 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding a Differentiable Mel-cepstral Synthesis Filter to a Neural Speech Synthesis System
Nov 21, 2022



This paper integrates a classic mel-cepstral synthesis filter into a modern neural speech synthesis system towards end-to-end controllable speech synthesis. Since the mel-cepstral synthesis filter is explicitly embedded in neural waveform models in the proposed system, both voice characteristics and the pitch of synthesized speech are highly controlled via a frequency warping parameter and fundamental frequency, respectively. We implement the mel-cepstral synthesis filter as a differentiable and GPU-friendly module to enable the acoustic and waveform models in the proposed system to be simultaneously optimized in an end-to-end manner. Experiments show that the proposed system improves speech quality from a baseline system maintaining controllability. The core PyTorch modules used in the experiments will be publicly available on GitHub.
Neural Sequence-to-Sequence Speech Synthesis Using a Hidden Semi-Markov Model Based Structured Attention Mechanism
Aug 31, 2021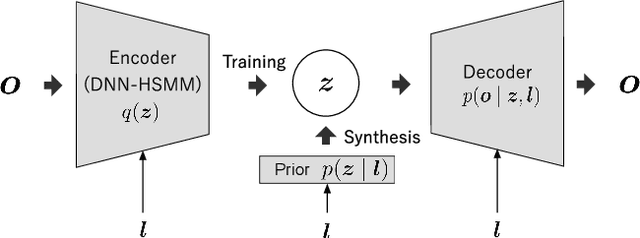
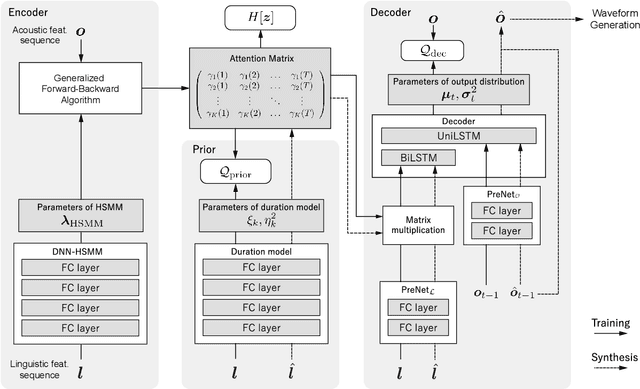
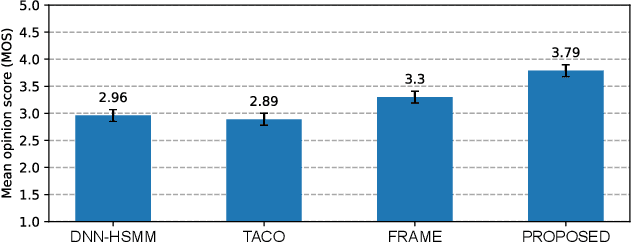
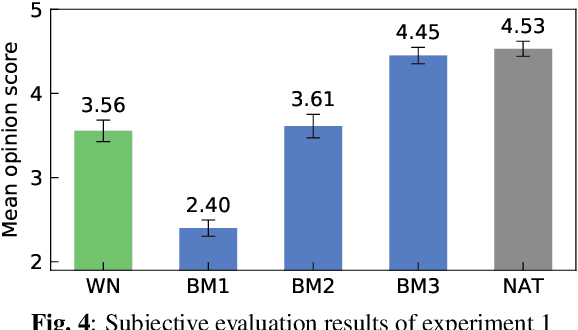
This paper proposes a novel Sequence-to-Sequence (Seq2Seq) model integrating the structure of Hidden Semi-Markov Models (HSMMs) into its attention mechanism. In speech synthesis, it has been shown that methods based on Seq2Seq models using deep neural networks can synthesize high quality speech under the appropriate conditions. However, several essential problems still have remained, i.e., requiring large amounts of training data due to an excessive degree for freedom in alignment (mapping function between two sequences), and the difficulty in handling duration due to the lack of explicit duration modeling. The proposed method defines a generative models to realize the simultaneous optimization of alignments and model parameters based on the Variational Auto-Encoder (VAE) framework, and provides monotonic alignments and explicit duration modeling based on the structure of HSMM. The proposed method can be regarded as an integration of Hidden Markov Model (HMM) based speech synthesis and deep learning based speech synthesis using Seq2Seq models, incorporating both the benefits. Subjective evaluation experiments showed that the proposed method obtained higher mean opinion scores than Tacotron 2 on relatively small amount of training data.
