 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio-visual speech enhancement with a deep Kalman filter generative model
Nov 02, 2022
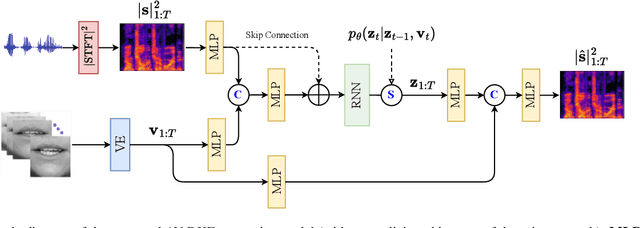
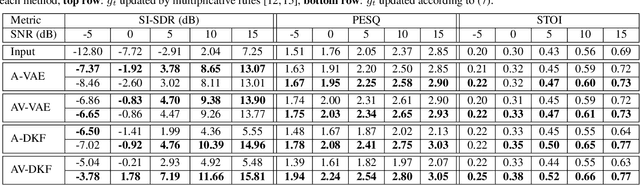
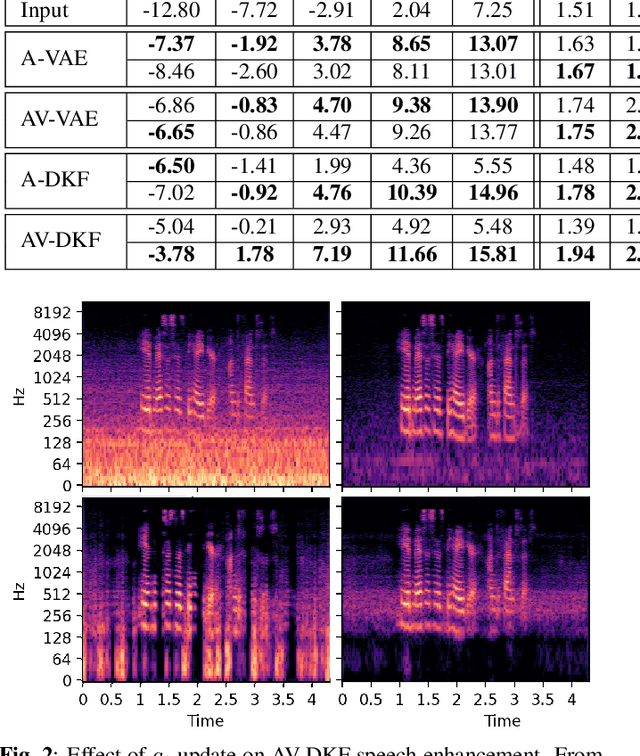
Deep latent variable generative models based on variational autoencoder (VAE) have shown promising performance for audiovisual speech enhancement (AVSE). The underlying idea is to learn a VAEbased audiovisual prior distribution for clean speech data, and then combine it with a statistical noise model to recover a speech signal from a noisy audio recording and video (lip images) of the target speaker. Existing generative models developed for AVSE do not take into account the sequential nature of speech data, which prevents them from fully incorporating the power of visual data. In this paper, we present an audiovisual deep Kalman filter (AV-DKF) generative model which assumes a first-order Markov chain model for the latent variables and effectively fuses audiovisual data. Moreover, we develop an efficient inference methodology to estimate speech signals at test time. We conduct a set of experiments to compare different variants of generative models for speech enhancement. The results demonstrate the superiority of the AV-DKF model compared with both its audio-only version and the non-sequential audio-only and audiovisual VAE-based models.
