 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Search for Policy Iteration in Continuous Control
Oct 12, 2020
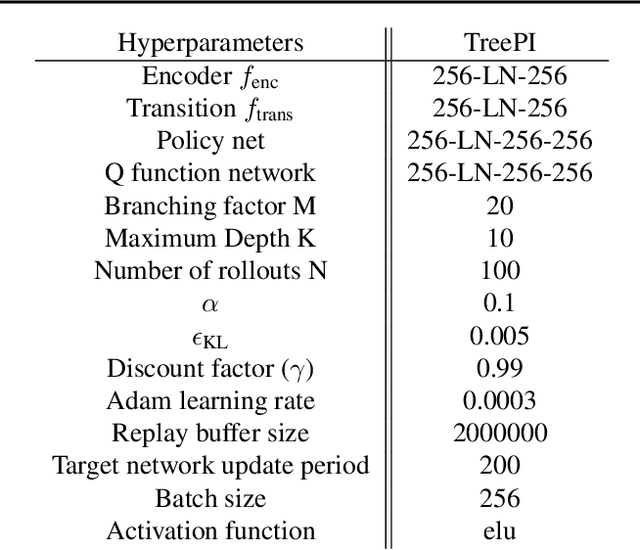
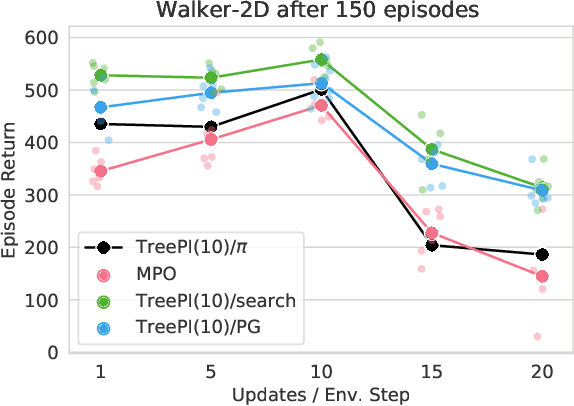

We present an algorithm for local, regularized, policy improvement in reinforcement learning (RL) that allows us to formulate model-based and model-free variants in a single framework. Our algorithm can be interpreted as a natural extension of work on KL-regularized RL and introduces a form of tree search for continuous action spaces. We demonstrate that additional computation spent on model-based policy improvement during learning can improve data efficiency, and confirm that model-based policy improvement during action selection can also be beneficial. Quantitatively, our algorithm improves data efficiency on several continuous control benchmarks (when a model is learned in parallel), and it provides significant improvements in wall-clock time in high-dimensional domains (when a ground truth model is available). The unified framework also helps us to better understand the space of model-based and model-free algorithms. In particular, we demonstrate that some benefits attributed to model-based RL can be obtained without a model, simply by utilizing more computation.
Data-efficient Hindsight Off-policy Option Learning
Jul 30, 2020
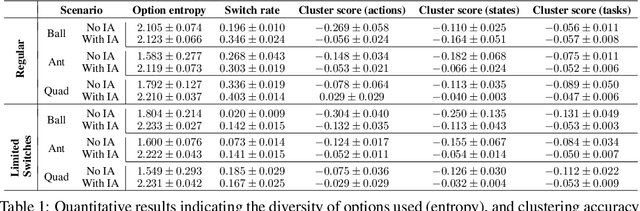


Solutions to most complex tasks can be decomposed into simpler, intermediate skills, reusable across wider ranges of problems. We follow this concept and introduce Hindsight Off-policy Options (HO2), a new algorithm for efficient and robust option learning. The algorithm relies on critic-weighted maximum likelihood estimation and an efficient dynamic programming inference procedure over off-policy trajectories. We can backpropagate through the inference procedure through time and the policy components for every time-step, making it possible to train all component's parameters off-policy, independently of the data-generating behavior policy. Experimentally, we demonstrate that HO2 outperforms competitive baselines and solves demanding robot stacking and ball-in-cup tasks from raw pixel inputs in simulation. We further compare autoregressive option policies with simple mixture policies, providing insights into the relative impact of two types of abstractions common in the options framework: action abstraction and temporal abstraction. Finally, we illustrate challenges caused by stale data in off-policy options learning and provide effective solutions.