PeriodNet: A non-autoregressive waveform generation model with a structure separating periodic and aperiodic components
Feb 15, 2021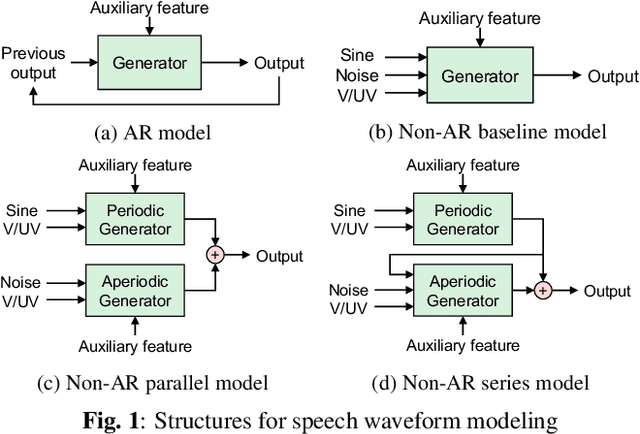
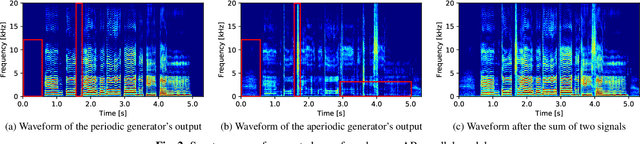
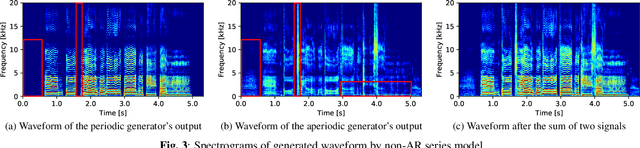
We propose PeriodNet, a non-autoregressive (non-AR) waveform generation model with a new model structure for modeling periodic and aperiodic components in speech waveforms. The non-AR waveform generation models can generate speech waveforms parallelly and can be used as a speech vocoder by conditioning an acoustic feature. Since a speech waveform contains periodic and aperiodic components, both components should be appropriately modeled to generate a high-quality speech waveform. However, it is difficult to decompose the components from a natural speech waveform in advance. To address this issue, we propose a parallel model and a series model structure separating periodic and aperiodic components. The features of our proposed models are that explicit periodic and aperiodic signals are taken as input, and external periodic/aperiodic decomposition is not needed in training. Experiments using a singing voice corpus show that our proposed structure improves the naturalness of the generated waveform. We also show that the speech waveforms with a pitch outside of the training data range can be generated with more naturalness.
