 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROBIN : A Benchmark for Robustness to Individual Nuisances in Real-World Out-of-Distribution Shifts
Dec 02, 2021
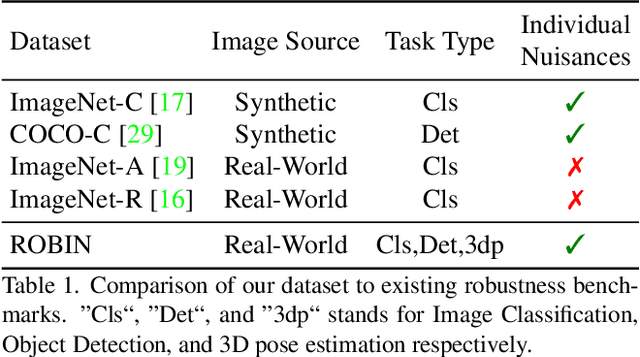

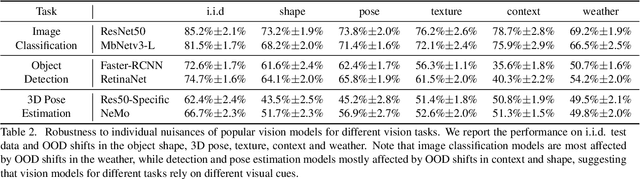
Enhancing the robustness in real-world scenarios has been proven very challenging. One reason is that existing robustness benchmarks are limited, as they either rely on synthetic data or they simply measure robustness as generalization between datasets and hence ignore the effects of individual nuisance factors. In this work, we introduce ROBIN, a benchmark dataset for diagnosing the robustness of vision algorithms to individual nuisances in real-world images. ROBIN builds on 10 rigid categories from the PASCAL VOC 2012 and ImageNet datasets and includes out-of-distribution examples of the objects 3D pose, shape, texture, context and weather conditions. ROBIN is richly annotated to enable benchmark models for image classification, object detection, and 3D pose estimation. We provide results for a number of popular baselines and make several interesting observations: 1. Some nuisance factors have a much stronger negative effect on the performance compared to others. Moreover, the negative effect of an OODnuisance depends on the downstream vision task. 2. Current approaches to enhance OOD robustness using strong data augmentation have only marginal effects in real-world OOD scenarios, and sometimes even reduce the OOD performance. 3. We do not observe any significant differences between convolutional and transformer architectures in terms of OOD robustness. We believe our dataset provides a rich testbed to study the OOD robustness of vision algorithms and will help to significantly push forward research in this area.
PartImageNet: A Large, High-Quality Dataset of Parts
Dec 02, 2021
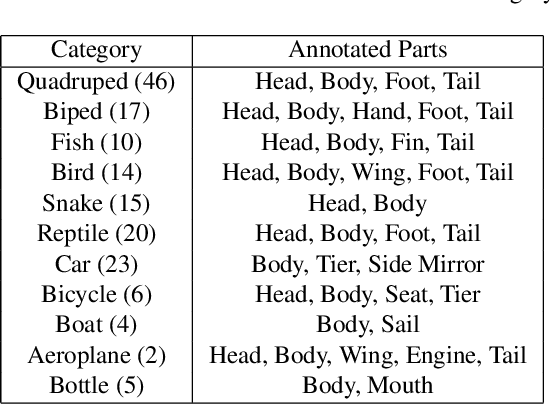

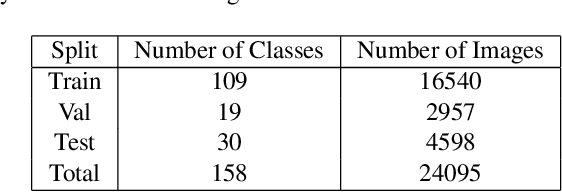
A part-based object understanding facilitates efficient compositional learning and knowledge transfer, robustness to occlusion, and has the potential to increase the performance on general recognition and localization tasks. However, research on part-based models is hindered due to the lack of datasets with part annotations, which is caused by the extreme difficulty and high cost of annotating object parts in images. In this paper, we propose PartImageNet, a large, high-quality dataset with part segmentation annotations. It consists of 158 classes from ImageNet with approximately 24000 images. PartImageNet is unique because it offers part-level annotations on a general set of classes with non-rigid, articulated objects, while having an order of magnitude larger size compared to existing datasets. It can be utilized in multiple vision tasks including but not limited to: Part Discovery, Semantic Segmentation, Few-shot Learning. Comprehensive experiments are conducted to set up a set of baselines on PartImageNet and we find that existing works on part discovery can not always produce satisfactory results during complex variations. The exploit of parts on downstream tasks also remains insufficient. We believe that our PartImageNet will greatly facilitate the research on part-based models and their applications. The dataset and scripts will soon be released at https://github.com/TACJu/PartImageNet.