Acme: A Research Framework for Distributed Reinforcement Learning
Jun 01, 2020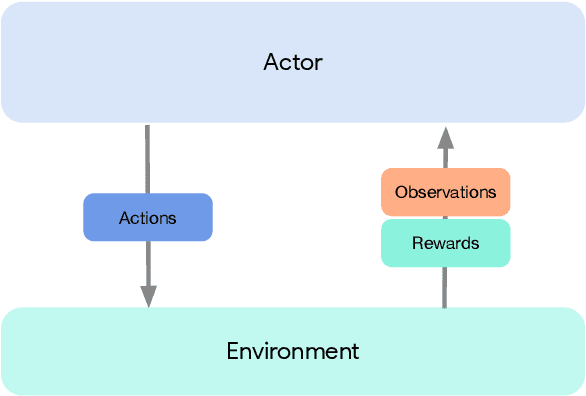
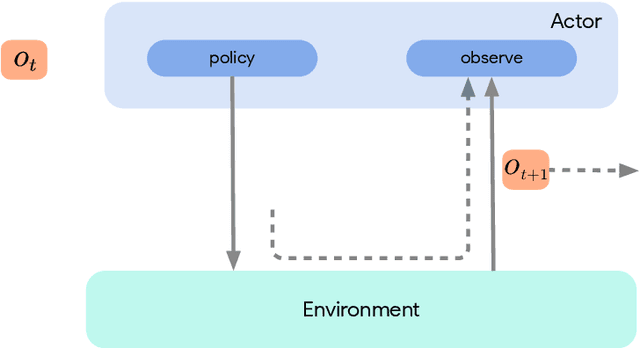
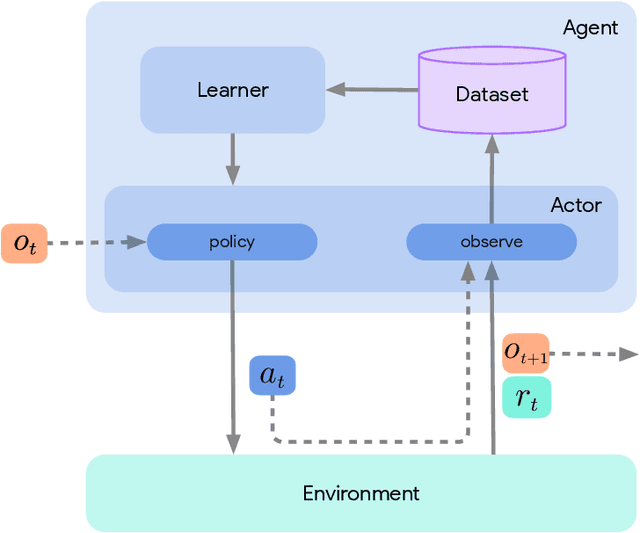
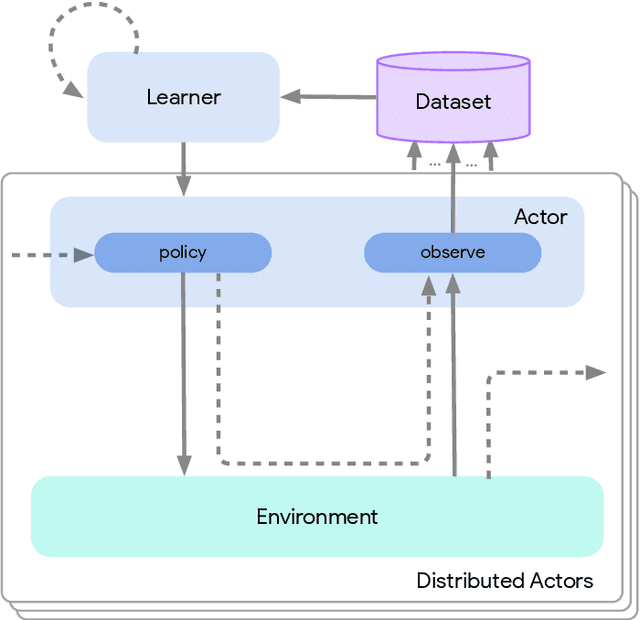
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, we introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines. We also experiment with these agents at different scales of both complexity and computation-including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.
