 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptEnhancer: A Simple Approach to Enhance Text-to-Image Models via Chain-of-Thought Prompt Rewriting
Sep 04, 2025Recent advancements in text-to-image (T2I) diffusion models have demonstrated remarkable capabilities in generating high-fidelity images. However, these models often struggle to faithfully render complex user prompts, particularly in aspects like attribute binding, negation, and compositional relationships. This leads to a significant mismatch between user intent and the generated output. To address this challenge, we introduce PromptEnhancer, a novel and universal prompt rewriting framework that enhances any pretrained T2I model without requiring modifications to its weights. Unlike prior methods that rely on model-specific fine-tuning or implicit reward signals like image-reward scores, our framework decouples the rewriter from the generator. We achieve this by training a Chain-of-Thought (CoT) rewriter through reinforcement learning, guided by a dedicated reward model we term the AlignEvaluator. The AlignEvaluator is trained to provide explicit and fine-grained feedback based on a systematic taxonomy of 24 key points, which are derived from a comprehensive analysis of common T2I failure modes. By optimizing the CoT rewriter to maximize the reward from our AlignEvaluator, our framework learns to generate prompts that are more precisely interpreted by T2I models. Extensive experiments on the HunyuanImage 2.1 model demonstrate that PromptEnhancer significantly improves image-text alignment across a wide range of semantic and compositional challenges. Furthermore, we introduce a new, high-quality human preference benchmark to facilitate future research in this direction.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
Mar 13, 2024Text-to-image (T2I) generation models have significantly advanced in recent years. However, effective interaction with these models is challenging for average users due to the need for specialized prompt engineering knowledge and the inability to perform multi-turn image generation, hindering a dynamic and iterative creation process. Recent attempts have tried to equip Multi-modal Large Language Models (MLLMs) with T2I models to bring the user's natural language instructions into reality. Hence, the output modality of MLLMs is extended, and the multi-turn generation quality of T2I models is enhanced thanks to the strong multi-modal comprehension ability of MLLMs. However, many of these works face challenges in identifying correct output modalities and generating coherent images accordingly as the number of output modalities increases and the conversations go deeper. Therefore, we propose DialogGen, an effective pipeline to align off-the-shelf MLLMs and T2I models to build a Multi-modal Interactive Dialogue System (MIDS) for multi-turn Text-to-Image generation. It is composed of drawing prompt alignment, careful training data curation, and error correction. Moreover, as the field of MIDS flourishes, comprehensive benchmarks are urgently needed to evaluate MIDS fairly in terms of output modality correctness and multi-modal output coherence. To address this issue, we introduce the Multi-modal Dialogue Benchmark (DialogBen), a comprehensive bilingual benchmark designed to assess the ability of MLLMs to generate accurate and coherent multi-modal content that supports image editing. It contains two evaluation metrics to measure the model's ability to switch modalities and the coherence of the output images. Our extensive experiments on DialogBen and user study demonstrate the effectiveness of DialogGen compared with other State-of-the-Art models.
GrowCLIP: Data-aware Automatic Model Growing for Large-scale Contrastive Language-Image Pre-training
Aug 22, 2023



Cross-modal pre-training has shown impressive performance on a wide range of downstream tasks, benefiting from massive image-text pairs collected from the Internet. In practice, online data are growing constantly, highlighting the importance of the ability of pre-trained model to learn from data that is continuously growing. Existing works on cross-modal pre-training mainly focus on training a network with fixed architecture. However, it is impractical to limit the model capacity when considering the continuously growing nature of pre-training data in real-world applications. On the other hand, it is important to utilize the knowledge in the current model to obtain efficient training and better performance. To address the above issues, in this paper, we propose GrowCLIP, a data-driven automatic model growing algorithm for contrastive language-image pre-training with continuous image-text pairs as input. Specially, we adopt a dynamic growth space and seek out the optimal architecture at each growth step to adapt to online learning scenarios. And the shared encoder is proposed in our growth space to enhance the degree of cross-modal fusion. Besides, we explore the effect of growth in different dimensions, which could provide future references for the design of cross-modal model architecture. Finally, we employ parameter inheriting with momentum (PIM) to maintain the previous knowledge and address the issue of the local minimum dilemma. Compared with the existing methods, GrowCLIP improves 2.3% average top-1 accuracy on zero-shot image classification of 9 downstream tasks. As for zero-shot image retrieval, GrowCLIP can improve 1.2% for top-1 image-to-text recall on Flickr30K dataset.