TransMix: Attend to Mix for Vision Transformers
Nov 18, 2021
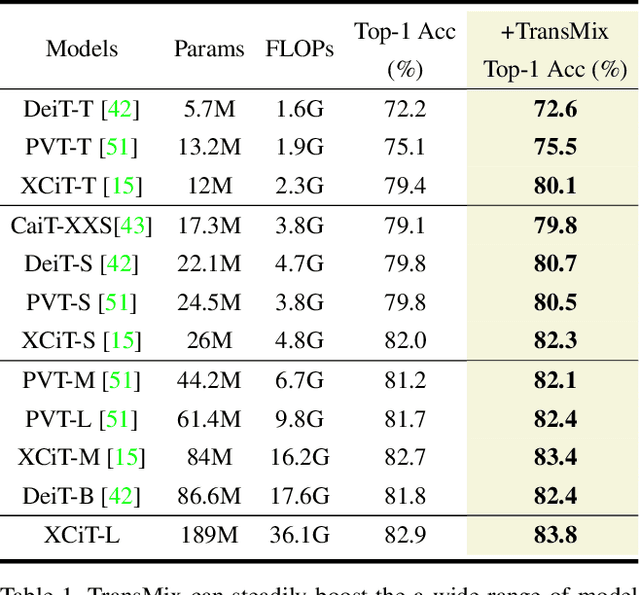
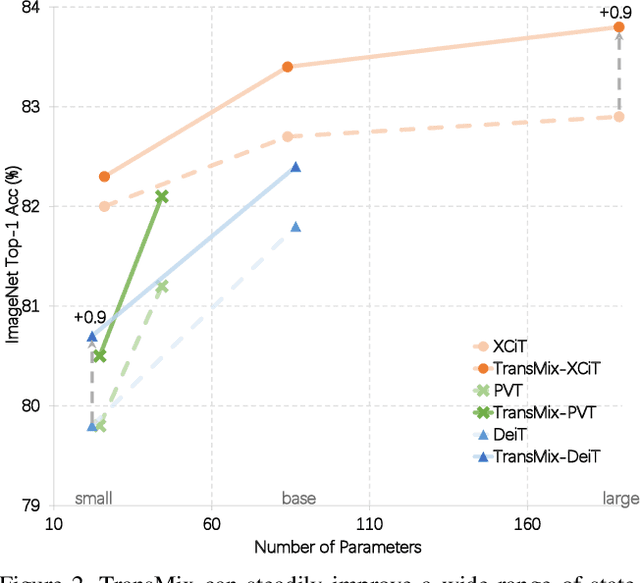

Mixup-based augmentation has been found to be effective for generalizing models during training, especially for Vision Transformers (ViTs) since they can easily overfit. However, previous mixup-based methods have an underlying prior knowledge that the linearly interpolated ratio of targets should be kept the same as the ratio proposed in input interpolation. This may lead to a strange phenomenon that sometimes there is no valid object in the mixed image due to the random process in augmentation but there is still response in the label space. To bridge such gap between the input and label spaces, we propose TransMix, which mixes labels based on the attention maps of Vision Transformers. The confidence of the label will be larger if the corresponding input image is weighted higher by the attention map. TransMix is embarrassingly simple and can be implemented in just a few lines of code without introducing any extra parameters and FLOPs to ViT-based models. Experimental results show that our method can consistently improve various ViT-based models at scales on ImageNet classification. After pre-trained with TransMix on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection and instance segmentation. TransMix also exhibits to be more robust when evaluating on 4 different benchmarks. Code will be made publicly available at https://github.com/Beckschen/TransMix.
