 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSeer: Training Deeper Search Agents through Reinforcement Learning with Self-Reflection
Oct 21, 2025Search agents have achieved significant advancements in enabling intelligent information retrieval and decision-making within interactive environments. Although reinforcement learning has been employed to train agentic models capable of more dynamic interactive retrieval, existing methods are limited by shallow tool-use depth and the accumulation of errors over multiple iterative interactions. In this paper, we present WebSeer, a more intelligent search agent trained via reinforcement learning enhanced with a self-reflection mechanism. Specifically, we construct a large dataset annotated with reflection patterns and design a two-stage training framework that unifies cold start and reinforcement learning within the self-reflection paradigm for real-world web-based environments, which enables the model to generate longer and more reflective tool-use trajectories. Our approach substantially extends tool-use chains and improves answer accuracy. Using a single 14B model, we achieve state-of-the-art results on HotpotQA and SimpleQA, with accuracies of 72.3% and 90.0%, respectively, and demonstrate strong generalization to out-of-distribution datasets. The code is available at https://github.com/99hgz/WebSeer
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Channel-Independent Federated Traffic Prediction
Aug 06, 2025

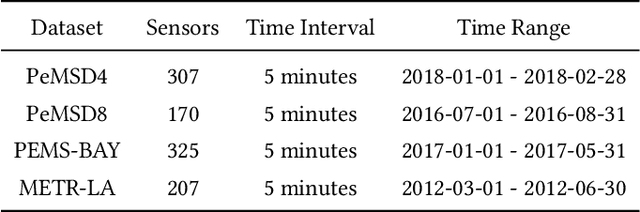

In recent years, traffic prediction has achieved remarkable success and has become an integral component of intelligent transportation systems. However, traffic data is typically distributed among multiple data owners, and privacy constraints prevent the direct utilization of these isolated datasets for traffic prediction. Most existing federated traffic prediction methods focus on designing communication mechanisms that allow models to leverage information from other clients in order to improve prediction accuracy. Unfortunately, such approaches often incur substantial communication overhead, and the resulting transmission delays significantly slow down the training process. As the volume of traffic data continues to grow, this issue becomes increasingly critical, making the resource consumption of current methods unsustainable. To address this challenge, we propose a novel variable relationship modeling paradigm for federated traffic prediction, termed the Channel-Independent Paradigm(CIP). Unlike traditional approaches, CIP eliminates the need for inter-client communication by enabling each node to perform efficient and accurate predictions using only local information. Based on the CIP, we further develop Fed-CI, an efficient federated learning framework, allowing each client to process its own data independently while effectively mitigating the information loss caused by the lack of direct data sharing among clients. Fed-CI significantly reduces communication overhead, accelerates the training process, and achieves state-of-the-art performance while complying with privacy regulations. Extensive experiments on multiple real-world datasets demonstrate that Fed-CI consistently outperforms existing methods across all datasets and federated settings. It achieves improvements of 8%, 14%, and 16% in RMSE, MAE, and MAPE, respectively, while also substantially reducing communication costs.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
Jun 11, 2025Reinforcement learning with verifiable rewards (RLVR) has become a key technique for enhancing large language models (LLMs), with verification engineering playing a central role. However, best practices for RL in instruction following remain underexplored. In this work, we explore the verification challenge in RL for instruction following and propose VerIF, a verification method that combines rule-based code verification with LLM-based verification from a large reasoning model (e.g., QwQ-32B). To support this approach, we construct a high-quality instruction-following dataset, VerInstruct, containing approximately 22,000 instances with associated verification signals. We apply RL training with VerIF to two models, achieving significant improvements across several representative instruction-following benchmarks. The trained models reach state-of-the-art performance among models of comparable size and generalize well to unseen constraints. We further observe that their general capabilities remain unaffected, suggesting that RL with VerIF can be integrated into existing RL recipes to enhance overall model performance. We have released our datasets, codes, and models to facilitate future research at https://github.com/THU-KEG/VerIF.
From Swath to Full-Disc: Advancing Precipitation Retrieval with Multimodal Knowledge Expansion
Jun 08, 2025Accurate near-real-time precipitation retrieval has been enhanced by satellite-based technologies. However, infrared-based algorithms have low accuracy due to weak relations with surface precipitation, whereas passive microwave and radar-based methods are more accurate but limited in range. This challenge motivates the Precipitation Retrieval Expansion (PRE) task, which aims to enable accurate, infrared-based full-disc precipitation retrievals beyond the scanning swath. We introduce Multimodal Knowledge Expansion, a two-stage pipeline with the proposed PRE-Net model. In the Swath-Distilling stage, PRE-Net transfers knowledge from a multimodal data integration model to an infrared-based model within the scanning swath via Coordinated Masking and Wavelet Enhancement (CoMWE). In the Full-Disc Adaptation stage, Self-MaskTune refines predictions across the full disc by balancing multimodal and full-disc infrared knowledge. Experiments on the introduced PRE benchmark demonstrate that PRE-Net significantly advanced precipitation retrieval performance, outperforming leading products like PERSIANN-CCS, PDIR, and IMERG. The code will be available at https://github.com/Zjut-MultimediaPlus/PRE-Net.
S2R-Bench: A Sim-to-Real Evaluation Benchmark for Autonomous Driving
May 24, 2025



