 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHijacking Large Audio-Language Models via Context-Agnostic and Imperceptible Auditory Prompt Injection
Apr 16, 2026Modern Large audio-language models (LALMs) power intelligent voice interactions by tightly integrating audio and text. This integration, however, expands the attack surface beyond text and introduces vulnerabilities in the continuous, high-dimensional audio channel. While prior work studied audio jailbreaks, the security risks of malicious audio injection and downstream behavior manipulation remain underexamined. In this work, we reveal a previously overlooked threat, auditory prompt injection, under realistic constraints of audio data-only access and strong perceptual stealth. To systematically analyze this threat, we propose \textit{AudioHijack}, a general framework that generates context-agnostic and imperceptible adversarial audio to hijack LALMs. \textit{AudioHijack} employs sampling-based gradient estimation for end-to-end optimization across diverse models, bypassing non-differentiable audio tokenization. Through attention supervision and multi-context training, it steers model attention toward adversarial audio and generalizes to unseen user contexts. We also design a convolutional blending method that modulates perturbations into natural reverberation, making them highly imperceptible to users. Extensive experiments on 13 state-of-the-art LALMs show consistent hijacking across 6 misbehavior categories, achieving average success rates of 79\%-96\% on unseen user contexts with high acoustic fidelity. Real-world studies demonstrate that commercial voice agents from Mistral AI and Microsoft Azure can be induced to execute unauthorized actions on behalf of users. These findings expose critical vulnerabilities in LALMs and highlight the urgent need for dedicated defense.
SCOT: Multi-Source Cross-City Transfer with Optimal-Transport Soft-Correspondence Objective
Apr 08, 2026Cross-city transfer improves prediction in label-scarce cities by leveraging labeled data from other cities, but it becomes challenging when cities adopt incompatible partitions and no ground-truth region correspondences exist. Existing approaches either rely on heuristic region matching, which is often sensitive to anchor choices, or perform distribution-level alignment that leaves correspondences implicit and can be unstable under strong heterogeneity. We propose SCOT, a cross-city representation learning framework that learns explicit soft correspondences between unequal region sets via Sinkhorn-based entropic optimal transport. SCOT further sharpens transferable structure with an OT-weighted contrastive objective and stabilizes optimization through a cycle-style reconstruction regularizer. For multi-source transfer, SCOT aligns each source and the target to a shared prototype hub using balanced entropic transport guided by a target-induced prototype prior. Across real-world cities and tasks, SCOT consistently improves transfer accuracy and robustness, while the learned transport couplings and hub assignments provide interpretable diagnostics of alignment quality.
STEP: Detecting Audio Backdoor Attacks via Stability-based Trigger Exposure Profiling
Mar 18, 2026With the widespread deployment of deep-learning-based speech models in security-critical applications, backdoor attacks have emerged as a serious threat: an adversary who poisons a small fraction of training data can implant a hidden trigger that controls the model's output while preserving normal behavior on clean inputs. Existing inference-time defenses are not well suited to the audio domain, as they either rely on trigger over-robustness assumptions that fail on transformation-based and semantic triggers, or depend on properties specific to image or text modalities. In this paper, we propose STEP (Stability-based Trigger Exposure Profiling), a black-box, retraining-free backdoor detector that operates under hard-label-only access. Its core idea is to exploit a characteristic dual anomaly of backdoor triggers: anomalous label stability under semantic-breaking perturbations, and anomalous label fragility under semantic-preserving perturbations. STEP profiles each test sample with two complementary perturbation branches that target these two properties respectively, scores the resulting stability features with one-class anomaly detectors trained on benign references, and fuses the two scores via unsupervised weighting. Extensive experiments across seven backdoor attacks show that STEP achieves an average AUROC of 97.92% and EER of 4.54%, substantially outperforming state-of-the-art baselines, and generalizes across model architectures, speech tasks, an open-set verification scenario, and over-the-air physical-world settings.