Occluded Video Instance Segmentation: Dataset and ICCV 2021 Challenge
Nov 15, 2021


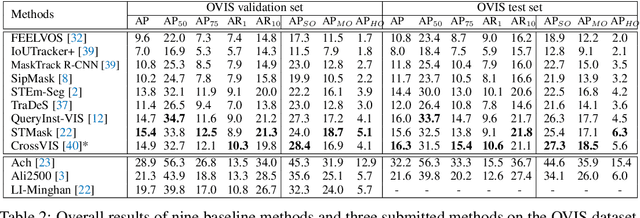
Although deep learning methods have achieved advanced video object recognition performance in recent years, perceiving heavily occluded objects in a video is still a very challenging task. To promote the development of occlusion understanding, we collect a large-scale dataset called OVIS for video instance segmentation in the occluded scenario. OVIS consists of 296k high-quality instance masks and 901 occluded scenes. While our human vision systems can perceive those occluded objects by contextual reasoning and association, our experiments suggest that current video understanding systems cannot. On the OVIS dataset, all baseline methods encounter a significant performance degradation of about 80% in the heavily occluded object group, which demonstrates that there is still a long way to go in understanding obscured objects and videos in a complex real-world scenario. To facilitate the research on new paradigms for video understanding systems, we launched a challenge based on the OVIS dataset. The submitted top-performing algorithms have achieved much higher performance than our baselines. In this paper, we will introduce the OVIS dataset and further dissect it by analyzing the results of baselines and submitted methods. The OVIS dataset and challenge information can be found at http://songbai.site/ovis .
iBOT: Image BERT Pre-Training with Online Tokenizer
Nov 15, 2021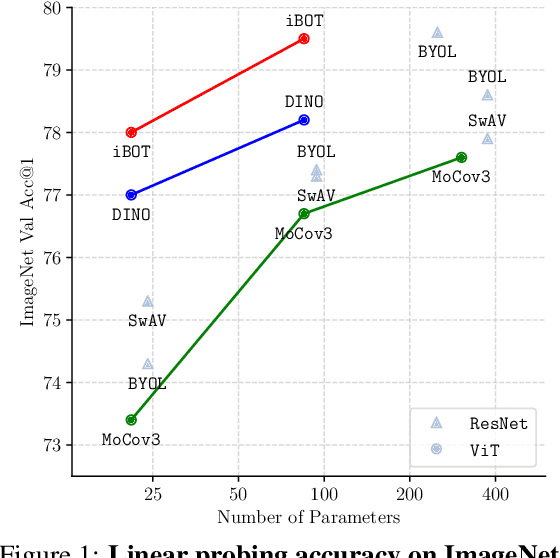
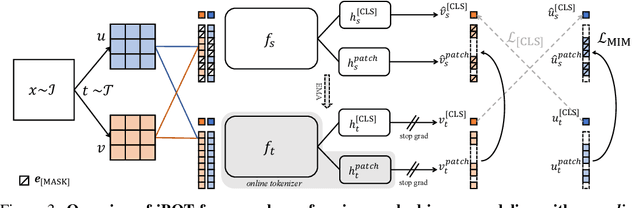
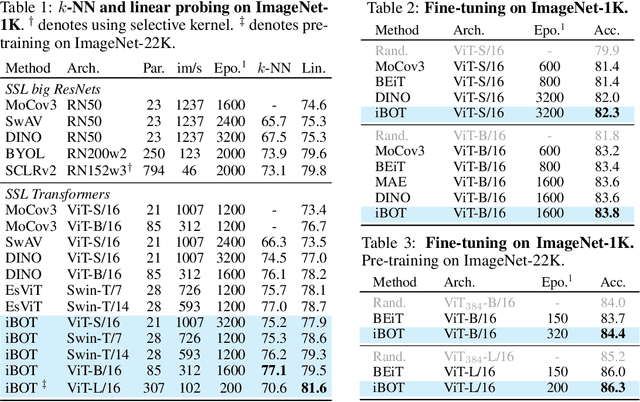
The success of language Transformers is primarily attributed to the pretext task of masked language modeling (MLM), where texts are first tokenized into semantically meaningful pieces. In this work, we study masked image modeling (MIM) and indicate the advantages and challenges of using a semantically meaningful visual tokenizer. We present a self-supervised framework iBOT that can perform masked prediction with an online tokenizer. Specifically, we perform self-distillation on masked patch tokens and take the teacher network as the online tokenizer, along with self-distillation on the class token to acquire visual semantics. The online tokenizer is jointly learnable with the MIM objective and dispenses with a multi-stage training pipeline where the tokenizer needs to be pre-trained beforehand. We show the prominence of iBOT by achieving an 81.6% linear probing accuracy and an 86.3% fine-tuning accuracy evaluated on ImageNet-1K. Beyond the state-of-the-art image classification results, we underline emerging local semantic patterns, which helps the models to obtain strong robustness against common corruptions and achieve leading results on dense downstream tasks, eg., object detection, instance segmentation, and semantic segmentation.
