 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
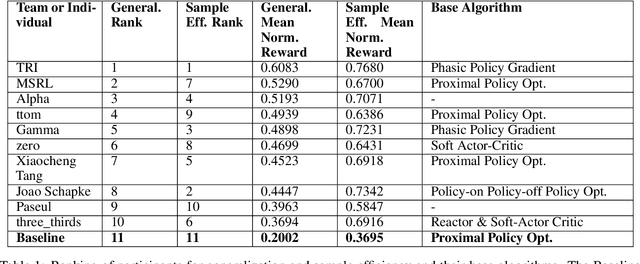
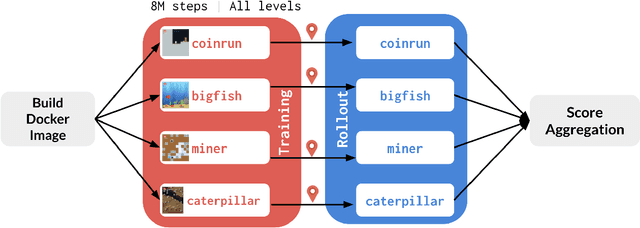
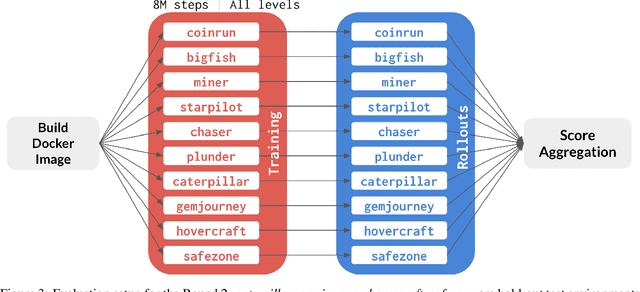
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
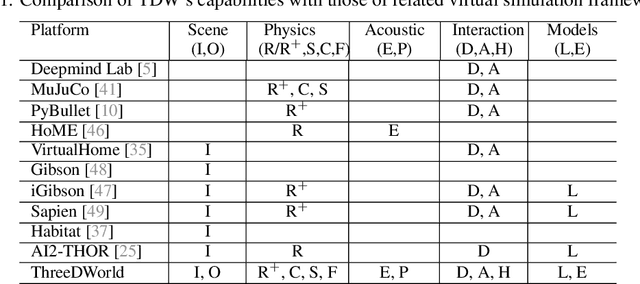

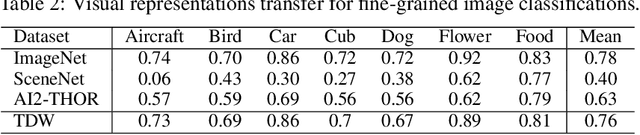
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.
Brain-Like Object Recognition with High-Performing Shallow Recurrent ANNs
Oct 28, 2019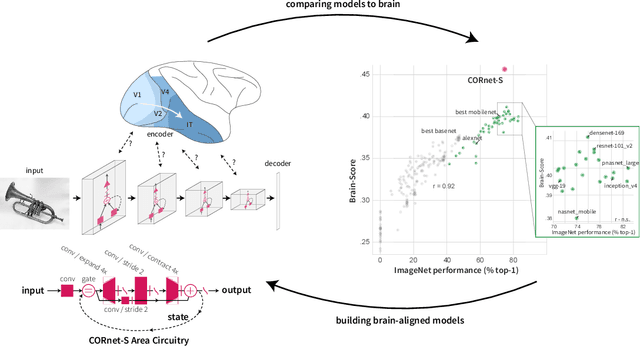
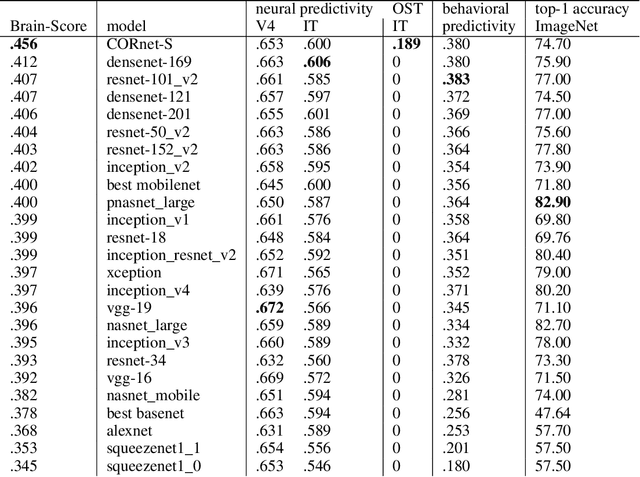
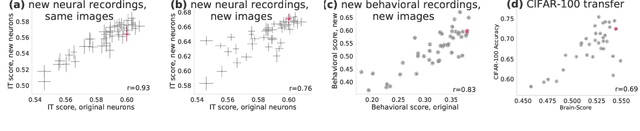

Deep convolutional artificial neural networks (ANNs) are the leading class of candidate models of the mechanisms of visual processing in the primate ventral stream. While initially inspired by brain anatomy, over the past years, these ANNs have evolved from a simple eight-layer architecture in AlexNet to extremely deep and branching architectures, demonstrating increasingly better object categorization performance, yet bringing into question how brain-like they still are. In particular, typical deep models from the machine learning community are often hard to map onto the brain's anatomy due to their vast number of layers and missing biologically-important connections, such as recurrence. Here we demonstrate that better anatomical alignment to the brain and high performance on machine learning as well as neuroscience measures do not have to be in contradiction. We developed CORnet-S, a shallow ANN with four anatomically mapped areas and recurrent connectivity, guided by Brain-Score, a new large-scale composite of neural and behavioral benchmarks for quantifying the functional fidelity of models of the primate ventral visual stream. Despite being significantly shallower than most models, CORnet-S is the top model on Brain-Score and outperforms similarly compact models on ImageNet. Moreover, our extensive analyses of