Continual Object Detection via Prototypical Task Correlation Guided Gating Mechanism
May 06, 2022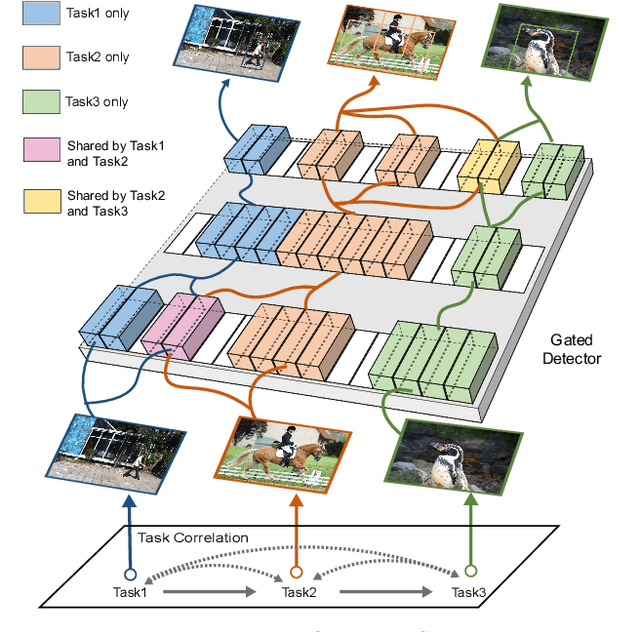
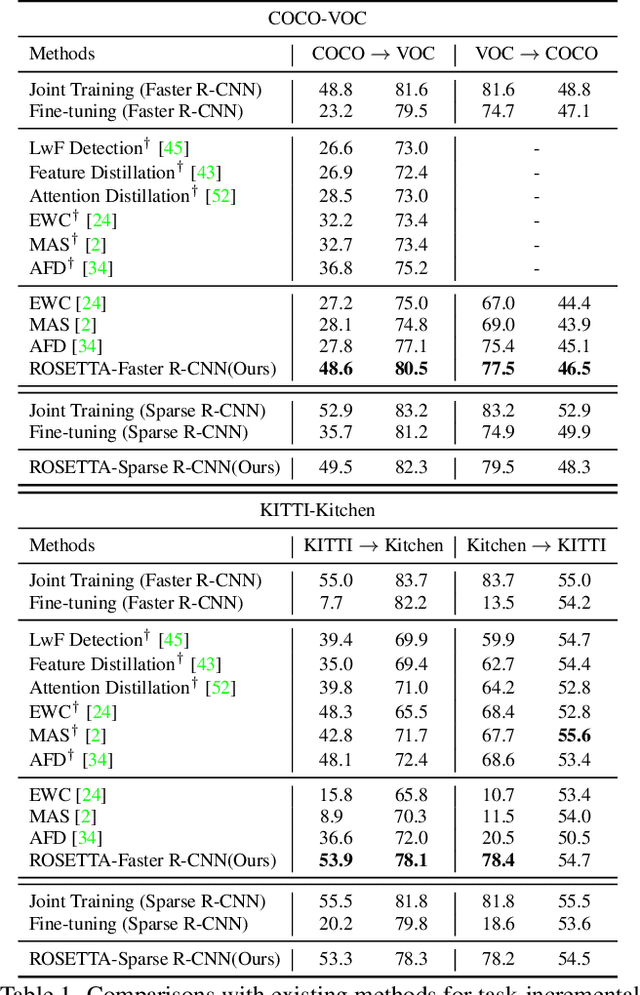
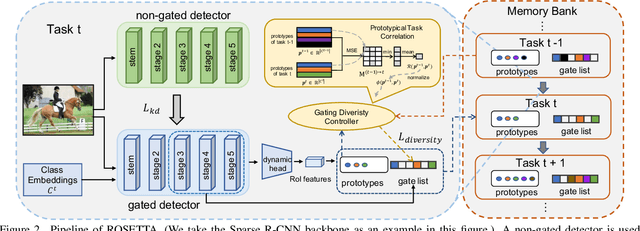
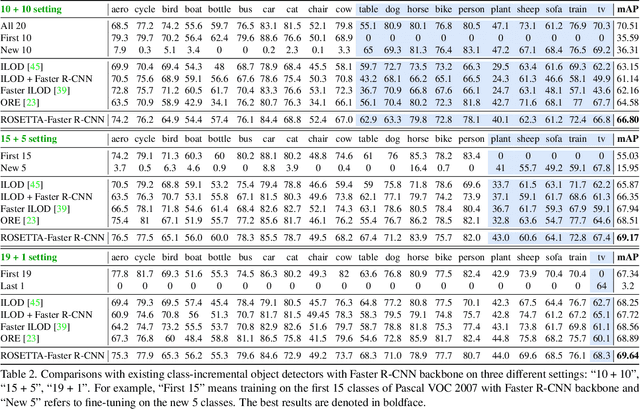
Continual learning is a challenging real-world problem for constructing a mature AI system when data are provided in a streaming fashion. Despite recent progress in continual classification, the researches of continual object detection are impeded by the diverse sizes and numbers of objects in each image. Different from previous works that tune the whole network for all tasks, in this work, we present a simple and flexible framework for continual object detection via pRotOtypical taSk corrElaTion guided gaTing mechAnism (ROSETTA). Concretely, a unified framework is shared by all tasks while task-aware gates are introduced to automatically select sub-models for specific tasks. In this way, various knowledge can be successively memorized by storing their corresponding sub-model weights in this system. To make ROSETTA automatically determine which experience is available and useful, a prototypical task correlation guided Gating Diversity Controller(GDC) is introduced to adaptively adjust the diversity of gates for the new task based on class-specific prototypes. GDC module computes class-to-class correlation matrix to depict the cross-task correlation, and hereby activates more exclusive gates for the new task if a significant domain gap is observed. Comprehensive experiments on COCO-VOC, KITTI-Kitchen, class-incremental detection on VOC and sequential learning of four tasks show that ROSETTA yields state-of-the-art performance on both task-based and class-based continual object detection.