Analysis of impact of emotions on target speech extraction and speech separation
Aug 15, 2022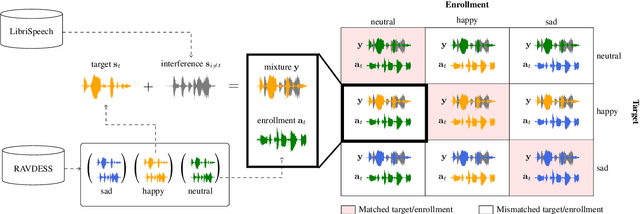
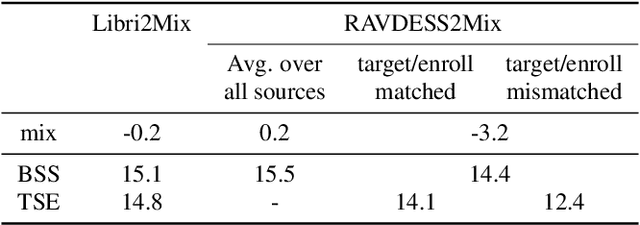
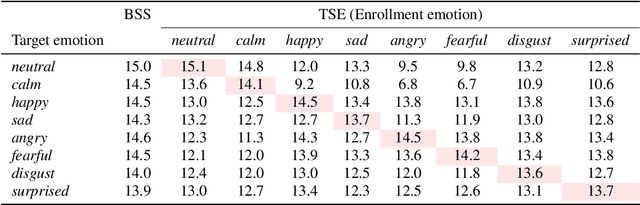
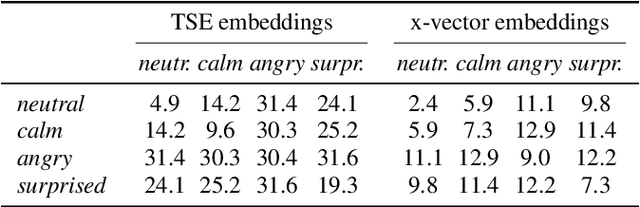
Recently, the performance of blind speech separation (BSS) and target speech extraction (TSE) has greatly progressed. Most works, however, focus on relatively well-controlled conditions using, e.g., read speech. The performance may degrade in more realistic situations. One of the factors causing such degradation may be intrinsic speaker variability, such as emotions, occurring commonly in realistic speech. In this paper, we investigate the influence of emotions on TSE and BSS. We create a new test dataset of emotional mixtures for the evaluation of TSE and BSS. This dataset combines LibriSpeech and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). Through controlled experiments, we can analyze the impact of different emotions on the performance of BSS and TSE. We observe that BSS is relatively robust to emotions, while TSE, which requires identifying and extracting the speech of a target speaker, is much more sensitive to emotions. On comparative speaker verification experiments we show that identifying the target speaker may be particularly challenging when dealing with emotional speech. Using our findings, we outline potential future directions that could improve the robustness of BSS and TSE systems toward emotional speech.
Language-Universal Adapter Learning with Knowledge Distillation for End-to-End Multilingual Speech Recognition
Feb 28, 2023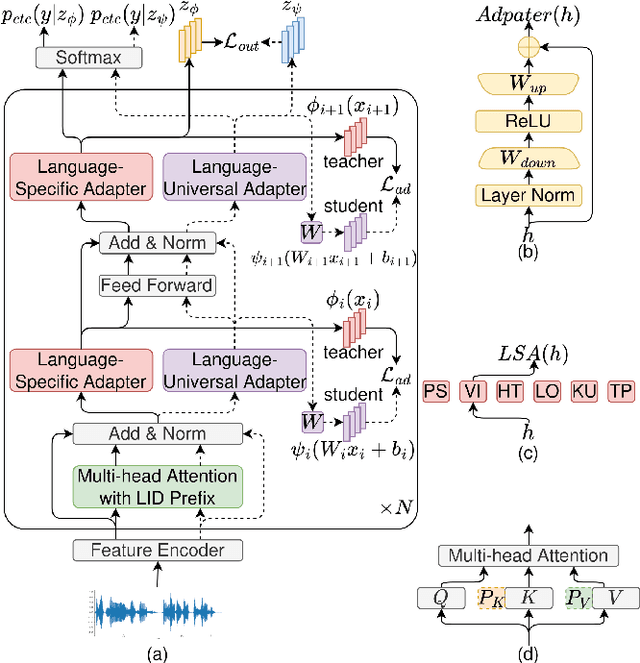
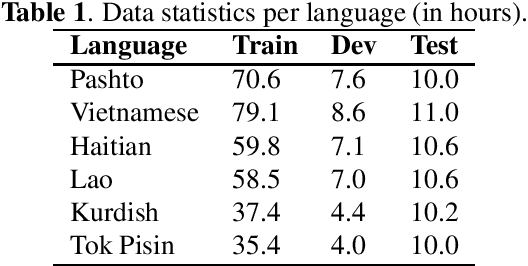
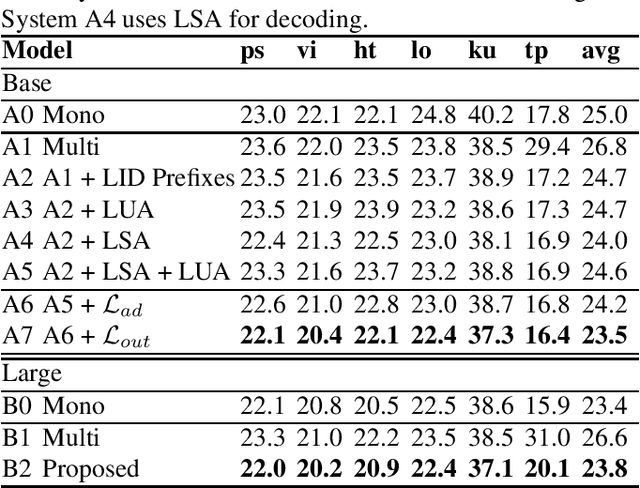

In this paper, we propose a language-universal adapter learning framework based on a pre-trained model for end-to-end multilingual automatic speech recognition (ASR). For acoustic modeling, the wav2vec 2.0 pre-trained model is fine-tuned by inserting language-specific and language-universal adapters. An online knowledge distillation is then used to enable the language-universal adapters to learn both language-specific and universal features. The linguistic information confusion is also reduced by leveraging language identifiers (LIDs). With LIDs we perform a position-wise modification on the