Safety is a long-standing and the final pursuit in the development of autonomous driving systems, with a significant portion of safety challenge arising from perception. How to effectively evaluate the safety as well as the reliability of perception algorithms is becoming an emerging issue. Despite its critical importance, existing perception methods exhibit a limitation in their robustness, primarily due to the use of benchmarks are entierly simulated, which fail to align predicted results with actual outcomes, particularly under extreme weather conditions and sensor anomalies that are prevalent in real-world scenarios. To fill this gap, in this study, we propose a Sim-to-Real Evaluation Benchmark for Autonomous Driving (S2R-Bench). We collect diverse sensor anomaly data under various road conditions to evaluate the robustness of autonomous driving perception methods in a comprehensive and realistic manner. This is the first corruption robustness benchmark based on real-world scenarios, encompassing various road conditions, weather conditions, lighting intensities, and time periods. By comparing real-world data with simulated data, we demonstrate the reliability and practical significance of the collected data for real-world applications. We hope that this dataset will advance future research and contribute to the development of more robust perception models for autonomous driving. This dataset is released on https://github.com/adept-thu/S2R-Bench.
BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models
May 23, 2025



The advent of universal time series forecasting models has revolutionized zero-shot forecasting across diverse domains, yet the critical role of data diversity in training these models remains underexplored. Existing large-scale time series datasets often suffer from inherent biases and imbalanced distributions, leading to suboptimal model performance and generalization. To address this gap, we introduce BLAST, a novel pre-training corpus designed to enhance data diversity through a balanced sampling strategy. First, BLAST incorporates 321 billion observations from publicly available datasets and employs a comprehensive suite of statistical metrics to characterize time series patterns. Then, to facilitate pattern-oriented sampling, the data is implicitly clustered using grid-based partitioning. Furthermore, by integrating grid sampling and grid mixup techniques, BLAST ensures a balanced and representative coverage of diverse patterns. Experimental results demonstrate that models pre-trained on BLAST achieve state-of-the-art performance with a fraction of the computational resources and training tokens required by existing methods. Our findings highlight the pivotal role of data diversity in improving both training efficiency and model performance for the universal forecasting task.
AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios
May 22, 2025Large Language Models (LLMs) have demonstrated advanced capabilities in real-world agentic applications. Growing research efforts aim to develop LLM-based agents to address practical demands, introducing a new challenge: agentic scenarios often involve lengthy instructions with complex constraints, such as extended system prompts and detailed tool specifications. While adherence to such instructions is crucial for agentic applications, whether LLMs can reliably follow them remains underexplored. In this paper, we introduce AgentIF, the first benchmark for systematically evaluating LLM instruction following ability in agentic scenarios. AgentIF features three key characteristics: (1) Realistic, constructed from 50 real-world agentic applications. (2) Long, averaging 1,723 words with a maximum of 15,630 words. (3) Complex, averaging 11.9 constraints per instruction, covering diverse constraint types, such as tool specifications and condition constraints. To construct AgentIF, we collect 707 human-annotated instructions across 50 agentic tasks from industrial application agents and open-source agentic systems. For each instruction, we annotate the associated constraints and corresponding evaluation metrics, including code-based evaluation, LLM-based evaluation, and hybrid code-LLM evaluation. We use AgentIF to systematically evaluate existing advanced LLMs. We observe that current models generally perform poorly, especially in handling complex constraint structures and tool specifications. We further conduct error analysis and analytical experiments on instruction length and meta constraints, providing some findings about the failure modes of existing LLMs. We have released the code and data to facilitate future research.
EduBench: A Comprehensive Benchmarking Dataset for Evaluating Large Language Models in Diverse Educational Scenarios
May 22, 2025As large language models continue to advance, their application in educational contexts remains underexplored and under-optimized. In this paper, we address this gap by introducing the first diverse benchmark tailored for educational scenarios, incorporating synthetic data containing 9 major scenarios and over 4,000 distinct educational contexts. To enable comprehensive assessment, we propose a set of multi-dimensional evaluation metrics that cover 12 critical aspects relevant to both teachers and students. We further apply human annotation to ensure the effectiveness of the model-generated evaluation responses. Additionally, we succeed to train a relatively small-scale model on our constructed dataset and demonstrate that it can achieve performance comparable to state-of-the-art large models (e.g., Deepseek V3, Qwen Max) on the test set. Overall, this work provides a practical foundation for the development and evaluation of education-oriented language models. Code and data are released at https://github.com/ybai-nlp/EduBench.