Searching for TrioNet: Combining Convolution with Local and Global Self-Attention
Nov 15, 2021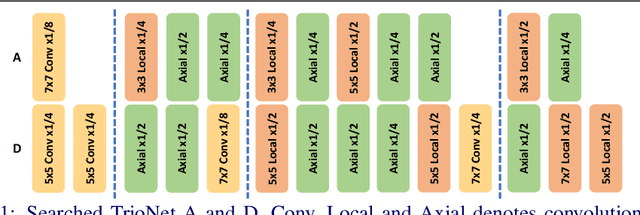
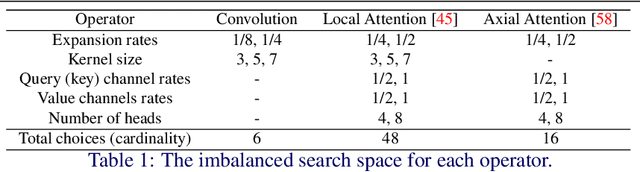
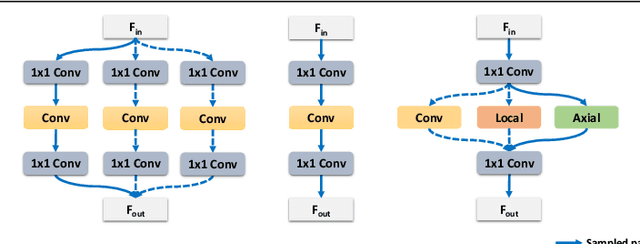
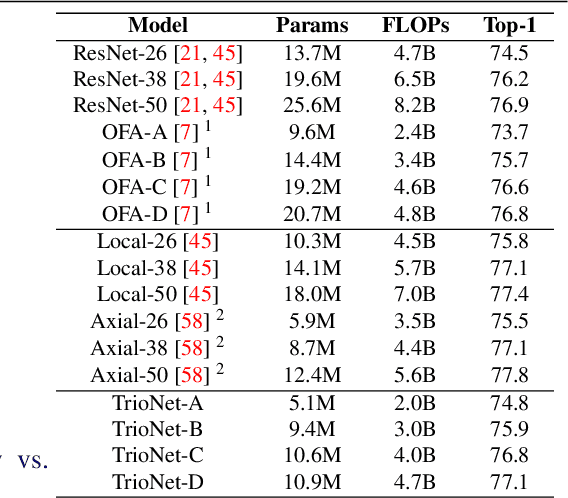
Recently, self-attention operators have shown superior performance as a stand-alone building block for vision models. However, existing self-attention models are often hand-designed, modified from CNNs, and obtained by stacking one operator only. A wider range of architecture space which combines different self-attention operators and convolution is rarely explored. In this paper, we explore this novel architecture space with weight-sharing Neural Architecture Search (NAS) algorithms. The result architecture is named TrioNet for combining convolution, local self-attention, and global (axial) self-attention operators. In order to effectively search in this huge architecture space, we propose Hierarchical Sampling for better training of the supernet. In addition, we propose a novel weight-sharing strategy, Multi-head Sharing, specifically for multi-head self-attention operators. Our searched TrioNet that combines self-attention and convolution outperforms all stand-alone models with fewer FLOPs on ImageNet classification where self-attention performs better than convolution. Furthermore, on various small datasets, we observe inferior performance for self-attention models, but our TrioNet is still able to match the best operator, convolution in this case. Our code is available at https://github.com/phj128/TrioNet.
Are Transformers More Robust Than CNNs?