A Distributional View on Multi-Objective Policy Optimization
May 15, 2020
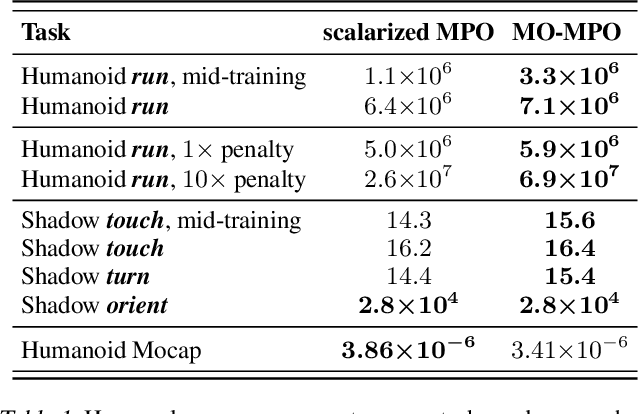
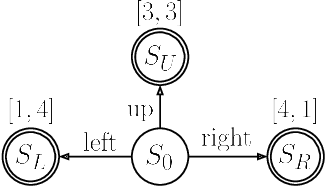
Many real-world problems require trading off multiple competing objectives. However, these objectives are often in different units and/or scales, which can make it challenging for practitioners to express numerical preferences over objectives in their native units. In this paper we propose a novel algorithm for multi-objective reinforcement learning that enables setting desired preferences for objectives in a scale-invariant way. We propose to learn an action distribution for each objective, and we use supervised learning to fit a parametric policy to a combination of these distributions. We demonstrate the effectiveness of our approach on challenging high-dimensional real and simulated robotics tasks, and show that setting different preferences in our framework allows us to trace out the space of nondominated solutions.
Keep Doing What Worked: Behavioral Modelling Priors for Offline Reinforcement Learning
Feb 23, 2020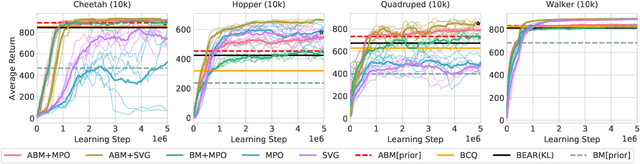

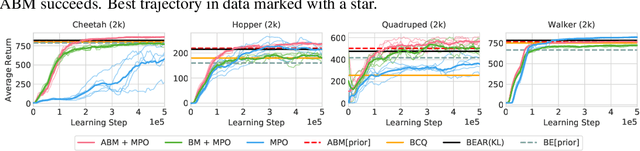
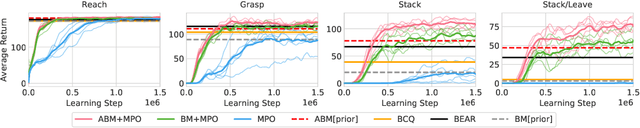
Off-policy reinforcement learning algorithms promise to be applicable in settings where only a fixed data-set (batch) of environment interactions is available and no new experience can be acquired. This property makes these algorithms appealing for real world problems such as robot control. In practice, however, standard off-policy algorithms fail in the batch setting for continuous control. In this paper, we propose a simple solution to this problem. It admits the use of data generated by arbitrary behavior policies and uses a learned prior -- the advantage-weighted behavior model (ABM) -- to bias the RL policy towards actions that have previously been executed and are likely to be successful on the new task. Our method can be seen as an extension of recent work on batch-RL that enables stable learning from conflicting data-sources. We find improvements on competitive baselines in a variety of RL tasks -- including standard continuous control benchmarks and multi-task learning for simulated and real-world robots.
Continuous-Discrete Reinforcement Learning for Hybrid Control in Robotics
Jan 02, 2020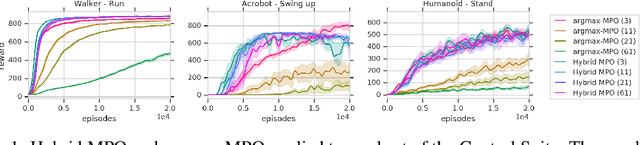



Many real-world control problems involve both discrete decision variables - such as the choice of control modes, gear switching or digital outputs - as well as continuous decision variables - such as velocity setpoints, control gains or analogue outputs. However, when defining the corresponding optimal control or reinforcement learning problem, it is commonly approximated with fully continuous or fully discrete action spaces. These simplifications aim at tailoring the problem to a particular algorithm or solver which may only support one type of action space. Alternatively, expert heuristics are used to remove discrete actions from an otherwise continuous space. In contrast, we propose to treat hybrid problems in their 'native' form by solving them with hybrid reinforcement learning, which optimizes for discrete and continuous actions simultaneously. In our experiments, we first demonstrate that the proposed approach efficiently solves such natively hybrid reinforcement learning problems. We then show, both in simulation and on robotic hardware, the benefits of removing possibly imperfect expert-designed heuristics. Lastly, hybrid reinforcement learning encourages us to rethink problem definitions. We propose reformulating control problems, e.g. by adding meta actions, to improve exploration or reduce mechanical wear and tear.