CORnet-S circuitry variants reveal that recurrence is the main predictive factor of both Brain-Score and ImageNet top-1 performance. Finally, we report that the temporal evolution of the CORnet-S "IT" neural population resembles the actual monkey IT population dynamics. Taken together, these results establish CORnet-S, a compact, recurrent ANN, as the current best model of the primate ventral visual stream.
Task-Driven Convolutional Recurrent Models of the Visual System
Oct 27, 2018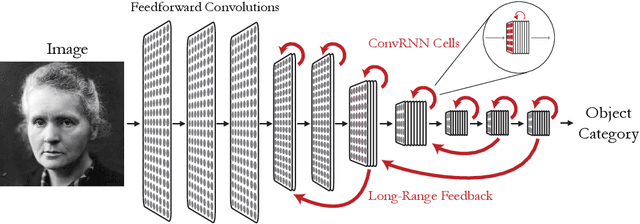
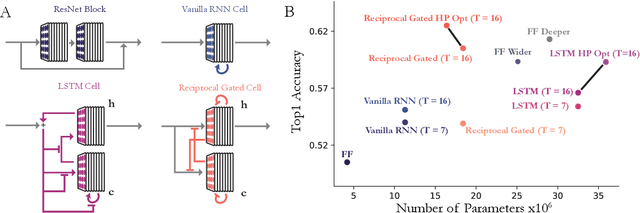
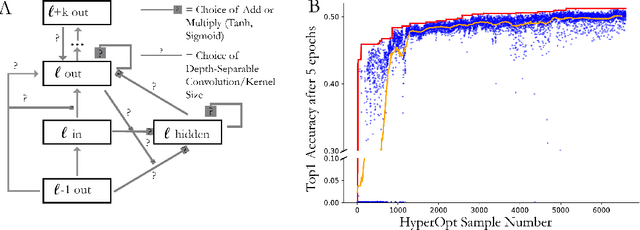
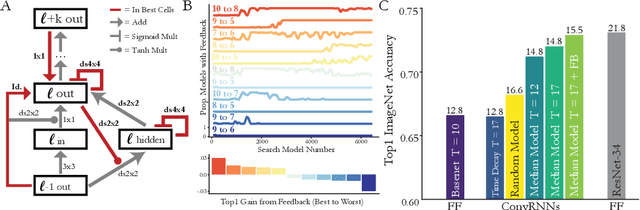
Feed-forward convolutional neural networks (CNNs) are currently state-of-the-art for object classification tasks such as ImageNet. Further, they are quantitatively accurate models of temporally-averaged responses of neurons in the primate brain's visual system. However, biological visual systems have two ubiquitous architectural features not shared with typical CNNs: local recurrence within cortical areas, and long-range feedback from downstream areas to upstream areas. Here we explored the role of recurrence in improving classification performance. We found that standard forms of recurrence (vanilla RNNs and LSTMs) do not perform well within deep CNNs on the ImageNet task. In contrast, novel cells that incorporated two structural features, bypassing and gating, were able to boost task accuracy substantially. We extended these design principles in an automated search over thousands of model architectures, which identified novel local recurrent cells and long-range feedback connections useful for object recognition. Moreover, these task-optimized ConvRNNs matched the dynamics of neural activity in the primate visual system better than feedforward networks, suggesting a role for the brain's recurrent connections in performing difficult visual behaviors.