Nov 10, 2021

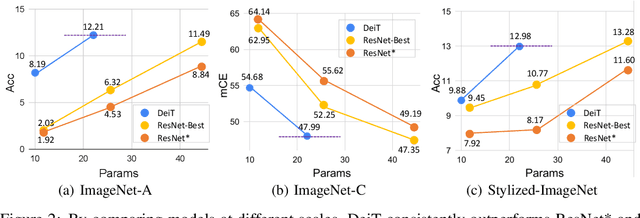
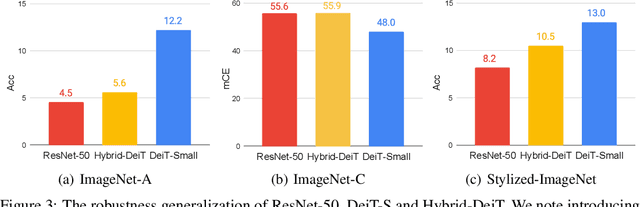
Transformer emerges as a powerful tool for visual recognition. In addition to demonstrating competitive performance on a broad range of visual benchmarks, recent works also argue that Transformers are much more robust than Convolutions Neural Networks (CNNs). Nonetheless, surprisingly, we find these conclusions are drawn from unfair experimental settings, where Transformers and CNNs are compared at different scales and are applied with distinct training frameworks. In this paper, we aim to provide the first fair & in-depth comparisons between Transformers and CNNs, focusing on robustness evaluations. With our unified training setup, we first challenge the previous belief that Transformers outshine CNNs when measuring adversarial robustness. More surprisingly, we find CNNs can easily be as robust as Transformers on defending against adversarial attacks, if they properly adopt Transformers' training recipes. While regarding generalization on out-of-distribution samples, we show pre-training on (external) large-scale datasets is not a fundamental request for enabling Transformers to achieve better performance than CNNs. Moreover, our ablations suggest such stronger generalization is largely benefited by the Transformer's self-attention-like architectures per se, rather than by other training setups. We hope this work can help the community better understand and benchmark the robustness of Transformers and CNNs. The code and models are publicly available at https://github.com/ytongbai/ViTs-vs-CNNs.
Neural View Synthesis and Matching for Semi-Supervised Few-Shot Learning of 3D Pose
Oct 27, 2021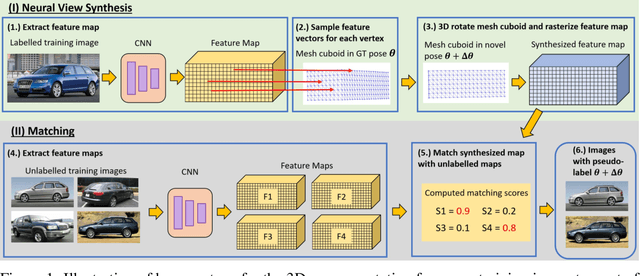
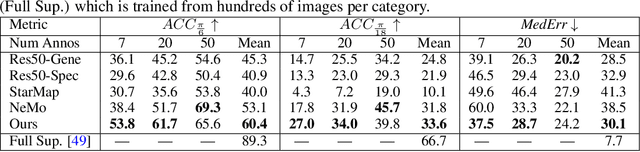

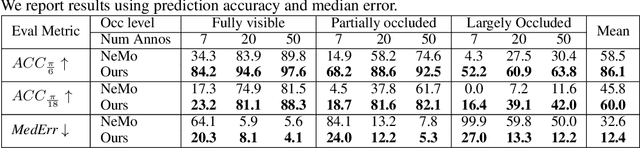
We study the problem of learning to estimate the 3D object pose from a few labelled examples and a collection of unlabelled data. Our main contribution is a learning framework, neural view synthesis and matching, that can transfer the 3D pose annotation from the labelled to unlabelled images reliably, despite unseen 3D views and nuisance variations such as the object shape, texture, illumination or scene context. In our approach, objects are represented as 3D cuboid meshes composed of feature vectors at each mesh vertex. The model is initialized from a few labelled images and is subsequently used to synthesize feature representations of unseen 3D views. The synthesized views are matched with the feature representations of unlabelled images to generate pseudo-labels of the 3D pose. The pseudo-labelled data is, in turn, used to train the feature extractor such that the features at each mesh vertex are more invariant across varying 3D views of the object. Our model is trained in an EM-type manner alternating between increasing the 3D pose invariance of the feature extractor and annotating unlabelled data through neural view synthesis and matching. We demonstrate the effectiveness of the proposed semi-supervised learning framework for 3D pose estimation on the PASCAL3D+ and KITTI datasets. We find that our approach outperforms all baselines by a wide margin, particularly in an extreme few-shot setting where only 7 annotated images are given. Remarkably, we observe that our model also achieves an exceptional robustness in out-of-distribution scenarios that involve partial occlusion.
