 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProVox: Personalization and Proactive Planning for Situated Human-Robot Collaboration
Jun 13, 2025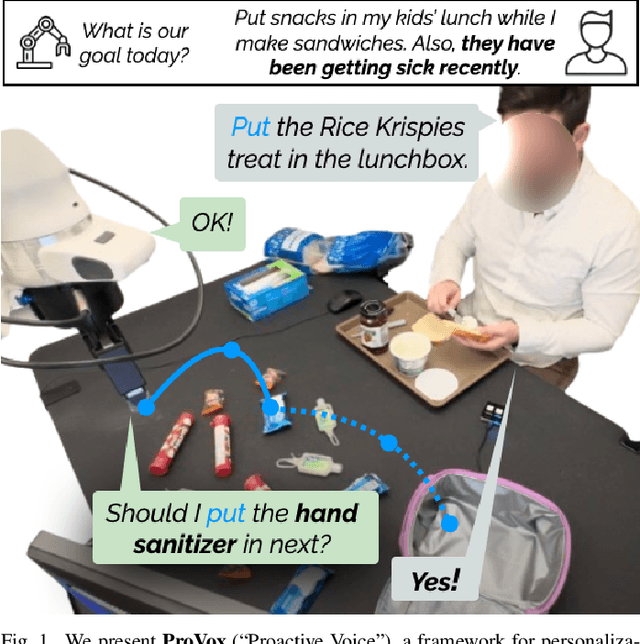
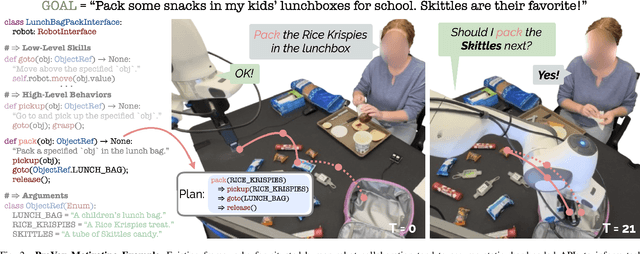
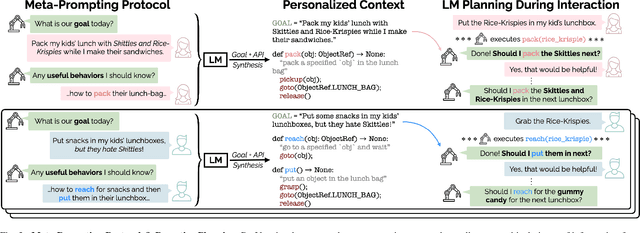

Collaborative robots must quickly adapt to their partner's intent and preferences to proactively identify helpful actions. This is especially true in situated settings where human partners can continually teach robots new high-level behaviors, visual concepts, and physical skills (e.g., through demonstration), growing the robot's capabilities as the human-robot pair work together to accomplish diverse tasks. In this work, we argue that robots should be able to infer their partner's goals from early interactions and use this information to proactively plan behaviors ahead of explicit instructions from the user. Building from the strong commonsense priors and steerability of large language models, we introduce ProVox ("Proactive Voice"), a novel framework that enables robots to efficiently personalize and adapt to individual collaborators. We design a meta-prompting protocol that empowers users to communicate their distinct preferences, intent, and expected robot behaviors ahead of starting a physical interaction. ProVox then uses the personalized prompt to condition a proactive language model task planner that anticipates a user's intent from the current interaction context and robot capabilities to suggest helpful actions; in doing so, we alleviate user burden, minimizing the amount of time partners spend explicitly instructing and supervising the robot. We evaluate ProVox through user studies grounded in household manipulation tasks (e.g., assembling lunch bags) that measure the efficiency of the collaboration, as well as features such as perceived helpfulness, ease of use, and reliability. Our analysis suggests that both meta-prompting and proactivity are critical, resulting in 38.7% faster task completion times and 31.9% less user burden relative to non-active baselines. Supplementary material, code, and videos can be found at https://provox-2025.github.io.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
GHIL-Glue: Hierarchical Control with Filtered Subgoal Images
Oct 26, 2024



Image and video generative models that are pre-trained on Internet-scale data can greatly increase the generalization capacity of robot learning systems. These models can function as high-level planners, generating intermediate subgoals for low-level goal-conditioned policies to reach. However, the performance of these systems can be greatly bottlenecked by the interface between generative models and low-level controllers. For example, generative models may predict photorealistic yet physically infeasible frames that confuse low-level policies. Low-level policies may also be sensitive to subtle visual artifacts in generated goal images. This paper addresses these two facets of generalization, providing an interface to effectively "glue together" language-conditioned image or video prediction models with low-level goal-conditioned policies. Our method, Generative Hierarchical Imitation Learning-Glue (GHIL-Glue), filters out subgoals that do not lead to task progress and improves the robustness of goal-conditioned policies to generated subgoals with harmful visual artifacts. We find in extensive experiments in both simulated and real environments that GHIL-Glue achieves a 25% improvement across several hierarchical models that leverage generative subgoals, achieving a new state-of-the-art on the CALVIN simulation benchmark for policies using observations from a single RGB camera. GHIL-Glue also outperforms other generalist robot policies across 3/4 language-conditioned manipulation tasks testing zero-shot generalization in physical experiments.
