 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
Jun 09, 2026We introduce Embodied-R1.5, a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities, spanning embodied cognition, task planning, correction, and pointing, within a single architecture toward general physical intelligence. Leveraging three automated data construction pipelines to significantly expand the data coverage of critical capabilities, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe to alleviate heterogeneous task conflicts. We further introduce a Planner-Grounder-Corrector (PGC) closed-loop framework that enables a single model to autonomously execute and self-correct over long-horizon tasks. With only 8B parameters, Embodied-R1.5 achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5 and GPT-5.4. Benefiting from the internalized embodied capabilities, Embodied-R1.5 can be fine-tuned into a VLA with only a small amount of data, outperforming leading VLA models like $π_{0.5}$ across 4 popular manipulation benchmark suites. We further conduct extensive zero-shot real-robot experiments, validating performance in instruction following, affordance grounding, articulated object manipulation, and long-horizon complex tasks, demonstrating strong generalization to the physical world. We open-source model weights, datasets, training code, and EmbodiedEvalKit, an evaluation framework tailored for embodied tasks, to facilitate future research in EFMs.
Teach Multimodal Recommendation Model to See via Personalized Visual Extraction and Adaptive Learning
Jun 08, 2026Multimodal sequential recommendation (MSR) incorporates textual and visual information to improve recommendation quality. However, recent studies and our empirical analysis show that visual features are often underutilized, thereby contributing far less than textual signals. We attribute this issue to two factors: insufficient visual representation learning (pretrained encoders fail to capture preference-relevant cues) and unbalanced visual-text optimization (textual features dominate the learning process). To address these issues, we propose Teach Multimodal Recommendation Model to See via Personalized Visual Extraction and Adaptive Learning (REVEAL), a plug-and-play framework that enhances visual representation learning and cross-modal optimization without modifying the original recommendation backbone. REVEAL consists of Feedback-Guided Visual Extraction (FVE), which refines prompt-guided visual extraction through task-level feedback, and Adaptive Visual Learning (AVL), which dynamically reweights visual learning to alleviate modality imbalance. Experiments on multiple real-world datasets and MSR backbones demonstrate that REVEAL consistently improves recommendation performance. Further analysis shows that these gains arise from more effective attention to preference-relevant visual regions and better visual utilization during training. The code is available at https://github.com/YutongLi2024/REVEAL.
TROPHIES: Temporal Reconstruction of Places, Humans, and Cameras from Multi-view Videos
Jun 01, 2026Reconstructing humans and their surrounding environments in a globally consistent 4D space is essential for comprehensive perception. However, prior works typically assume single-view inputs or decouple humans, scenes, and cameras, making them unable to recover coherent geometry, stable motion, and physically aligned trajectories. These limitations motivate us to introduce a new task: unified human-scene-camera reconstruction from multi-view videos, which aims to jointly estimate dynamic humans, static scenes, and camera poses in one global coordinate frame. We propose TROPHIES--Temporal Reconstruction of Places, Humans, and Cameras from Multi-view Videos-a unified framework tailored for this task. TROPHIES features a Human Branch that models humans through temporal and spatial reasoning, and a Scene Branch that reconstructs static geometry with human-aware attention. A global alignment and optimization module couples both branches by enforcing scale consistency, contact priors, and cross-view temporal coherence. Experiments on EgoHuman and EgoExo4D demonstrate that TROPHIES achieves globally aligned, physically plausible 4D reconstructions and consistently outperforms existing paradigms in both global fidelity and human-scene consistency.
EchoVQA: Enabling Conversational Assistance for Point-of-Care Cardiac Ultrasound
May 22, 2026Point-of-care transthoracic echocardiography (TTE) enables cardiac assessment in virtually any clinical setting, yet its diagnostic utility remains constrained by the expertise required for image acquisition and interpretation. Visual question answering (VQA) offers a promising paradigm for bridging this expertise gap through interactive clinical assistance, but existing echocardiography VQA datasets are limited in scale, restricted to high-quality images, and only cover a few views. We introduce EchoVQA, the first large-scale VQA dataset for echocardiography, comprising 14,299 images and 74,819 question-answer pairs. The dataset integrates public sources (EchoNet-Dynamic, CAMUS) with our own point-of-care acquisitions from two handheld probes (Lumify, Clarius), spanning diverse views and including both high-quality and suboptimal images. Uniquely, EchoVQA includes acquisition guidance questions to help users optimize transducer positioning toward a diagnostic apical 4-chamber view for left ventricular ejection fraction estimation -- a challenging task for novice operators in point-of-care settings. We further develop a parameter-efficient method based on multimodal learnable prompts achieving state-of-the-art performance on most benchmarks, including EchoVQA, with significantly less trainable parameters than existing state-of-the-art approaches.