ECHO-2: A Large-Scale Distributed Rollout Framework for Cost-Efficient Reinforcement Learning
Feb 03, 2026Reinforcement learning (RL) is a critical stage in post-training large language models (LLMs), involving repeated interaction between rollout generation, reward evaluation, and centralized learning. Distributing rollout execution offers opportunities to leverage more cost-efficient inference resources, but introduces challenges in wide-area coordination and policy dissemination. We present ECHO-2, a distributed RL framework for post-training with remote inference workers and non-negligible dissemination latency. ECHO-2 combines centralized learning with distributed rollouts and treats bounded policy staleness as a user-controlled parameter, enabling rollout generation, dissemination, and training to overlap. We introduce an overlap-based capacity model that relates training time, dissemination latency, and rollout throughput, yielding a practical provisioning rule for sustaining learner utilization. To mitigate dissemination bottlenecks and lower cost, ECHO-2 employs peer-assisted pipelined broadcast and cost-aware activation of heterogeneous workers. Experiments on GRPO post-training of 4B and 8B models under real wide-area bandwidth regimes show that ECHO-2 significantly improves cost efficiency while preserving RL reward comparable to strong baselines.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Channel-Independent Federated Traffic Prediction
Aug 06, 2025

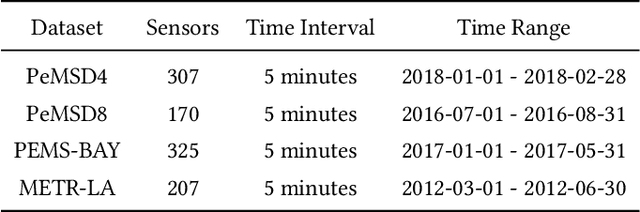

In recent years, traffic prediction has achieved remarkable success and has become an integral component of intelligent transportation systems. However, traffic data is typically distributed among multiple data owners, and privacy constraints prevent the direct utilization of these isolated datasets for traffic prediction. Most existing federated traffic prediction methods focus on designing communication mechanisms that allow models to leverage information from other clients in order to improve prediction accuracy. Unfortunately, such approaches often incur substantial communication overhead, and the resulting transmission delays significantly slow down the training process. As the volume of traffic data continues to grow, this issue becomes increasingly critical, making the resource consumption of current methods unsustainable. To address this challenge, we propose a novel variable relationship modeling paradigm for federated traffic prediction, termed the Channel-Independent Paradigm(CIP). Unlike traditional approaches, CIP eliminates the need for inter-client communication by enabling each node to perform efficient and accurate predictions using only local information. Based on the CIP, we further develop Fed-CI, an efficient federated learning framework, allowing each client to process its own data independently while effectively mitigating the information loss caused by the lack of direct data sharing among clients. Fed-CI significantly reduces communication overhead, accelerates the training process, and achieves state-of-the-art performance while complying with privacy regulations. Extensive experiments on multiple real-world datasets demonstrate that Fed-CI consistently outperforms existing methods across all datasets and federated settings. It achieves improvements of 8%, 14%, and 16% in RMSE, MAE, and MAPE, respectively, while also substantially reducing communication costs.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
DPN-GAN: Inducing Periodic Activations in Generative Adversarial Networks for High-Fidelity Audio Synthesis
May 14, 2025



In recent years, generative adversarial networks (GANs) have made significant progress in generating audio sequences. However, these models typically rely on bandwidth-limited mel-spectrograms, which constrain the resolution of generated audio sequences, and lead to mode collapse during conditional generation. To address this issue, we propose Deformable Periodic Network based GAN (DPN-GAN), a novel GAN architecture that incorporates a kernel-based periodic ReLU activation function to induce periodic bias in audio generation. This innovative approach enhances the model's ability to capture and reproduce intricate audio patterns. In particular, our proposed model features a DPN module for multi-resolution generation utilizing deformable convolution operations, allowing for adaptive receptive fields that improve the quality and fidelity of the synthetic audio. Additionally, we enhance the discriminator network using deformable convolution to better distinguish between real and generated samples, further refining the audio quality. We trained two versions of the model: DPN-GAN small (38.67M parameters) and DPN-GAN large (124M parameters). For evaluation, we use five different datasets, covering both speech synthesis and music generation tasks, to demonstrate the efficiency of the DPN-GAN. The experimental results demonstrate that DPN-GAN delivers superior performance on both out-of-distribution and noisy data, showcasing its robustness and adaptability. Trained across various datasets, DPN-GAN outperforms state-of-the-art GAN architectures on standard evaluation metrics, and exhibits increased robustness in synthesized audio.
