 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUPERNOVA: Eliciting General Reasoning in LLMs with Reinforcement Learning on Natural Instructions
Apr 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has significantly improved large language model (LLM) reasoning in formal domains such as mathematics and code. Despite these advancements, LLMs still struggle with general reasoning tasks requiring capabilities such as causal inference and temporal understanding. Extending RLVR to general reasoning is fundamentally constrained by the lack of high-quality, verifiable training data that spans diverse reasoning skills. To address this challenge, we propose SUPERNOVA, a data curation framework for RLVR aimed at enhancing general reasoning. Our key insight is that instruction-tuning datasets containing expert-annotated ground-truth encode rich reasoning patterns that can be systematically adapted for RLVR. To study this, we conduct 100+ controlled RL experiments to analyze how data design choices impact downstream reasoning performance. In particular, we investigate three key factors: (i) source task selection, (ii) task mixing strategies, and (iii) synthetic interventions for improving data quality. Our analysis reveals that source task selection is non-trivial and has a significant impact on downstream reasoning performance. Moreover, selecting tasks based on their performance for individual target tasks outperforms strategies based on overall average performance. Finally, models trained on SUPERNOVA outperform strong baselines (e.g., Qwen3.5) on challenging reasoning benchmarks including BBEH, Zebralogic, and MMLU-Pro. In particular, training on SUPERNOVA yields relative improvements of up to 52.8\% on BBEH across model sizes, demonstrating the effectiveness of principled data curation for RLVR. Our findings provide practical insights for curating human-annotated resources to extend RLVR to general reasoning. The code and data is available at https://github.com/asuvarna31/supernova.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
LaViDa: A Large Diffusion Language Model for Multimodal Understanding
May 22, 2025Modern Vision-Language Models (VLMs) can solve a wide range of tasks requiring visual reasoning. In real-world scenarios, desirable properties for VLMs include fast inference and controllable generation (e.g., constraining outputs to adhere to a desired format). However, existing autoregressive (AR) VLMs like LLaVA struggle in these aspects. Discrete diffusion models (DMs) offer a promising alternative, enabling parallel decoding for faster inference and bidirectional context for controllable generation through text-infilling. While effective in language-only settings, DMs' potential for multimodal tasks is underexplored. We introduce LaViDa, a family of VLMs built on DMs. We build LaViDa by equipping DMs with a vision encoder and jointly fine-tune the combined parts for multimodal instruction following. To address challenges encountered, LaViDa incorporates novel techniques such as complementary masking for effective training, prefix KV cache for efficient inference, and timestep shifting for high-quality sampling. Experiments show that LaViDa achieves competitive or superior performance to AR VLMs on multi-modal benchmarks such as MMMU, while offering unique advantages of DMs, including flexible speed-quality tradeoff, controllability, and bidirectional reasoning. On COCO captioning, LaViDa surpasses Open-LLaVa-Next-8B by +4.1 CIDEr with 1.92x speedup. On bidirectional tasks, it achieves +59% improvement on Constrained Poem Completion. These results demonstrate LaViDa as a strong alternative to AR VLMs. Code and models will be released in the camera-ready version.
When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning
Apr 01, 2025Scaling test-time compute has emerged as a key strategy for enhancing the reasoning capabilities of large language models (LLMs), particularly in tasks like mathematical problem-solving. A traditional approach, Self-Consistency (SC), generates multiple solutions to a problem and selects the most common answer via majority voting. Another common method involves scoring each solution with a reward model (verifier) and choosing the best one. Recent advancements in Generative Reward Models (GenRM) reframe verification as a next-token prediction task, enabling inference-time scaling along a new axis. Specifically, GenRM generates multiple verification chains-of-thought to score each solution. Under a limited inference budget, this introduces a fundamental trade-off: should you spend the budget on scaling solutions via SC or generate fewer solutions and allocate compute to verification via GenRM? To address this, we evaluate GenRM against SC under a fixed inference budget. Interestingly, we find that SC is more compute-efficient than GenRM for most practical inference budgets across diverse models and datasets. For instance, GenRM first matches SC after consuming up to 8x the inference compute and requires significantly more compute to outperform it. Furthermore, we derive inference scaling laws for the GenRM paradigm, revealing that compute-optimal inference favors scaling solution generation more aggressively than scaling the number of verifications. Our work provides practical guidance on optimizing test-time scaling by balancing solution generation and verification. The code is available at https://github.com/nishadsinghi/sc-genrm-scaling.
OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement
Mar 21, 2025
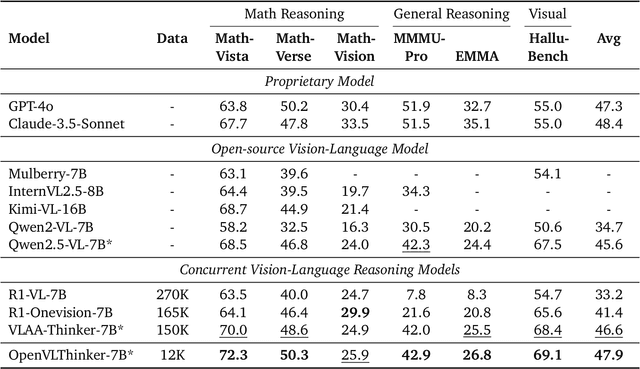
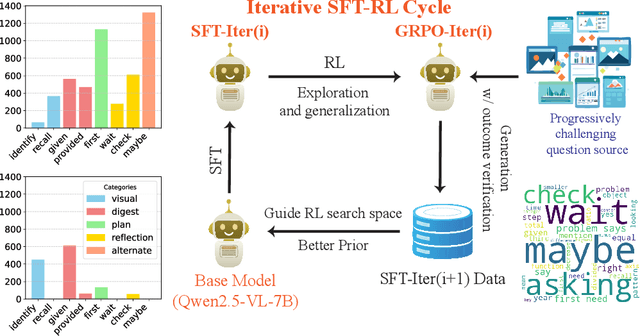
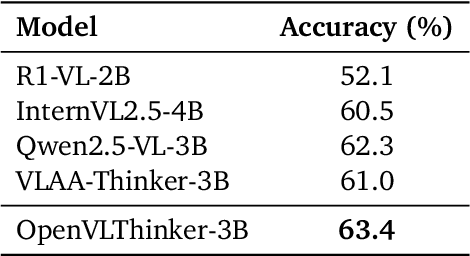
Recent advancements demonstrated by DeepSeek-R1 have shown that complex reasoning abilities in large language models (LLMs), including sophisticated behaviors such as self-verification and self-correction, can be achieved by RL with verifiable rewards and significantly improves model performance on challenging tasks such as AIME. Motivated by these findings, our study investigates whether similar reasoning capabilities can be successfully integrated into large vision-language models (LVLMs) and assesses their impact on challenging multimodal reasoning tasks. We consider an approach that iteratively leverages supervised fine-tuning (SFT) on lightweight training data and Reinforcement Learning (RL) to further improve model generalization. Initially, reasoning capabilities were distilled from pure-text R1 models by generating reasoning steps using high-quality captions of the images sourced from diverse visual datasets. Subsequently, iterative RL training further enhance reasoning skills, with each iteration's RL-improved model generating refined SFT datasets for the next round. This iterative process yielded OpenVLThinker, a LVLM exhibiting consistently improved reasoning performance on challenging benchmarks such as MathVista, MathVerse, and MathVision, demonstrating the potential of our strategy for robust vision-language reasoning. The code, model and data are held at https://github.com/yihedeng9/OpenVLThinker.
VideoPhy-2: A Challenging Action-Centric Physical Commonsense Evaluation in Video Generation
Mar 09, 2025Large-scale video generative models, capable of creating realistic videos of diverse visual concepts, are strong candidates for general-purpose physical world simulators. However, their adherence to physical commonsense across real-world actions remains unclear (e.g., playing tennis, backflip). Existing benchmarks suffer from limitations such as limited size, lack of human evaluation, sim-to-real gaps, and absence of fine-grained physical rule analysis. To address this, we introduce VideoPhy-2, an action-centric dataset for evaluating physical commonsense in generated videos. We curate 200 diverse actions and detailed prompts for video synthesis from modern generative models. We perform human evaluation that assesses semantic adherence, physical commonsense, and grounding of physical rules in the generated videos. Our findings reveal major shortcomings, with even the best model achieving only 22% joint performance (i.e., high semantic and physical commonsense adherence) on the hard subset of VideoPhy-2. We find that the models particularly struggle with conservation laws like mass and momentum. Finally, we also train VideoPhy-AutoEval, an automatic evaluator for fast, reliable assessment on our dataset. Overall, VideoPhy-2 serves as a rigorous benchmark, exposing critical gaps in video generative models and guiding future research in physically-grounded video generation. The data and code is available at https://videophy2.github.io/.