Quinoa: a Q-function You Infer Normalized Over Actions
Nov 05, 2019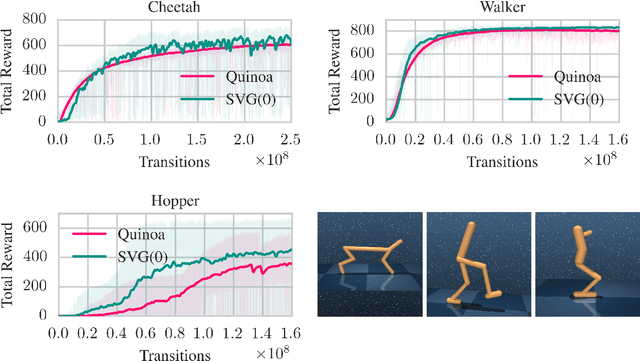
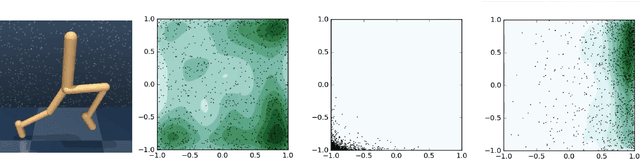
We present an algorithm for learning an approximate action-value soft Q-function in the relative entropy regularised reinforcement learning setting, for which an optimal improved policy can be recovered in closed form. We use recent advances in normalising flows for parametrising the policy together with a learned value-function; and show how this combination can be used to implicitly represent Q-values of an arbitrary policy in continuous action space. Using simple temporal difference learning on the Q-values then leads to a unified objective for policy and value learning. We show how this approach considerably simplifies standard Actor-Critic off-policy algorithms, removing the need for a policy optimisation step. We perform experiments on a range of established reinforcement learning benchmarks, demonstrating that our approach allows for complex, multimodal policy distributions in continuous action spaces, while keeping the process of sampling from the policy both fast and exact.
Modelling Generalized Forces with Reinforcement Learning for Sim-to-Real Transfer
Oct 21, 2019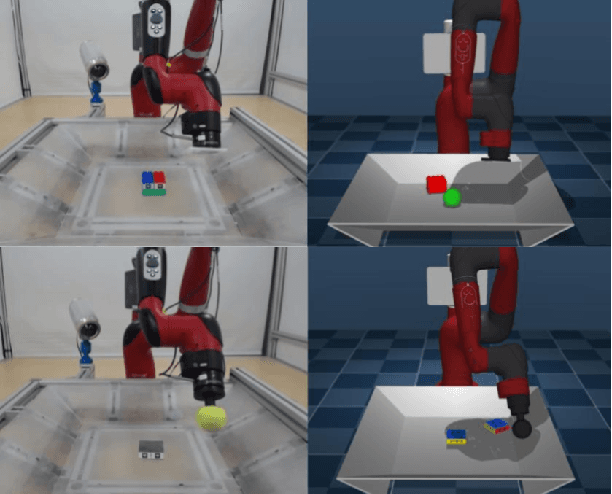
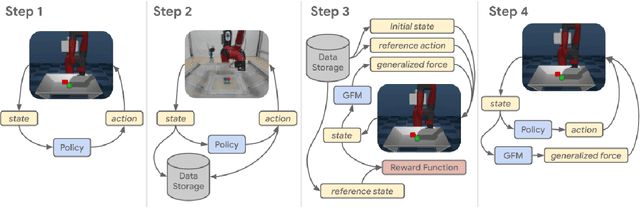
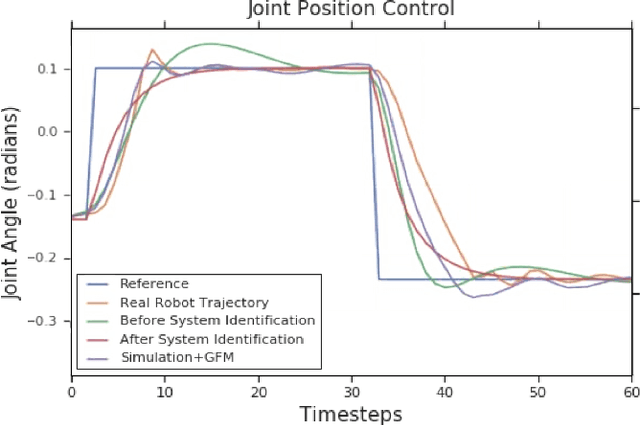

Learning robotic control policies in the real world gives rise to challenges in data efficiency, safety, and controlling the initial condition of the system. On the other hand, simulations are a useful alternative as they provide an abundant source of data without the restrictions of the real world. Unfortunately, simulations often fail to accurately model complex real-world phenomena. Traditional system identification techniques are limited in expressiveness by the analytical model parameters, and usually are not sufficient to capture such phenomena. In this paper we propose a general framework for improving the analytical model by optimizing state dependent generalized forces. State dependent generalized forces are expressive enough to model constraints in the equations of motion, while maintaining a clear physical meaning and intuition. We use reinforcement learning to efficiently optimize the mapping from states to generalized forces over a discounted infinite horizon. We show that using only minutes of real world data improves the sim-to-real control policy transfer. We demonstrate the feasibility of our approach by validating it on a nonprehensile manipulation task on the Sawyer robot.