multi-head attention outputs. In the inference procedure, the language-specific adapters are removed while the language-universal adapters are kept activated. The proposed method improves the recognition accuracy and addresses the linear increase of the number of adapters' parameters with the number of languages in common multilingual ASR systems. Experiments on the BABEL dataset confirm the effectiveness of the proposed framework. Compared to the conventional multilingual model, a 3.3% absolute error rate reduction is achieved. The code is available at: https://github.com/shen9712/UniversalAdapterLearning.
VATLM: Visual-Audio-Text Pre-Training with Unified Masked Prediction for Speech Representation Learning
Nov 21, 2022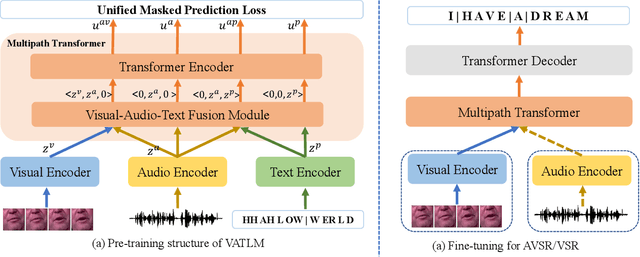
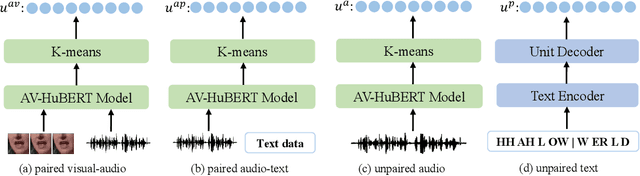
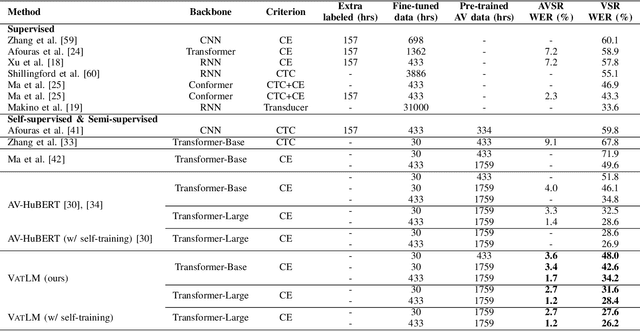
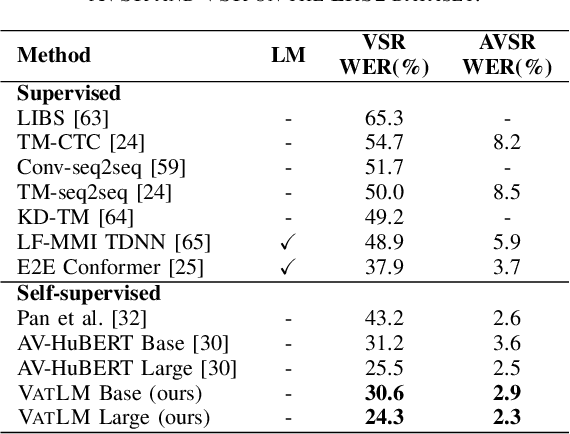
Although speech is a simple and effective way for humans to communicate with the outside world, a more realistic speech interaction contains multimodal information, e.g., vision, text. How to design a unified framework to integrate different modal information and leverage different resources (e.g., visual-audio pairs, audio-text pairs, unlabeled speech, and unlabeled text) to facilitate speech representation learning was not well explored. In this paper, we propose a unified cross-modal representation learning framework VATLM (Visual-Audio-Text Language Model). The proposed VATLM employs a unified backbone network to model the modality-independent information and utilizes three simple modality-dependent modules to preprocess visual, speech, and text inputs. In order to integrate these three modalities into one shared semantic space, VATLM is optimized with a masked prediction task of unified tokens, given by our proposed unified tokenizer. We evaluate the pre-trained VATLM on audio-visual related downstream tasks, including audio-visual speech recognition (AVSR), visual speech recognition (VSR) tasks. Results show that the proposed VATLM outperforms previous the state-of-the-art models, such as audio-visual pre-trained AV-HuBERT model, and analysis also demonstrates that VATLM is capable of aligning different modalities into the same space. To facilitate future research, we release the code and pre-trained models at https://aka.ms/vatlm.