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
Sep 05, 2024Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at https://s-tian.github.io/projects/vista.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
RAP: Risk-Aware Prediction for Robust Planning
Oct 04, 2022
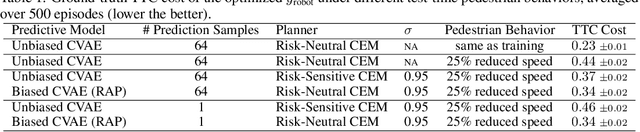
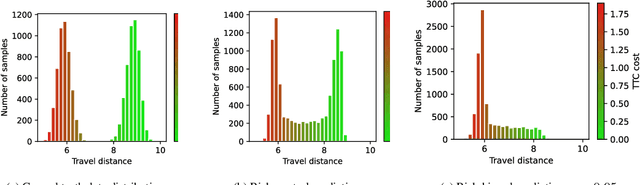
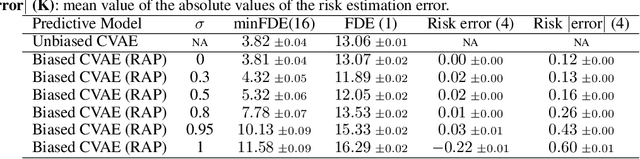
Robust planning in interactive scenarios requires predicting the uncertain future to make risk-aware decisions. Unfortunately, due to long-tail safety-critical events, the risk is often under-estimated by finite-sampling approximations of probabilistic motion forecasts. This can lead to overconfident and unsafe robot behavior, even with robust planners. Instead of assuming full prediction coverage that robust planners require, we propose to make prediction itself risk-aware. We introduce a new prediction objective to learn a risk-biased distribution over trajectories, so that risk evaluation simplifies to an expected cost estimation under this biased distribution. This reduces the sample complexity of the risk estimation during online planning, which is needed for safe real-time performance. Evaluation results in a didactic simulation environment and on a real-world dataset demonstrate the effectiveness of our approach.
Control-Aware Prediction Objectives for Autonomous Driving
Apr 28, 2022
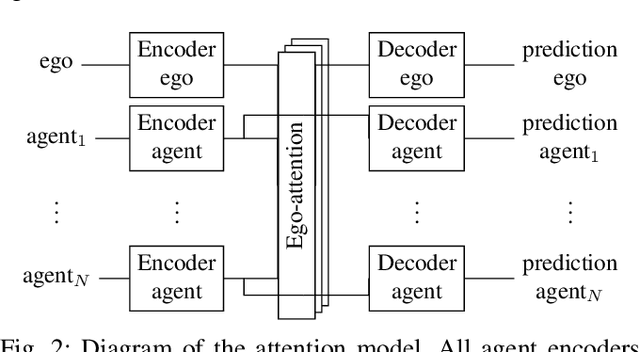
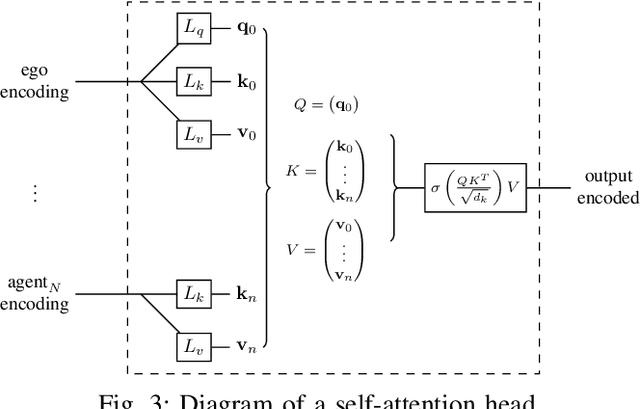

Autonomous vehicle software is typically structured as a modular pipeline of individual components (e.g., perception, prediction, and planning) to help separate concerns into interpretable sub-tasks. Even when end-to-end training is possible, each module has its own set of objectives used for safety assurance, sample efficiency, regularization, or interpretability. However, intermediate objectives do not always align with overall system performance. For example, optimizing the likelihood of a trajectory prediction module might focus more on easy-to-predict agents than safety-critical or rare behaviors (e.g., jaywalking). In this paper, we present control-aware prediction objectives (CAPOs), to evaluate the downstream effect of predictions on control without requiring the planner be differentiable. We propose two types of importance weights that weight the predictive likelihood: one using an attention model between agents, and another based on control variation when exchanging predicted trajectories for ground truth trajectories. Experimentally, we show our objectives improve overall system performance in suburban driving scenarios using the CARLA simulator.