Fast and High-Quality Singing Voice Synthesis System based on Convolutional Neural Networks
Oct 24, 2019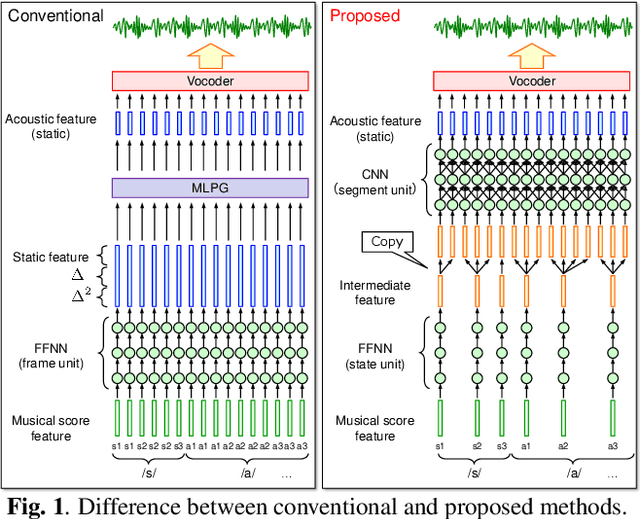
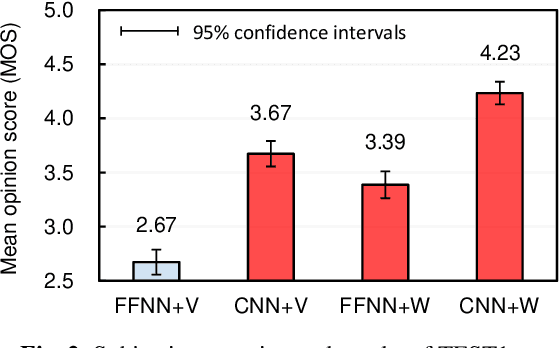
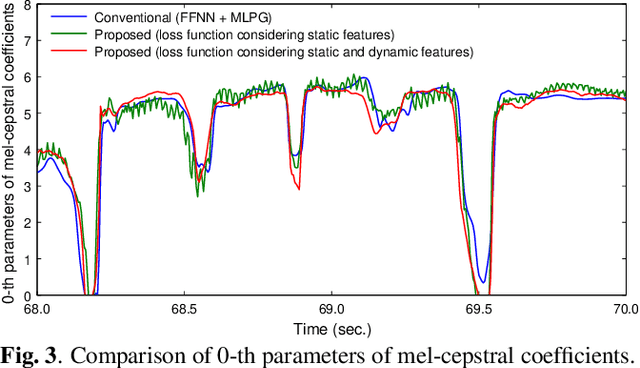
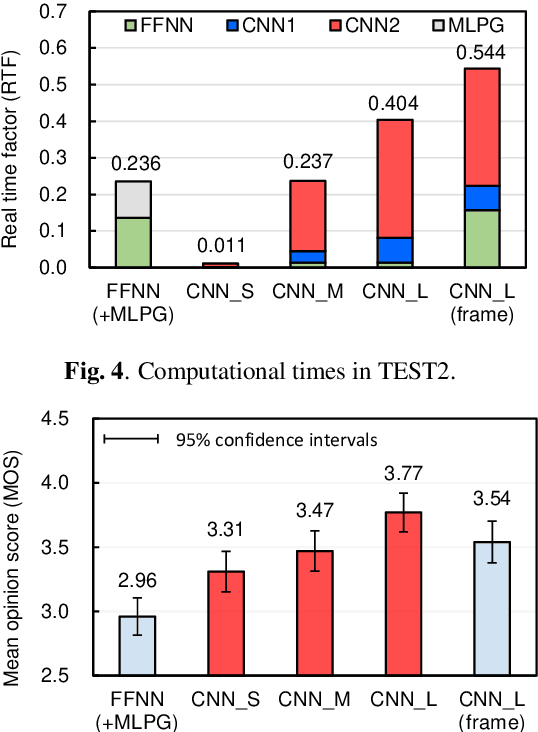
The present paper describes singing voice synthesis based on convolutional neural networks (CNNs). Singing voice synthesis systems based on deep neural networks (DNNs) are currently being proposed and are improving the naturalness of synthesized singing voices. As singing voices represent a rich form of expression, a powerful technique to model them accurately is required. In the proposed technique, long-term dependencies of singing voices are modeled by CNNs. An acoustic feature sequence is generated for each segment that consists of long-term frames, and a natural trajectory is obtained without the parameter generation algorithm. Furthermore, a computational complexity reduction technique, which drives the DNNs in different time units depending on type of musical score features, is proposed. Experimental results show that the proposed method can synthesize natural sounding singing voices much faster than the conventional method.