A Light-weight Interpretable CompositionalNetwork for Nuclei Detection and Weakly-supervised Segmentation
Oct 26, 2021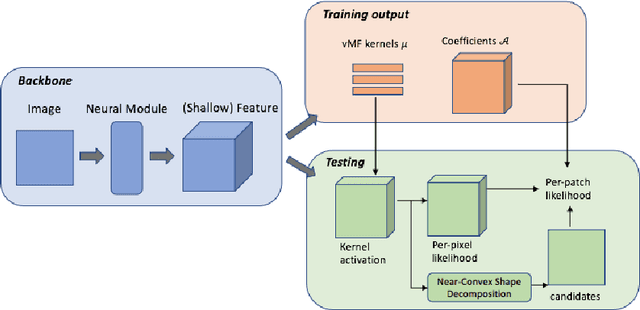
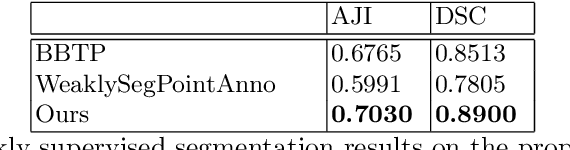
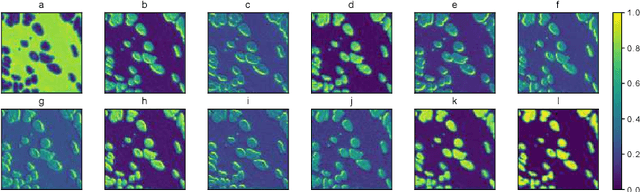
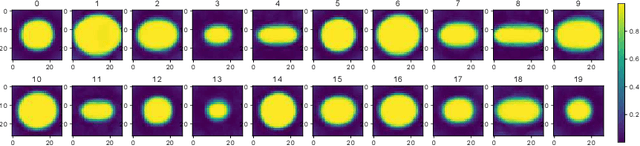
The field of computational pathology has witnessed great advancements since deep neural networks have been widely applied. These deep neural networks usually require large numbers of annotated data to train vast parameters. However, it takes significant effort to annotate a large histopathology dataset. We propose to build a data-efficient model, which only requires partial annotation, specifically on isolated nucleus, rather than on the whole slide image. It exploits shallow features as its backbone and is light-weight, therefore a small number of data is sufficient for training. What's more, it is a generative compositional model, which enjoys interpretability in its prediction. The proposed method could be an alternative solution for the data-hungry problem of deep learning methods.
Nuisance-Label Supervision: Robustness Improvement by Free Labels
Oct 14, 2021
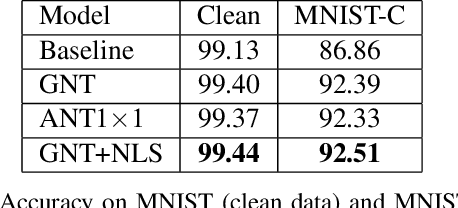
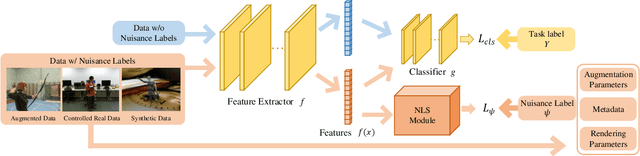

In this paper, we present a Nuisance-label Supervision (NLS) module, which can make models more robust to nuisance factor variations. Nuisance factors are those irrelevant to a task, and an ideal model should be invariant to them. For example, an activity recognition model should perform consistently regardless of the change of clothes and background. But our experiments show existing models are far from this capability. So we explicitly supervise a model with nuisance labels to make extracted features less dependent on nuisance factors. Although the values of nuisance factors are rarely annotated, we demonstrate that besides existing annotations, nuisance labels can be acquired freely from data augmentation and synthetic data. Experiments show consistent improvement in robustness towards image corruption and appearance change in action recognition.