Adversarial Data Augmentation Using VAE-GAN for Disordered Speech Recognition
Nov 03, 2022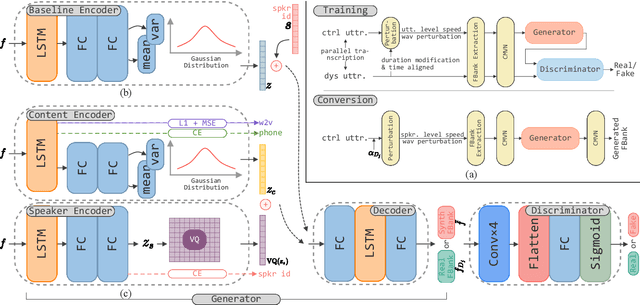
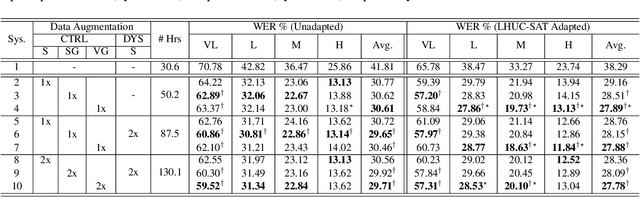
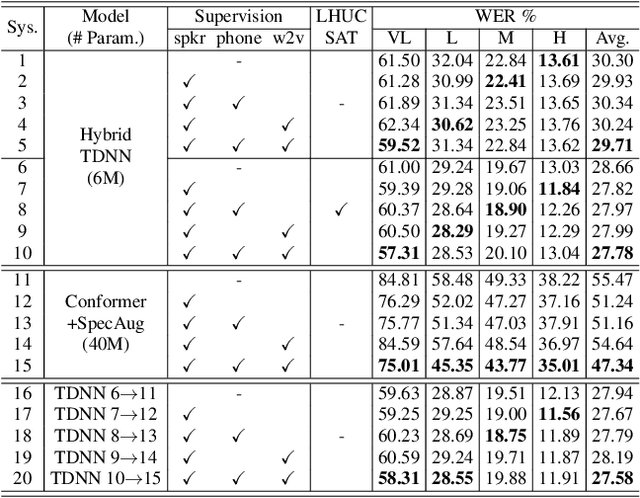

Automatic recognition of disordered speech remains a highly challenging task to date. The underlying neuro-motor conditions, often compounded with co-occurring physical disabilities, lead to the difficulty in collecting large quantities of impaired speech required for ASR system development. This paper presents novel variational auto-encoder generative adversarial network (VAE-GAN) based personalized disordered speech augmentation approaches that simultaneously learn to encode, generate and discriminate synthesized impaired speech. Separate latent features are derived to learn dysarthric speech characteristics and phoneme context representations. Self-supervised pre-trained Wav2vec 2.0 embedding features are also incorporated. Experiments conducted on the UASpeech corpus suggest the proposed adversarial data augmentation approach consistently outperformed the baseline speed perturbation and non-VAE GAN augmentation methods with trained hybrid TDNN and End-to-end Conformer systems. After LHUC speaker adaptation, the best system using VAE-GAN based augmentation produced an overall WER of 27.78% on the UASpeech test set of 16 dysarthric speakers, and the lowest published WER of 57.31% on the subset of speakers with "Very Low" intelligibility.