Toward Goal-Driven Neural Network Models for the Rodent Whisker-Trigeminal System
Jun 23, 2017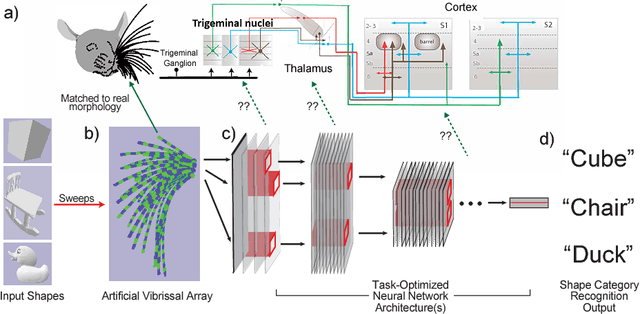
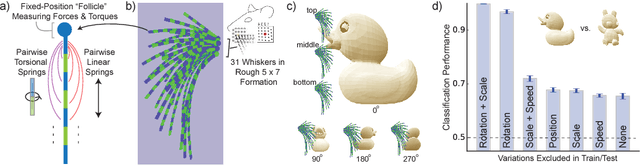
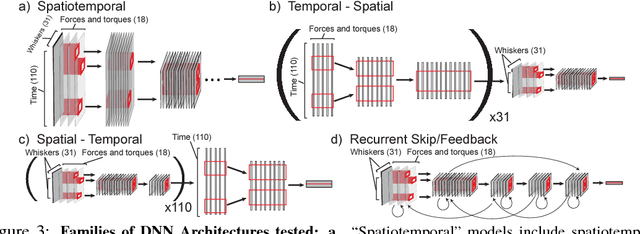
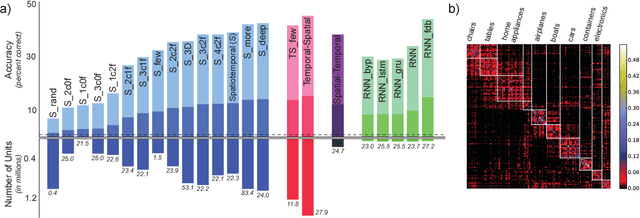
In large part, rodents see the world through their whiskers, a powerful tactile sense enabled by a series of brain areas that form the whisker-trigeminal system. Raw sensory data arrives in the form of mechanical input to the exquisitely sensitive, actively-controllable whisker array, and is processed through a sequence of neural circuits, eventually arriving in cortical regions that communicate with decision-making and memory areas. Although a long history of experimental studies has characterized many aspects of these processing stages, the computational operations of the whisker-trigeminal system remain largely unknown. In the present work, we take a goal-driven deep neural network (DNN) approach to modeling these computations. First, we construct a biophysically-realistic model of the rat whisker array. We then generate a large dataset of whisker sweeps across a wide variety of 3D objects in highly-varying poses, angles, and speeds. Next, we train DNNs from several distinct architectural families to solve a shape recognition task in this dataset. Each architectural family represents a structurally-distinct hypothesis for processing in the whisker-trigeminal system, corresponding to different ways in which spatial and temporal information can be integrated. We find that most networks perform poorly on the challenging shape recognition task, but that specific architectures from several families can achieve reasonable performance levels. Finally, we show that Representational Dissimilarity Matrices (RDMs), a tool for comparing population codes between neural systems, can separate these higher-performing networks with data of a type that could plausibly be collected in a neurophysiological or imaging experiment. Our results are a proof-of-concept that goal-driven DNN networks of the whisker-trigeminal system are potentially within reach.