Dynamics-Aware Comparison of Learned Reward Functions
Jan 25, 2022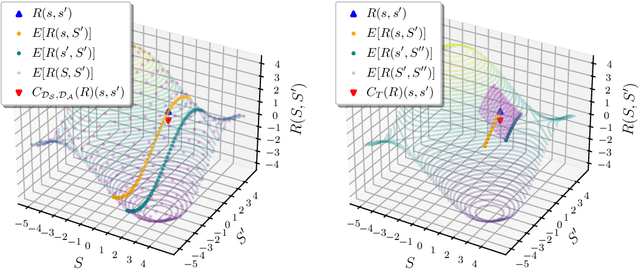
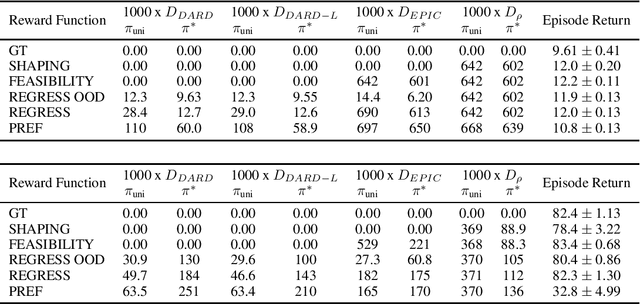
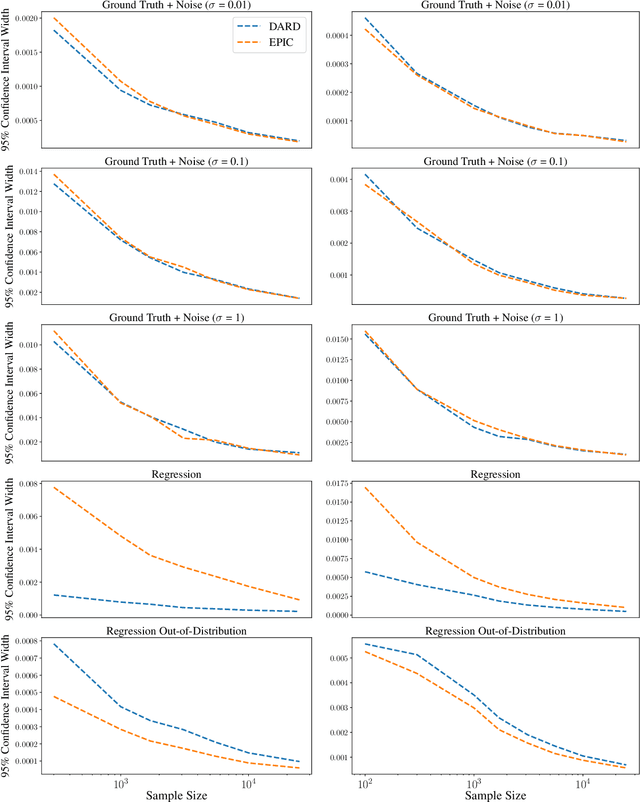
The ability to learn reward functions plays an important role in enabling the deployment of intelligent agents in the real world. However, comparing reward functions, for example as a means of evaluating reward learning methods, presents a challenge. Reward functions are typically compared by considering the behavior of optimized policies, but this approach conflates deficiencies in the reward function with those of the policy search algorithm used to optimize it. To address this challenge, Gleave et al. (2020) propose the Equivalent-Policy Invariant Comparison (EPIC) distance. EPIC avoids policy optimization, but in doing so requires computing reward values at transitions that may be impossible under the system dynamics. This is problematic for learned reward functions because it entails evaluating them outside of their training distribution, resulting in inaccurate reward values that we show can render EPIC ineffective at comparing rewards. To address this problem, we propose the Dynamics-Aware Reward Distance (DARD), a new reward pseudometric. DARD uses an approximate transition model of the environment to transform reward functions into a form that allows for comparisons that are invariant to reward shaping while only evaluating reward functions on transitions close to their training distribution. Experiments in simulated physical domains demonstrate that DARD enables reliable reward comparisons without policy optimization and is significantly more predictive than baseline methods of downstream policy performance when dealing with learned reward functions.