Neural source-filter waveform models for statistical parametric speech synthesis
Apr 27, 2019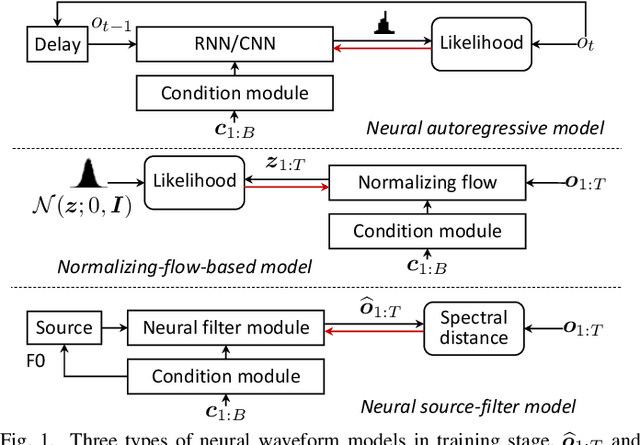
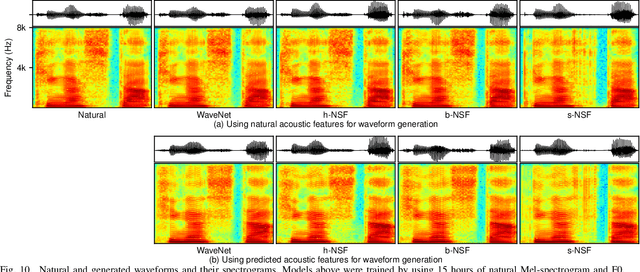
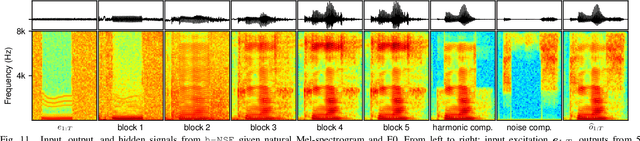
Neural waveform models such as WaveNet have demonstrated better performance than conventional vocoders for statistical parametric speech synthesis. As an autoregressive (AR) model, WaveNet is limited by a slow sequential waveform generation process. Some new models that use the inverse-autoregressive flow (IAF) can generate a whole waveform in a one-shot manner. However, these IAF-based models require sequential transformation during training, which severely slows down the training speed. Other models such as Parallel WaveNet and ClariNet bring together the benefits of AR and IAF-based models and train an IAF model by transferring the knowledge from a pre-trained AR teacher to an IAF student without any sequential transformation. However, both models require additional training criteria, and their implementation is prohibitively complicated. We propose a framework for neural source-filter (NSF) waveform modeling without AR nor IAF-based approaches. This framework requires only three components for waveform generation: a source module that generates a sine-based signal as excitation, a non-AR dilated-convolution-based filter module that transforms the excitation into a waveform, and a conditional module that pre-processes the acoustic features for the source and filer modules. This framework minimizes spectral-amplitude distances for model training, which can be efficiently implemented by using short-time Fourier transform routines. Under this framework, we designed three NSF models and compared them with WaveNet. It was demonstrated that the NSF models generated waveforms at least 100 times faster than WaveNet, and the quality of the synthetic speech from the best NSF model was better than or equally good as that from WaveNet.
