 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALUM: Part-based Attention Learning for Unified Motion Retargeting
Jan 12, 2026Retargeting motion between characters with different skeleton structures is a fundamental challenge in computer animation. When source and target characters have vastly different bone arrangements, maintaining the original motion's semantics and quality becomes increasingly difficult. We present PALUM, a novel approach that learns common motion representations across diverse skeleton topologies by partitioning joints into semantic body parts and applying attention mechanisms to capture spatio-temporal relationships. Our method transfers motion to target skeletons by leveraging these skeleton-agnostic representations alongside target-specific structural information. To ensure robust learning and preserve motion fidelity, we introduce a cycle consistency mechanism that maintains semantic coherence throughout the retargeting process. Extensive experiments demonstrate superior performance in handling diverse skeletal structures while maintaining motion realism and semantic fidelity, even when generalizing to previously unseen skeleton-motion combinations. We will make our implementation publicly available to support future research.
ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning
Dec 11, 2025
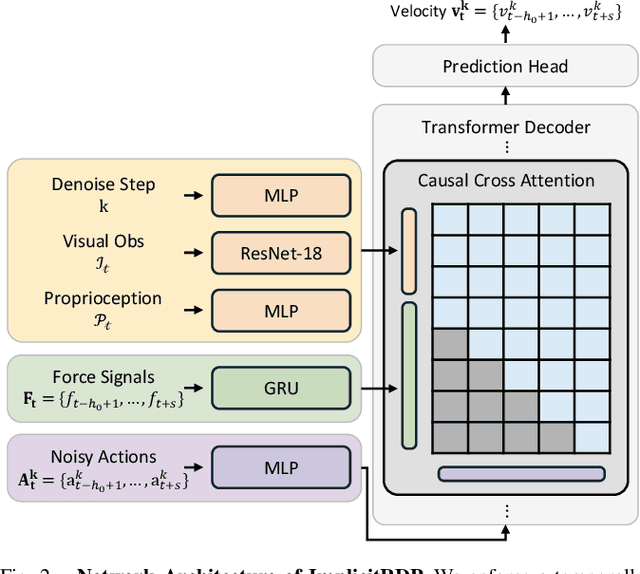


Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities. In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks. Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction. Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline. Code and videos will be publicly available at https://implicit-rdp.github.io.
Exploring Category-level Articulated Object Pose Tracking on SE(3) Manifolds
Nov 08, 2025Articulated objects are prevalent in daily life and robotic manipulation tasks. However, compared to rigid objects, pose tracking for articulated objects remains an underexplored problem due to their inherent kinematic constraints. To address these challenges, this work proposes a novel point-pair-based pose tracking framework, termed \textbf{PPF-Tracker}. The proposed framework first performs quasi-canonicalization of point clouds in the SE(3) Lie group space, and then models articulated objects using Point Pair Features (PPF) to predict pose voting parameters by leveraging the invariance properties of SE(3). Finally, semantic information of joint axes is incorporated to impose unified kinematic constraints across all parts of the articulated object. PPF-Tracker is systematically evaluated on both synthetic datasets and real-world scenarios, demonstrating strong generalization across diverse and challenging environments. Experimental results highlight the effectiveness and robustness of PPF-Tracker in multi-frame pose tracking of articulated objects. We believe this work can foster advances in robotics, embodied intelligence, and augmented reality. Codes are available at https://github.com/mengxh20/PPFTracker.
Executable Analytic Concepts as the Missing Link Between VLM Insight and Precise Manipulation
Oct 09, 2025Enabling robots to perform precise and generalized manipulation in unstructured environments remains a fundamental challenge in embodied AI. While Vision-Language Models (VLMs) have demonstrated remarkable capabilities in semantic reasoning and task planning, a significant gap persists between their high-level understanding and the precise physical execution required for real-world manipulation. To bridge this "semantic-to-physical" gap, we introduce GRACE, a novel framework that grounds VLM-based reasoning through executable analytic concepts (EAC)-mathematically defined blueprints that encode object affordances, geometric constraints, and semantics of manipulation. Our approach integrates a structured policy scaffolding pipeline that turn natural language instructions and visual information into an instantiated EAC, from which we derive grasp poses, force directions and plan physically feasible motion trajectory for robot execution. GRACE thus provides a unified and interpretable interface between high-level instruction understanding and low-level robot control, effectively enabling precise and generalizable manipulation through semantic-physical grounding. Extensive experiments demonstrate that GRACE achieves strong zero-shot generalization across a variety of articulated objects in both simulated and real-world environments, without requiring task-specific training.
ARMADA: Autonomous Online Failure Detection and Human Shared Control Empower Scalable Real-world Deployment and Adaptation
Oct 02, 2025Imitation learning has shown promise in learning from large-scale real-world datasets. However, pretrained policies usually perform poorly without sufficient in-domain data. Besides, human-collected demonstrations entail substantial labour and tend to encompass mixed-quality data and redundant information. As a workaround, human-in-the-loop systems gather domain-specific data for policy post-training, and exploit closed-loop policy feedback to offer informative guidance, but usually require full-time human surveillance during policy rollout. In this work, we devise ARMADA, a multi-robot deployment and adaptation system with human-in-the-loop shared control, featuring an autonomous online failure detection method named FLOAT. Thanks to FLOAT, ARMADA enables paralleled policy rollout and requests human intervention only when necessary, significantly reducing reliance on human supervision. Hence, ARMADA enables efficient acquisition of in-domain data, and leads to more scalable deployment and faster adaptation to new scenarios. We evaluate the performance of ARMADA on four real-world tasks. FLOAT achieves nearly 95% accuracy on average, surpassing prior state-of-the-art failure detection approaches by over 20%. Besides, ARMADA manifests more than 4$\times$ increase in success rate and greater than 2$\times$ reduction in human intervention rate over multiple rounds of policy rollout and post-training, compared to previous human-in-the-loop learning methods.