Heterogeneous-Agent Trajectory Forecasting Incorporating Class Uncertainty
Apr 26, 2021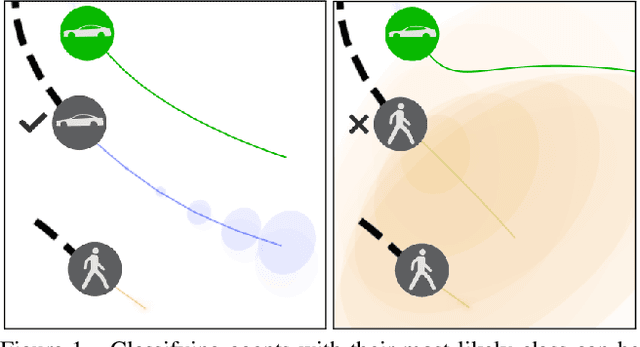
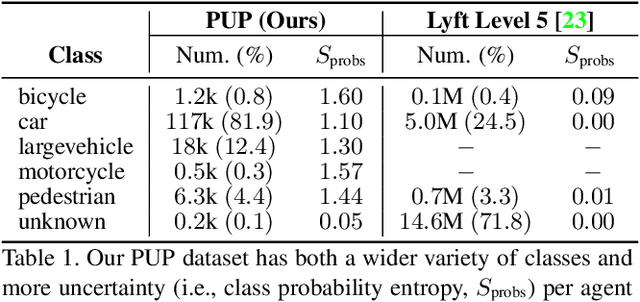
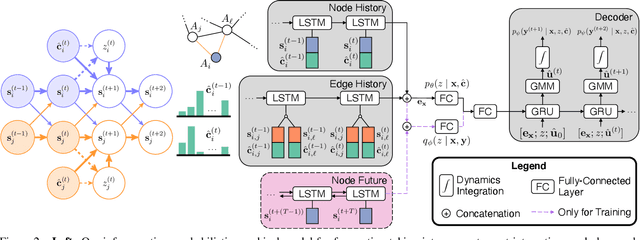

Reasoning about the future behavior of other agents is critical to safe robot navigation. The multiplicity of plausible futures is further amplified by the uncertainty inherent to agent state estimation from data, including positions, velocities, and semantic class. Forecasting methods, however, typically neglect class uncertainty, conditioning instead only on the agent's most likely class, even though perception models often return full class distributions. To exploit this information, we present HAICU, a method for heterogeneous-agent trajectory forecasting that explicitly incorporates agents' class probabilities. We additionally present PUP, a new challenging real-world autonomous driving dataset, to investigate the impact of Perceptual Uncertainty in Prediction. It contains challenging crowded scenes with unfiltered agent class probabilities that reflect the long-tail of current state-of-the-art perception systems. We demonstrate that incorporating class probabilities in trajectory forecasting significantly improves performance in the face of uncertainty, and enables new forecasting capabilities such as counterfactual predictions.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
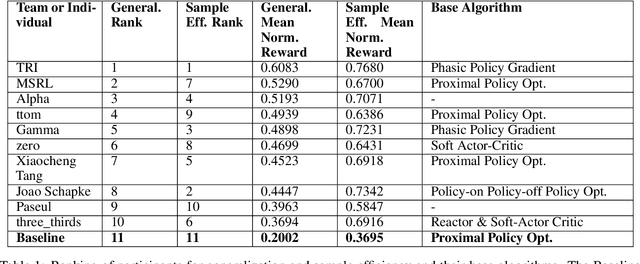
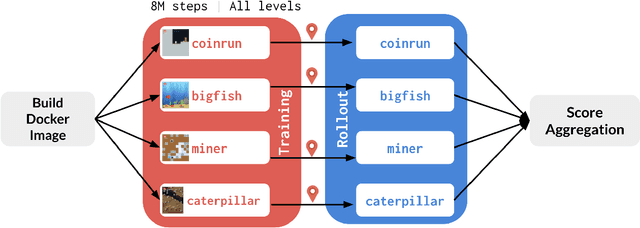
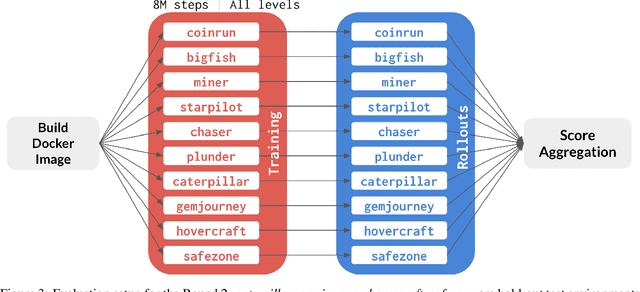
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.