Imagined Value Gradients: Model-Based Policy Optimization with Transferable Latent Dynamics Models
Oct 09, 2019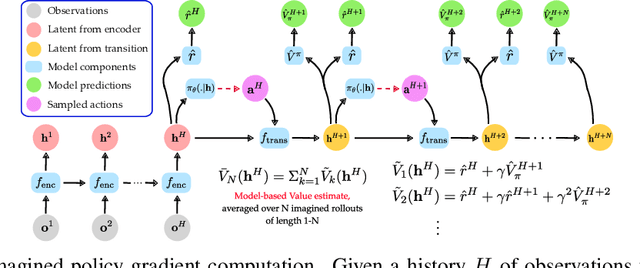



Humans are masters at quickly learning many complex tasks, relying on an approximate understanding of the dynamics of their environments. In much the same way, we would like our learning agents to quickly adapt to new tasks. In this paper, we explore how model-based Reinforcement Learning (RL) can facilitate transfer to new tasks. We develop an algorithm that learns an action-conditional, predictive model of expected future observations, rewards and values from which a policy can be derived by following the gradient of the estimated value along imagined trajectories. We show how robust policy optimization can be achieved in robot manipulation tasks even with approximate models that are learned directly from vision and proprioception. We evaluate the efficacy of our approach in a transfer learning scenario, re-using previously learned models on tasks with different reward structures and visual distractors, and show a significant improvement in learning speed compared to strong off-policy baselines. Videos with results can be found at https://sites.google.com/view/ivg-corl19
Augmenting learning using symmetry in a biologically-inspired domain
Oct 01, 2019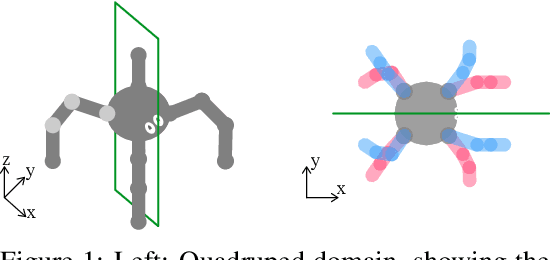
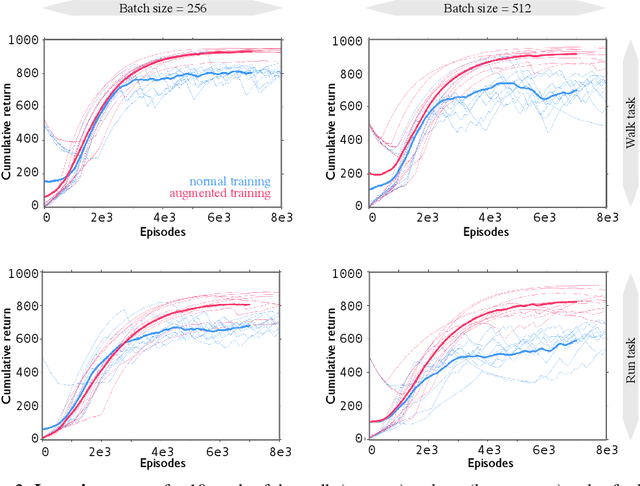
Invariances to translation, rotation and other spatial transformations are a hallmark of the laws of motion, and have widespread use in the natural sciences to reduce the dimensionality of systems of equations. In supervised learning, such as in image classification tasks, rotation, translation and scale invariances are used to augment training datasets. In this work, we use data augmentation in a similar way, exploiting symmetry in the quadruped domain of the DeepMind control suite (Tassa et al. 2018) to add to the trajectories experienced by the actor in the actor-critic algorithm of Abdolmaleki et al. (2018). In a data-limited regime, the agent using a set of experiences augmented through symmetry is able to learn faster. Our approach can be used to inject knowledge of invariances in the domain and task to augment learning in robots, and more generally, to speed up learning in realistic robotics applications.