Leveraging Language Identification to Enhance Code-Mixed Text Classification
Jun 08, 2023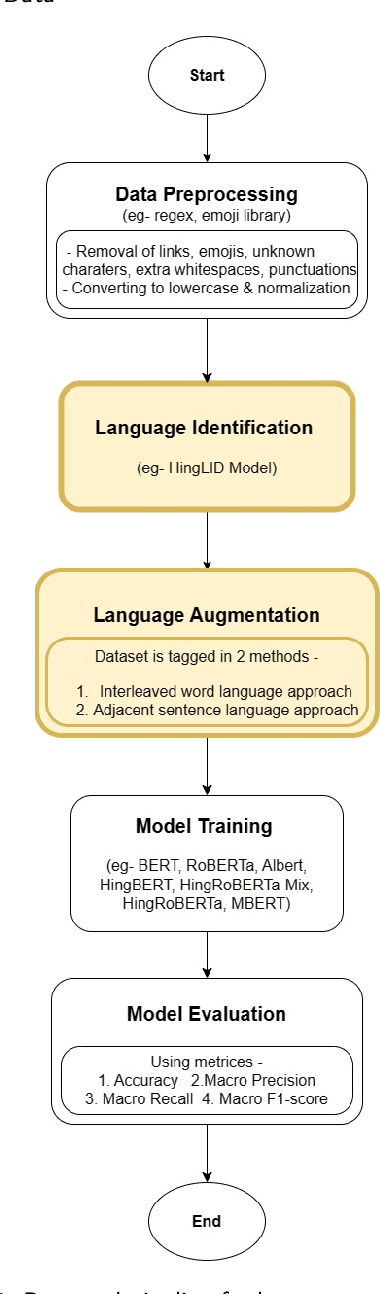
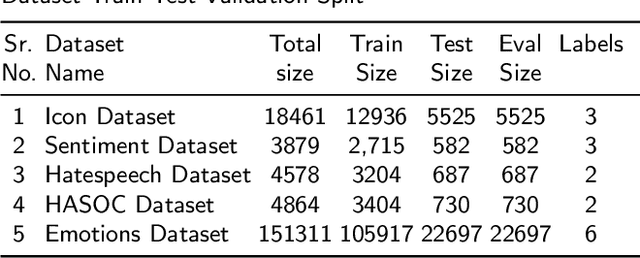
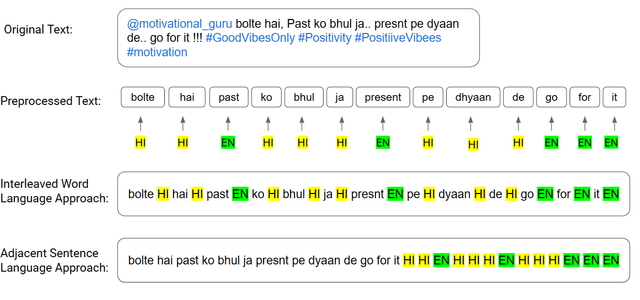
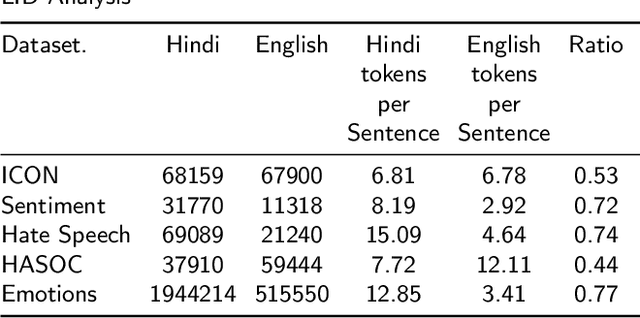
The usage of more than one language in the same text is referred to as Code Mixed. It is evident that there is a growing degree of adaption of the use of code-mixed data, especially English with a regional language, on social media platforms. Existing deep-learning models do not take advantage of the implicit language information in the code-mixed text. Our study aims to improve BERT-based models performance on low-resource Code-Mixed Hindi-English Datasets by experimenting with language augmentation approaches. We propose a pipeline to improve code-mixed systems that comprise data preprocessing, word-level language identification, language augmentation, and model training on downstream tasks like sentiment analysis. For language augmentation in BERT models, we explore word-level interleaving and post-sentence placement of language information. We have examined the performance of vanilla BERT-based models and their code-mixed HingBERT counterparts on respective benchmark datasets, comparing their results with and without using word-level language information. The models were evaluated using metrics such as accuracy, precision, recall, and F1 score. Our findings show that the proposed language augmentation approaches work well across different BERT models. We demonstrate the importance of augmenting code-mixed text with language information on five different code-mixed Hindi-English downstream datasets based on sentiment analysis, hate speech detection, and emotion detection.