Training a Neural Speech Waveform Model using Spectral Losses of Short-Time Fourier Transform and Continuous Wavelet Transform
Apr 07, 2019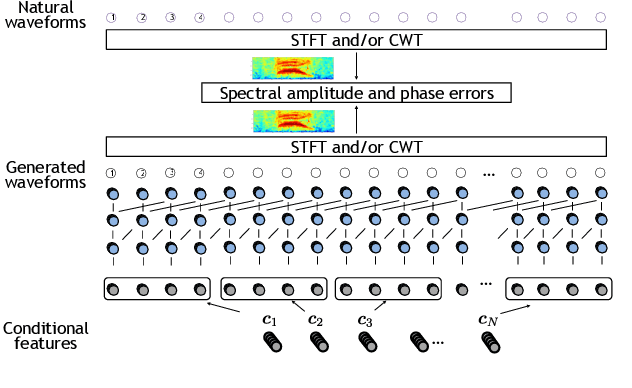

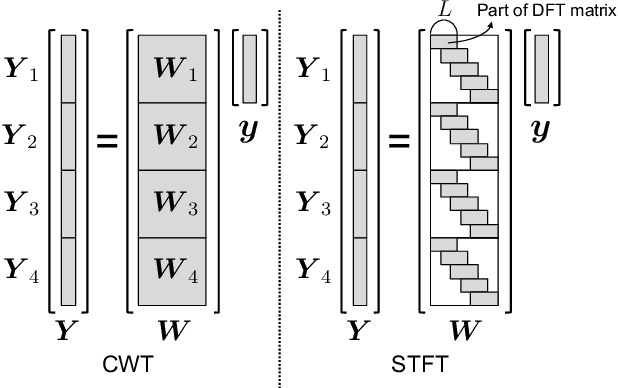
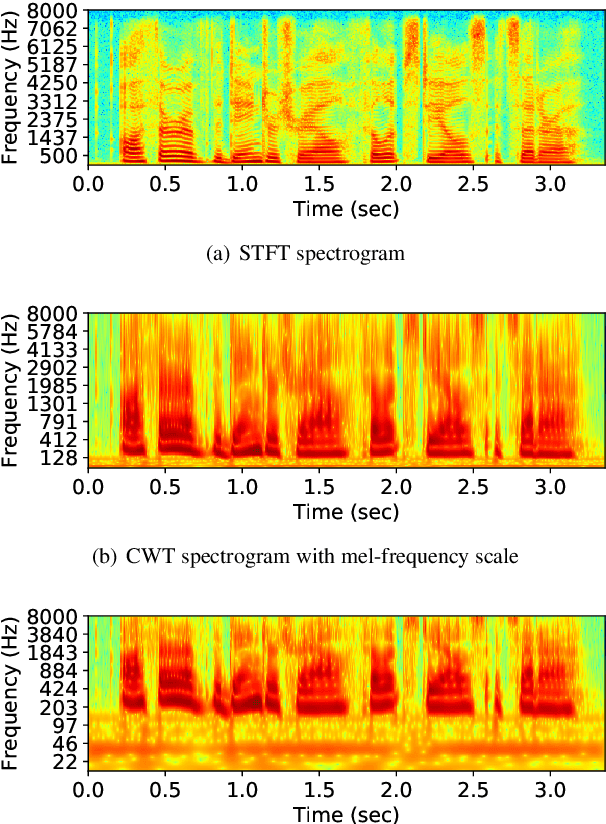
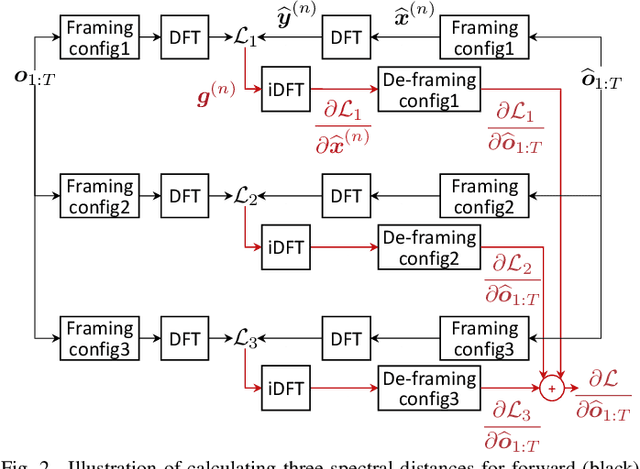
Recently, we proposed short-time Fourier transform (STFT)-based loss functions for training a neural speech waveform model. In this paper, we generalize the above framework and propose a training scheme for such models based on spectral amplitude and phase losses obtained by either STFT or continuous wavelet transform (CWT), or both of them. Since CWT is capable of having time and frequency resolutions different from those of STFT and is cable of considering those closer to human auditory scales, the proposed loss functions could provide complementary information on speech signals. Experimental results showed that it is possible to train a high-quality model by using the proposed CWT spectral loss and is as good as one using STFT-based loss.