Right-Side-Out: Learning Zero-Shot Sim-to-Real Garment Reversal
Sep 19, 2025Turning garments right-side out is a challenging manipulation task: it is highly dynamic, entails rapid contact changes, and is subject to severe visual occlusion. We introduce Right-Side-Out, a zero-shot sim-to-real framework that effectively solves this challenge by exploiting task structures. We decompose the task into Drag/Fling to create and stabilize an access opening, followed by Insert&Pull to invert the garment. Each step uses a depth-inferred, keypoint-parameterized bimanual primitive that sharply reduces the action space while preserving robustness. Efficient data generation is enabled by our custom-built, high-fidelity, GPU-parallel Material Point Method (MPM) simulator that models thin-shell deformation and provides robust and efficient contact handling for batched rollouts. Built on the simulator, our fully automated pipeline scales data generation by randomizing garment geometry, material parameters, and viewpoints, producing depth, masks, and per-primitive keypoint labels without any human annotations. With a single depth camera, policies trained entirely in simulation deploy zero-shot on real hardware, achieving up to 81.3% success rate. By employing task decomposition and high fidelity simulation, our framework enables tackling highly dynamic, severely occluded tasks without laborious human demonstrations.
FBI: Learning Dexterous In-hand Manipulation with Dynamic Visuotactile Shortcut Policy
Aug 20, 2025



Dexterous in-hand manipulation is a long-standing challenge in robotics due to complex contact dynamics and partial observability. While humans synergize vision and touch for such tasks, robotic approaches often prioritize one modality, therefore limiting adaptability. This paper introduces Flow Before Imitation (FBI), a visuotactile imitation learning framework that dynamically fuses tactile interactions with visual observations through motion dynamics. Unlike prior static fusion methods, FBI establishes a causal link between tactile signals and object motion via a dynamics-aware latent model. FBI employs a transformer-based interaction module to fuse flow-derived tactile features with visual inputs, training a one-step diffusion policy for real-time execution. Extensive experiments demonstrate that the proposed method outperforms the baseline methods in both simulation and the real world on two customized in-hand manipulation tasks and three standard dexterous manipulation tasks. Code, models, and more results are available in the website https://sites.google.com/view/dex-fbi.
AgentWorld: An Interactive Simulation Platform for Scene Construction and Mobile Robotic Manipulation
Aug 13, 2025We introduce AgentWorld, an interactive simulation platform for developing household mobile manipulation capabilities. Our platform combines automated scene construction that encompasses layout generation, semantic asset placement, visual material configuration, and physics simulation, with a dual-mode teleoperation system supporting both wheeled bases and humanoid locomotion policies for data collection. The resulting AgentWorld Dataset captures diverse tasks ranging from primitive actions (pick-and-place, push-pull, etc.) to multistage activities (serve drinks, heat up food, etc.) across living rooms, bedrooms, and kitchens. Through extensive benchmarking of imitation learning methods including behavior cloning, action chunking transformers, diffusion policies, and vision-language-action models, we demonstrate the dataset's effectiveness for sim-to-real transfer. The integrated system provides a comprehensive solution for scalable robotic skill acquisition in complex home environments, bridging the gap between simulation-based training and real-world deployment. The code, datasets will be available at https://yizhengzhang1.github.io/agent_world/
ArtGS:3D Gaussian Splatting for Interactive Visual-Physical Modeling and Manipulation of Articulated Objects
Jul 03, 2025Articulated object manipulation remains a critical challenge in robotics due to the complex kinematic constraints and the limited physical reasoning of existing methods. In this work, we introduce ArtGS, a novel framework that extends 3D Gaussian Splatting (3DGS) by integrating visual-physical modeling for articulated object understanding and interaction. ArtGS begins with multi-view RGB-D reconstruction, followed by reasoning with a vision-language model (VLM) to extract semantic and structural information, particularly the articulated bones. Through dynamic, differentiable 3DGS-based rendering, ArtGS optimizes the parameters of the articulated bones, ensuring physically consistent motion constraints and enhancing the manipulation policy. By leveraging dynamic Gaussian splatting, cross-embodiment adaptability, and closed-loop optimization, ArtGS establishes a new framework for efficient, scalable, and generalizable articulated object modeling and manipulation. Experiments conducted in both simulation and real-world environments demonstrate that ArtGS significantly outperforms previous methods in joint estimation accuracy and manipulation success rates across a variety of articulated objects. Additional images and videos are available on the project website: https://sites.google.com/view/artgs/home
Generalizable Articulated Object Reconstruction from Casually Captured RGBD Videos
Jun 10, 2025Articulated objects are prevalent in daily life. Understanding their kinematic structure and reconstructing them have numerous applications in embodied AI and robotics. However, current methods require carefully captured data for training or inference, preventing practical, scalable, and generalizable reconstruction of articulated objects. We focus on reconstruction of an articulated object from a casually captured RGBD video shot with a hand-held camera. A casually captured video of an interaction with an articulated object is easy to acquire at scale using smartphones. However, this setting is quite challenging, as the object and camera move simultaneously and there are significant occlusions as the person interacts with the object. To tackle these challenges, we introduce a coarse-to-fine framework that infers joint parameters and segments movable parts of the object from a dynamic RGBD video. To evaluate our method under this new setting, we build a 20$\times$ larger synthetic dataset of 784 videos containing 284 objects across 11 categories. We compare our approach with existing methods that also take video as input. Experiments show that our method can reconstruct synthetic and real articulated objects across different categories from dynamic RGBD videos, outperforming existing methods significantly.