the inference probability conditioned on in-context examples based on Bayes' theorem, ByCS focuses on the inverse inference conditioned on test input. Following the assumption that accurate inverse inference probability (likelihood) will result in accurate inference probability (posterior), in-context examples are selected based on their inverse inference results. Diverse and extensive cross-tasking and cross-modality experiments are performed with speech, text, and image examples. Experimental results show the efficacy and robustness of our ByCS method on various models, tasks and modalities.