Towards Building Voice-based Conversational Recommender Systems: Datasets, Potential Solutions, and Prospects
Jun 14, 2023
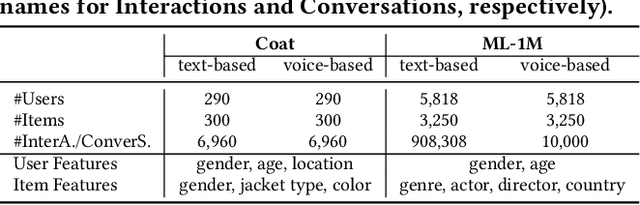
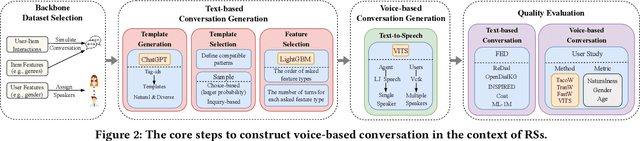
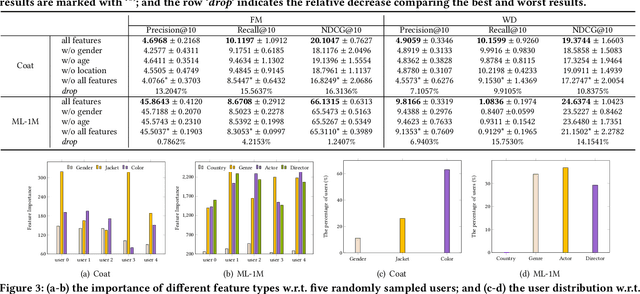
Conversational recommender systems (CRSs) have become crucial emerging research topics in the field of RSs, thanks to their natural advantages of explicitly acquiring user preferences via interactive conversations and revealing the reasons behind recommendations. However, the majority of current CRSs are text-based, which is less user-friendly and may pose challenges for certain users, such as those with visual impairments or limited writing and reading abilities. Therefore, for the first time, this paper investigates the potential of voice-based CRS (VCRSs) to revolutionize the way users interact with RSs in a natural, intuitive, convenient, and accessible fashion. To support such studies, we create two VCRSs benchmark datasets in the e-commerce and movie domains, after realizing the lack of such datasets through an exhaustive literature review. Specifically, we first empirically verify the benefits and necessity of creating such datasets. Thereafter, we convert the user-item interactions to text-based conversations through the ChatGPT-driven prompts for generating diverse and natural templates, and then synthesize the corresponding audios via the text-to-speech model. Meanwhile, a number of strategies are delicately designed to ensure the naturalness and high quality of voice conversations. On this basis, we further explore the potential solutions and point out possible directions to build end-to-end VCRSs by seamlessly extracting and integrating voice-based inputs, thus delivering performance-enhanced, self-explainable, and user-friendly VCRSs. Our study aims to establish the foundation and motivate further pioneering research in the emerging field of VCRSs. This aligns with the principles of explainable AI and AI for social good, viz., utilizing technology's potential to create a fair, sustainable, and just world.
Streaming Joint Speech Recognition and Disfluency Detection
Nov 16, 2022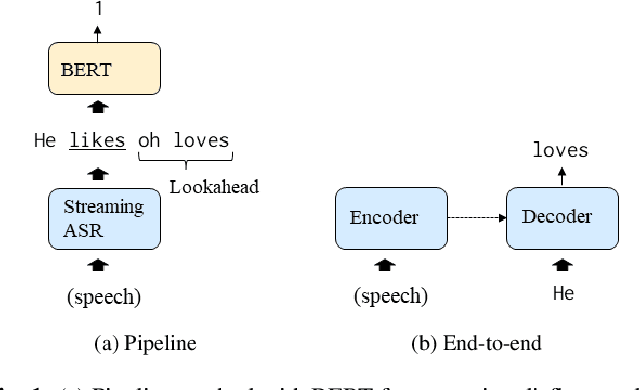

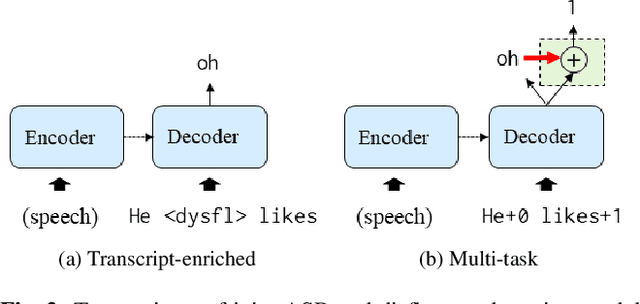

Disfluency detection has mainly been solved in a pipeline approach, as post-processing of speech recognition. In this study, we propose Transformer-based encoder-decoder models that jointly solve speech recognition and disfluency detection, which work in a streaming manner. Compared to pipeline approaches, the joint models can leverage acoustic information that makes disfluency detection robust to recognition errors and provide non-verbal clues. Moreover, joint modeling results in low-latency and lightweight inference. We investigate two joint model variants for streaming disfluency detection: a transcript-enriched model and a multi-task model. The transcript-enriched model is trained on text with special tags indicating the starting and ending points of the disfluent part. However, it has problems with latency and standard language model adaptation, which arise from the additional disfluency tags. We propose a multi-task model to solve such problems, which has two output layers at the Transformer decoder; one for speech recognition and the other for disfluency detection. It is modeled to be conditioned on the currently recognized token with an additional token-dependency mechanism. We show that the proposed joint models outperformed a BERT-based pipeline approach in both accuracy and latency, on both the Switchboard and the corpus of spontaneous Japanese.