DASH-KV: Accelerating Long-Context LLM Inference via Asymmetric KV Cache Hashing
Apr 22, 2026The quadratic computational complexity of the standard attention mechanism constitutes a fundamental bottleneck for large language models in long-context inference. While existing KV cache compression methods alleviate memory pressure, they often sacrifice generation quality and fail to address the high overhead of floating-point arithmetic. This paper introduces DASH-KV, an innovative acceleration framework that reformulates attention as approximate nearest-neighbor search via asymmetric deep hashing. Under this paradigm, we design an asymmetric encoding architecture that differentially maps queries and keys to account for their distinctions in precision and reuse characteristics. To balance efficiency and accuracy, we further introduce a dynamic mixed-precision mechanism that adaptively retains full-precision computation for critical tokens. Extensive experiments on LongBench demonstrate that DASH-KV significantly outperforms state-of-the-art baseline methods while matching the performance of full attention, all while reducing inference complexity from O(N^2) to linear O(N). The code is available at https://github.com/Zhihan-Zh/DASH-KV
ORSIFlow: Saliency-Guided Rectified Flow for Optical Remote Sensing Salient Object Detection
Mar 30, 2026Optical Remote Sensing Image Salient Object Detection (ORSI-SOD) remains challenging due to complex backgrounds, low contrast, irregular object shapes, and large variations in object scale. Existing discriminative methods directly regress saliency maps, while recent diffusion-based generative approaches suffer from stochastic sampling and high computational cost. In this paper, we propose ORSIFlow, a saliency-guided rectified flow framework that reformulates ORSI-SOD as a deterministic latent flow generation problem. ORSIFlow performs saliency mask generation in a compact latent space constructed by a frozen variational autoencoder, enabling efficient inference with only a few steps. To enhance saliency awareness, we design a Salient Feature Discriminator for global semantic discrimination and a Salient Feature Calibrator for precise boundary refinement. Extensive experiments on multiple public benchmarks show that ORSIFlow achieves state-of-the-art performance with significantly improved efficiency. Codes are available at: https://github.com/Ch3nSir/ORSIFlow.
Stereo-Inertial Poser: Towards Metric-Accurate Shape-Aware Motion Capture Using Sparse IMUs and a Single Stereo Camera
Mar 02, 2026Recent advancements in visual-inertial motion capture systems have demonstrated the potential of combining monocular cameras with sparse inertial measurement units (IMUs) as cost-effective solutions, which effectively mitigate occlusion and drift issues inherent in single-modality systems. However, they are still limited by metric inaccuracies in global translations stemming from monocular depth ambiguity, and shape-agnostic local motion estimations that ignore anthropometric variations. We present Stereo-Inertial Poser, a real-time motion capture system that leverages a single stereo camera and six IMUs to estimate metric-accurate and shape-aware 3D human motion. By replacing the monocular RGB with stereo vision, our system resolves depth ambiguity through calibrated baseline geometry, enabling direct 3D keypoint extraction and body shape parameter estimation. IMU data and visual cues are fused for predicting drift-compensated joint positions and root movements, while a novel shape-aware fusion module dynamically harmonizes anthropometry variations with global translations. Our end-to-end pipeline achieves over 200 FPS without optimization-based post-processing, enabling real-time deployment. Quantitative evaluations across various datasets demonstrate state-of-the-art performance. Qualitative results show our method produces drift-free global translation under a long recording time and reduces foot-skating effects.