Neural source-filter-based waveform model for statistical parametric speech synthesis
Oct 31, 2018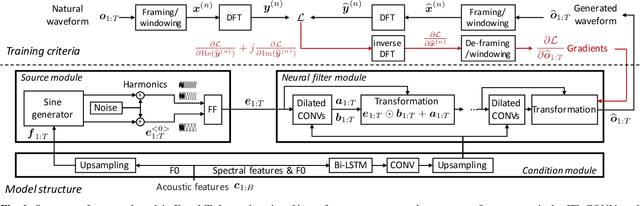

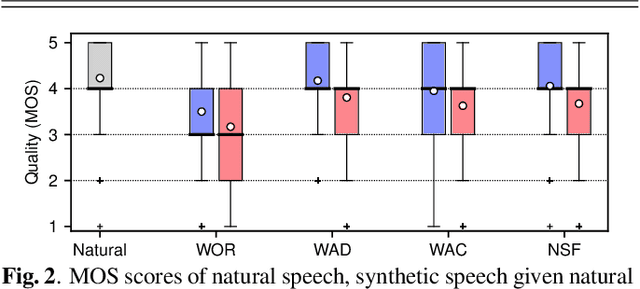

Neural waveform models such as the WaveNet are used in many recent text-to-speech systems, but the original WaveNet is quite slow in waveform generation because of its autoregressive (AR) structure. Although faster non-AR models were recently reported, they may be prohibitively complicated due to the use of a distilling training method and the blend of other disparate training criteria. This study proposes a non-AR neural source-filter waveform model that can be directly trained using spectrum-based training criteria and the stochastic gradient descent method. Given the input acoustic features, the proposed model first uses a source module to generate a sine-based excitation signal and then uses a filter module to transform the excitation signal into the output speech waveform. Our experiments demonstrated that the proposed model generated waveforms at least 100 times faster than the AR WaveNet and the quality of its synthetic speech is close to that of speech generated by the AR WaveNet. Ablation test results showed that both the sine-wave excitation signal and the spectrum-based training criteria were essential to the performance of the proposed model.
STFT spectral loss for training a neural speech waveform model
Oct 30, 2018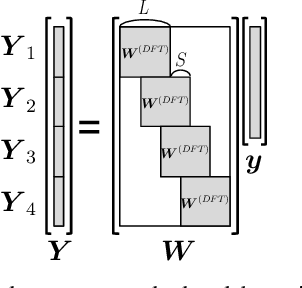
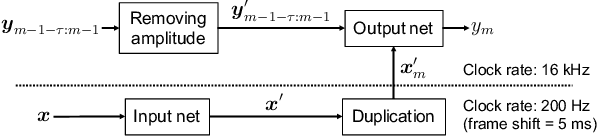
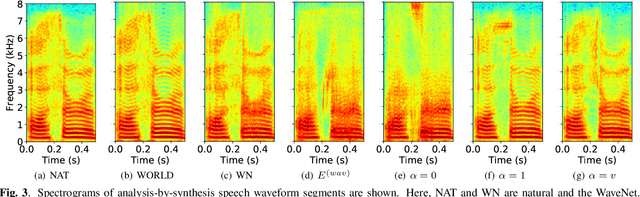
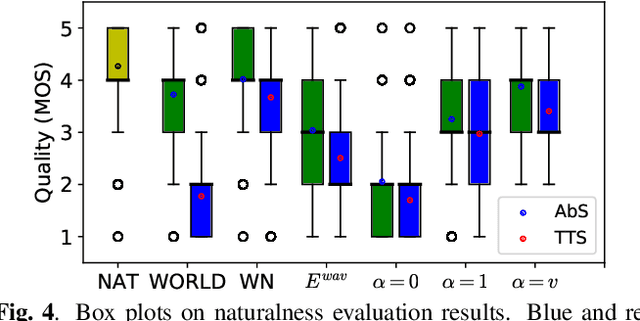
This paper proposes a new loss using short-time Fourier transform (STFT) spectra for the aim of training a high-performance neural speech waveform model that predicts raw continuous speech waveform samples directly. Not only amplitude spectra but also phase spectra obtained from generated speech waveforms are used to calculate the proposed loss. We also mathematically show that training of the waveform model on the basis of the proposed loss can be interpreted as maximum likelihood training that assumes the amplitude and phase spectra of generated speech waveforms following Gaussian and von Mises distributions, respectively. Furthermore, this paper presents a simple network architecture as the speech waveform model, which is composed of uni-directional long short-term memories (LSTMs) and an auto-regressive structure. Experimental results showed that the proposed neural model synthesized high-quality speech waveforms.