Embedding a Differentiable Mel-cepstral Synthesis Filter to a Neural Speech Synthesis System
Nov 21, 2022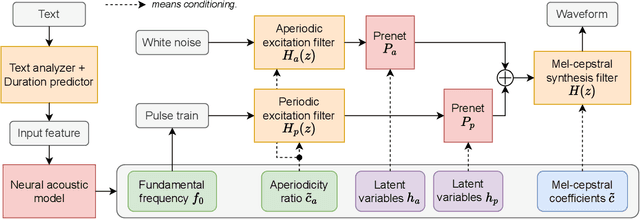
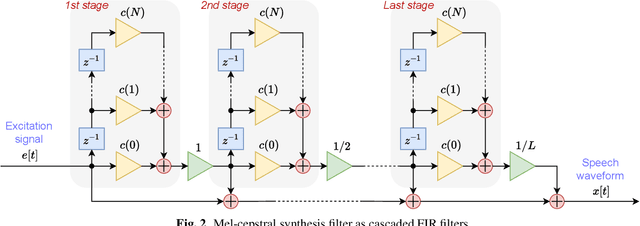
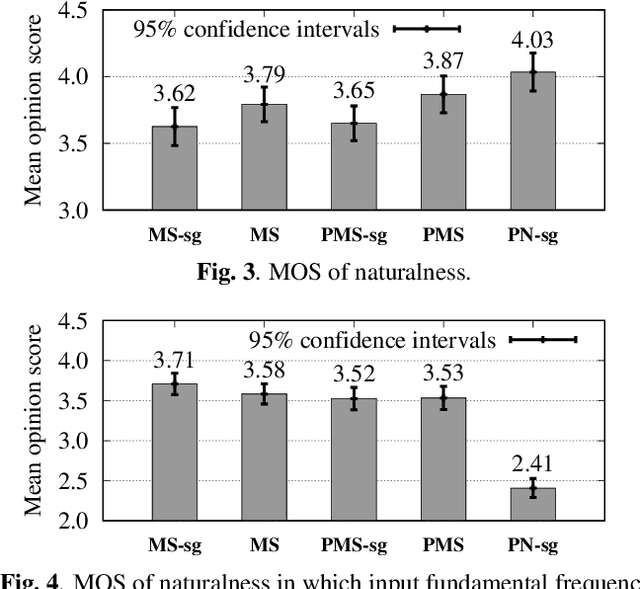
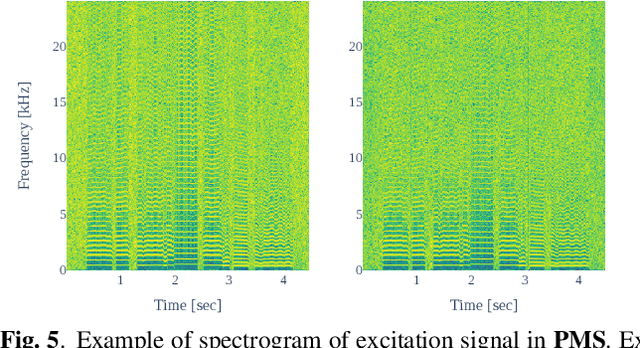
This paper integrates a classic mel-cepstral synthesis filter into a modern neural speech synthesis system towards end-to-end controllable speech synthesis. Since the mel-cepstral synthesis filter is explicitly embedded in neural waveform models in the proposed system, both voice characteristics and the pitch of synthesized speech are highly controlled via a frequency warping parameter and fundamental frequency, respectively. We implement the mel-cepstral synthesis filter as a differentiable and GPU-friendly module to enable the acoustic and waveform models in the proposed system to be simultaneously optimized in an end-to-end manner. Experiments show that the proposed system improves speech quality from a baseline system maintaining controllability. The core PyTorch modules used in the experiments will be publicly available on GitHub.