VISTA-PATH: An interactive foundation model for pathology image segmentation and quantitative analysis in computational pathology
Jan 23, 2026Accurate semantic segmentation for histopathology image is crucial for quantitative tissue analysis and downstream clinical modeling. Recent segmentation foundation models have improved generalization through large-scale pretraining, yet remain poorly aligned with pathology because they treat segmentation as a static visual prediction task. Here we present VISTA-PATH, an interactive, class-aware pathology segmentation foundation model designed to resolve heterogeneous structures, incorporate expert feedback, and produce pixel-level segmentation that are directly meaningful for clinical interpretation. VISTA-PATH jointly conditions segmentation on visual context, semantic tissue descriptions, and optional expert-provided spatial prompts, enabling precise multi-class segmentation across heterogeneous pathology images. To support this paradigm, we curate VISTA-PATH Data, a large-scale pathology segmentation corpus comprising over 1.6 million image-mask-text triplets spanning 9 organs and 93 tissue classes. Across extensive held-out and external benchmarks, VISTA-PATH consistently outperforms existing segmentation foundation models. Importantly, VISTA-PATH supports dynamic human-in-the-loop refinement by propagating sparse, patch-level bounding-box annotation feedback into whole-slide segmentation. Finally, we show that the high-fidelity, class-aware segmentation produced by VISTA-PATH is a preferred model for computational pathology. It improve tissue microenvironment analysis through proposed Tumor Interaction Score (TIS), which exhibits strong and significant associations with patient survival. Together, these results establish VISTA-PATH as a foundation model that elevates pathology image segmentation from a static prediction to an interactive and clinically grounded representation for digital pathology. Source code and demo can be found at https://github.com/zhihuanglab/VISTA-PATH.
PRISM: Personalized Recommendation via Information Synergy Module
Jan 16, 2026Multimodal sequential recommendation (MSR) leverages diverse item modalities to improve recommendation accuracy, while achieving effective and adaptive fusion remains challenging. Existing MSR models often overlook synergistic information that emerges only through modality combinations. Moreover, they typically assume a fixed importance for different modality interactions across users. To address these limitations, we propose \textbf{P}ersonalized \textbf{R}ecommend-ation via \textbf{I}nformation \textbf{S}ynergy \textbf{M}odule (PRISM), a plug-and-play framework for sequential recommendation (SR). PRISM explicitly decomposes multimodal information into unique, redundant, and synergistic components through an Interaction Expert Layer and dynamically weights them via an Adaptive Fusion Layer guided by user preferences. This information-theoretic design enables fine-grained disentanglement and personalized fusion of multimodal signals. Extensive experiments on four datasets and three SR backbones demonstrate its effectiveness and versatility. The code is available at https://github.com/YutongLi2024/PRISM.
WaterFlow: Explicit Physics-Prior Rectified Flow for Underwater Saliency Mask Generation
Oct 14, 2025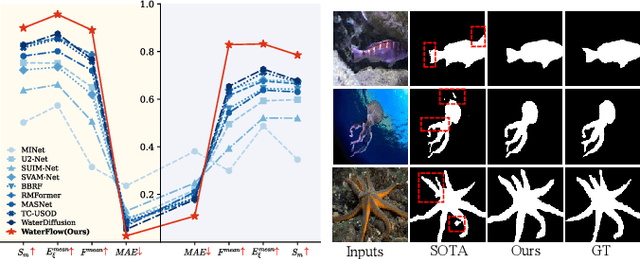
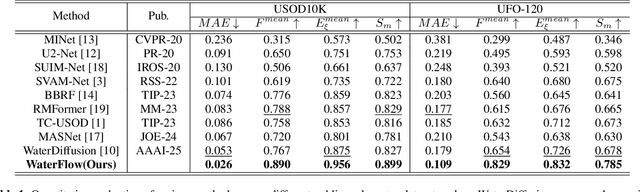
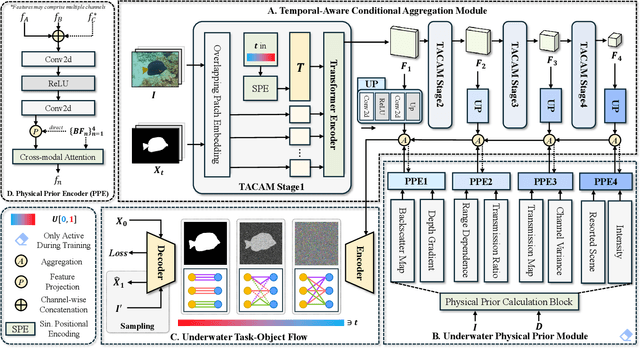

Underwater Salient Object Detection (USOD) faces significant challenges, including underwater image quality degradation and domain gaps. Existing methods tend to ignore the physical principles of underwater imaging or simply treat degradation phenomena in underwater images as interference factors that must be eliminated, failing to fully exploit the valuable information they contain. We propose WaterFlow, a rectified flow-based framework for underwater salient object detection that innovatively incorporates underwater physical imaging information as explicit priors directly into the network training process and introduces temporal dimension modeling, significantly enhancing the model's capability for salient object identification. On the USOD10K dataset, WaterFlow achieves a 0.072 gain in S_m, demonstrating the effectiveness and superiority of our method. The code will be published after the acceptance.