Investigation of enhanced Tacotron text-to-speech synthesis systems with self-attention for pitch accent language
Oct 29, 2018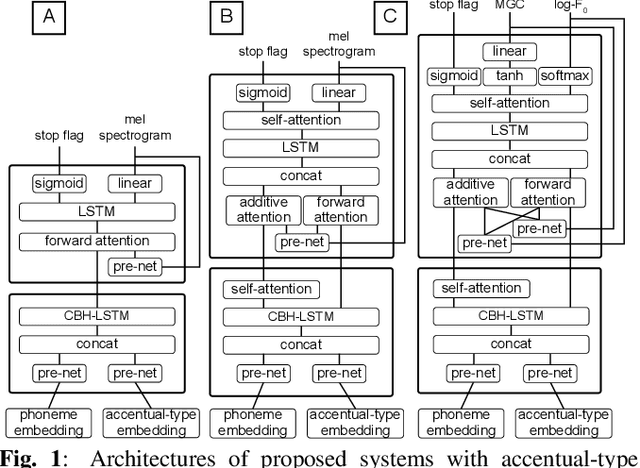
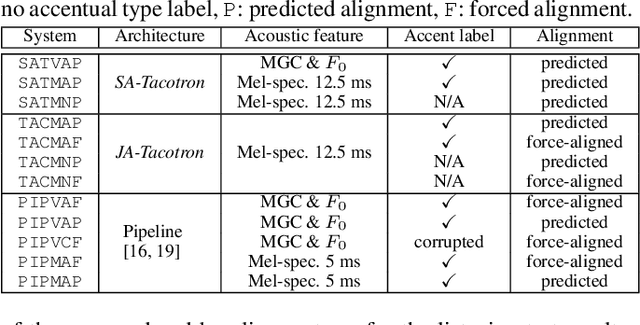
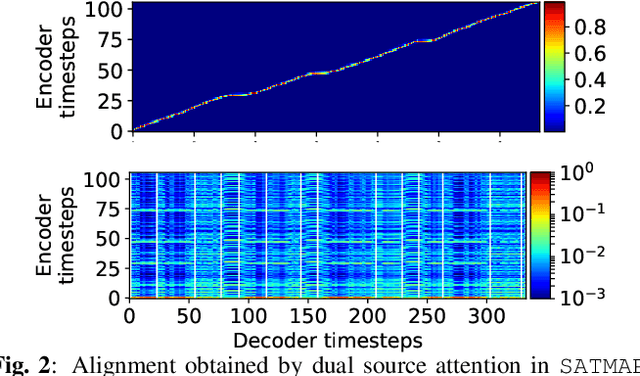
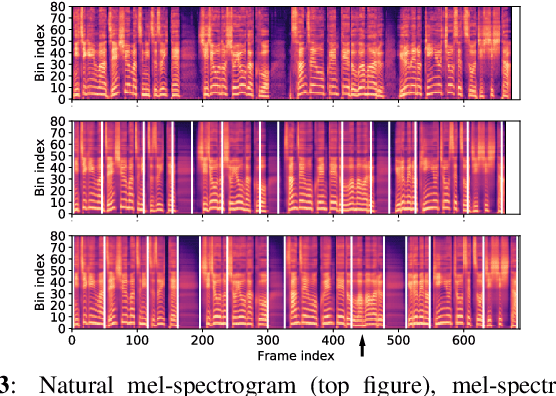
End-to-end speech synthesis is a promising approach that directly converts raw text to speech. Although it was shown that Tacotron2 outperforms classical pipeline systems with regards to naturalness in English, its applicability to other languages is still unknown. Japanese could be one of the most difficult languages for which to achieve end-to-end speech synthesis, largely due to its character diversity and pitch accents. Therefore, state-of-the-art systems are still based on a traditional pipeline framework that requires a separate text analyzer and duration model. Towards end-to-end Japanese speech synthesis, we extend Tacotron to systems with self-attention to capture long-term dependencies related to pitch accents and compare their audio quality with classical pipeline systems under various conditions to show their pros and cons. In a large-scale