Boosting the Class-Incremental Learning in 3D Point Clouds via Zero-Collection-Cost Basic Shape Pre-Training
Apr 11, 2025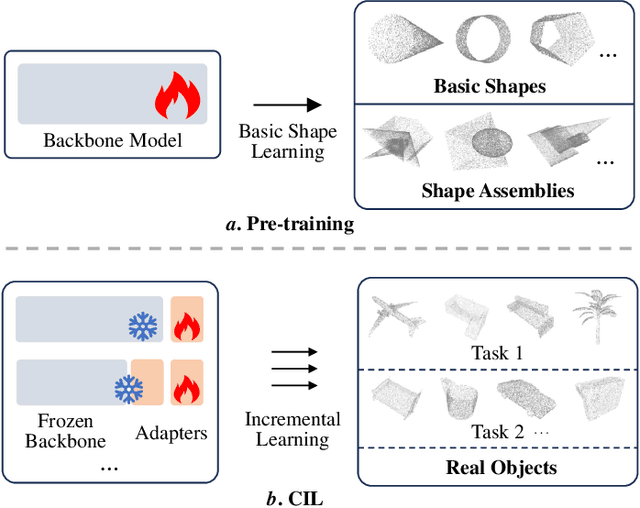
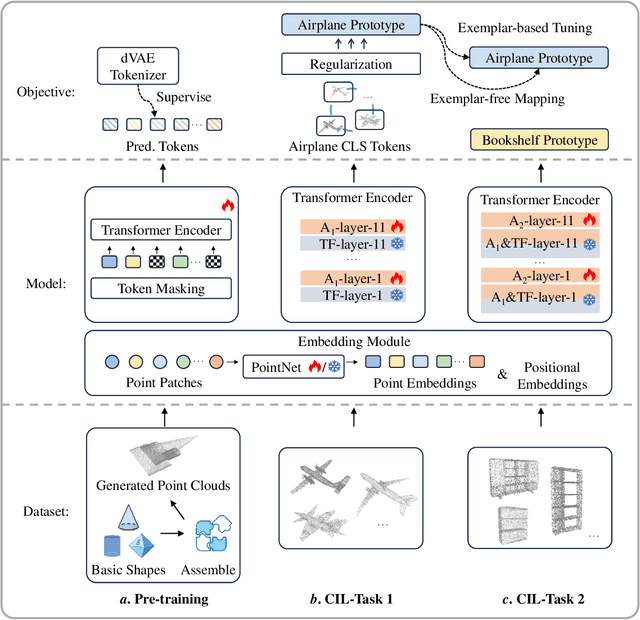
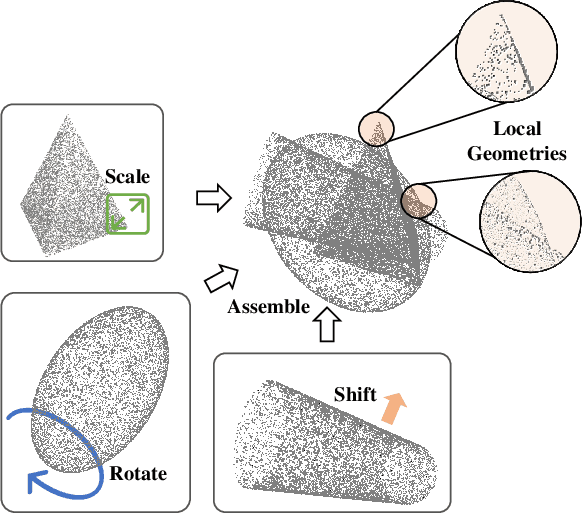
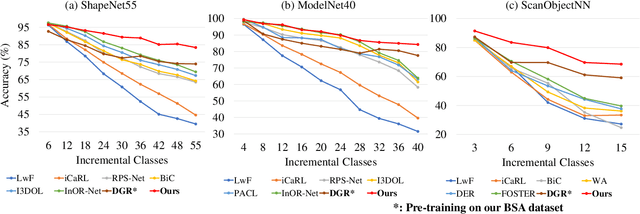
Existing class-incremental learning methods in 3D point clouds rely on exemplars (samples of former classes) to resist the catastrophic forgetting of models, and exemplar-free settings will greatly degrade the performance. For exemplar-free incremental learning, the pre-trained model methods have achieved state-of-the-art results in 2D domains. However, these methods cannot be migrated to the 3D domains due to the limited pre-training datasets and insufficient focus on fine-grained geometric details. This paper breaks through these limitations, proposing a basic shape dataset with zero collection cost for model pre-training. It helps a model obtain extensive knowledge of 3D geometries. Based on this, we propose a framework embedded with 3D geometry knowledge for incremental learning in point clouds, compatible with exemplar-free (-based) settings. In the incremental stage, the geometry knowledge is extended to represent objects in point clouds. The class prototype is calculated by regularizing the data representation with the same category and is kept adjusting in the learning process. It helps the model remember the shape features of different categories. Experiments show that our method outperforms other baseline methods by a large margin on various benchmark datasets, considering both exemplar-free (-based) settings.