Self-supervised Predictive Coding Models Encode Speaker and Phonetic Information in Orthogonal Subspaces
May 21, 2023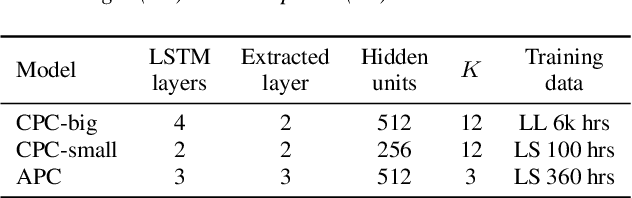
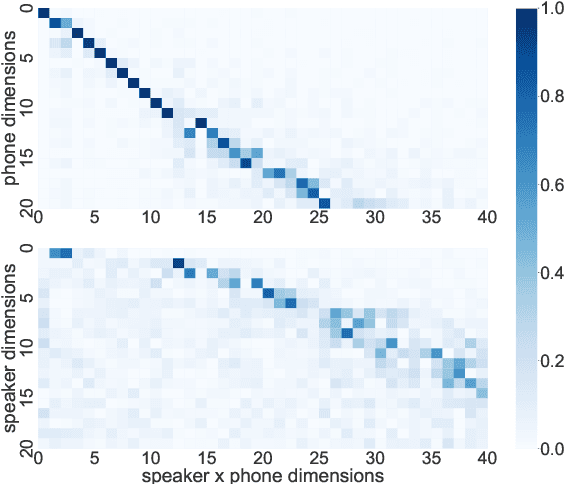
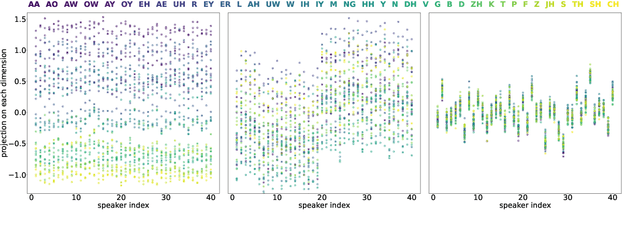
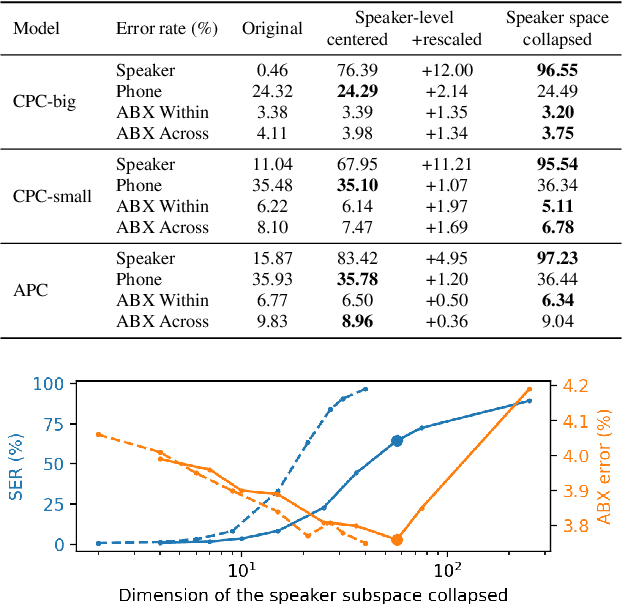
Self-supervised speech representations are known to encode both speaker and phonetic information, but how they are distributed in the high-dimensional space remains largely unexplored. We hypothesize that they are encoded in orthogonal subspaces, a property that lends itself to simple disentanglement. Applying principal component analysis to representations of two predictive coding models, we identify two subspaces that capture speaker and phonetic variances, and confirm that they are nearly orthogonal. Based on this property, we propose a new speaker normalization method which collapses the subspace that encodes speaker information, without requiring transcriptions. Probing experiments show that our method effectively eliminates speaker information and outperforms a previous baseline in phone discrimination tasks. Moreover, the approach generalizes and can be used to remove information of unseen speakers.