BIG-Bench Extra Hard
Feb 26, 2025Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8\% for the best general-purpose model and 44.8\% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
MedMax: Mixed-Modal Instruction Tuning for Training Biomedical Assistants
Dec 17, 2024Recent advancements in mixed-modal generative models have enabled flexible integration of information across image-text content. These models have opened new avenues for developing unified biomedical assistants capable of analyzing biomedical images, answering complex questions about them, and predicting the impact of medical procedures on a patient's health. However, existing resources face challenges such as limited data availability, narrow domain coverage, and restricted sources (e.g., medical papers). To address these gaps, we present MedMax, the first large-scale multimodal biomedical instruction-tuning dataset for mixed-modal foundation models. With 1.47 million instances, MedMax encompasses a diverse range of tasks, including multimodal content generation (interleaved image-text data), biomedical image captioning and generation, visual chatting, and report understanding. These tasks span diverse medical domains such as radiology and histopathology. Subsequently, we fine-tune a mixed-modal foundation model on the MedMax dataset, achieving significant performance improvements: a 26% gain over the Chameleon model and an 18.3% improvement over GPT-4o across 12 downstream biomedical visual question-answering tasks. Additionally, we introduce a unified evaluation suite for biomedical tasks, providing a robust framework to guide the development of next-generation mixed-modal biomedical AI assistants.
Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
Aug 29, 2024



Training on high-quality synthetic data from strong language models (LMs) is a common strategy to improve the reasoning performance of LMs. In this work, we revisit whether this strategy is compute-optimal under a fixed inference budget (e.g., FLOPs). To do so, we investigate the trade-offs between generating synthetic data using a stronger but more expensive (SE) model versus a weaker but cheaper (WC) model. We evaluate the generated data across three key metrics: coverage, diversity, and false positive rate, and show that the data from WC models may have higher coverage and diversity, but also exhibit higher false positive rates. We then finetune LMs on data from SE and WC models in different settings: knowledge distillation, self-improvement, and a novel weak-to-strong improvement setup where a weaker LM teaches reasoning to a stronger LM. Our findings reveal that models finetuned on WC-generated data consistently outperform those trained on SE-generated data across multiple benchmarks and multiple choices of WC and SE models. These results challenge the prevailing practice of relying on SE models for synthetic data generation, suggesting that WC may be the compute-optimal approach for training advanced LM reasoners.
Generative Verifiers: Reward Modeling as Next-Token Prediction
Aug 27, 2024



Verifiers or reward models are often used to enhance the reasoning performance of large language models (LLMs). A common approach is the Best-of-N method, where N candidate solutions generated by the LLM are ranked by a verifier, and the best one is selected. While LLM-based verifiers are typically trained as discriminative classifiers to score solutions, they do not utilize the text generation capabilities of pretrained LLMs. To overcome this limitation, we instead propose training verifiers using the ubiquitous next-token prediction objective, jointly on verification and solution generation. Compared to standard verifiers, such generative verifiers (GenRM) can benefit from several advantages of LLMs: they integrate seamlessly with instruction tuning, enable chain-of-thought reasoning, and can utilize additional inference-time compute via majority voting for better verification. We demonstrate that when using Gemma-based verifiers on algorithmic and grade-school math reasoning tasks, GenRM outperforms discriminative verifiers and LLM-as-a-Judge, showing a 16-64% improvement in the percentage of problems solved with Best-of-N. Furthermore, we show that GenRM scales favorably across dataset size, model capacity, and inference-time compute.