listening test, we investigated the impacts of the presence of accentual-type labels, the use of force or predicted alignments, and acoustic features used as local condition parameters of the Wavenet vocoder. Our results reveal that although the proposed systems still do not match the quality of a top-line pipeline system for Japanese, we show important stepping stones towards end-to-end Japanese speech synthesis.
Wasserstein GAN and Waveform Loss-based Acoustic Model Training for Multi-speaker Text-to-Speech Synthesis Systems Using a WaveNet Vocoder
Jul 31, 2018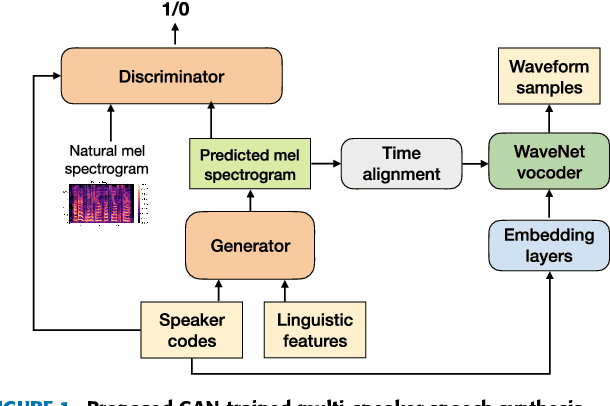
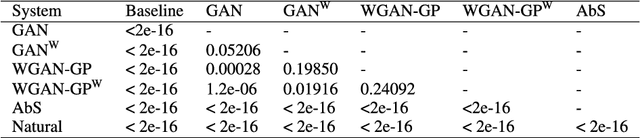
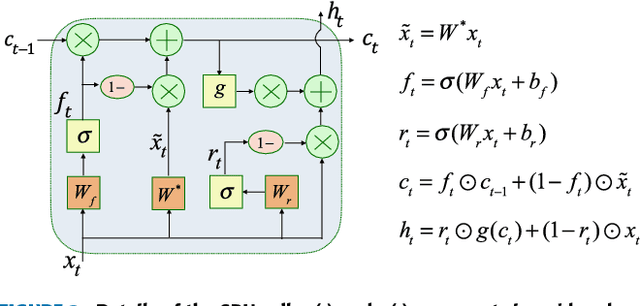
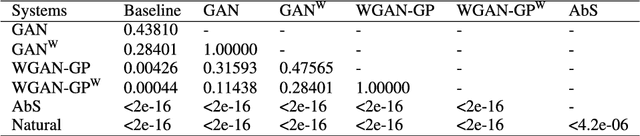
Recent neural networks such as WaveNet and sampleRNN that learn directly from speech waveform samples have achieved very high-quality synthetic speech in terms of both naturalness and speaker similarity even in multi-speaker text-to-speech synthesis systems. Such neural networks are being used as an alternative to vocoders and hence they are often called neural vocoders. The neural vocoder uses acoustic features as local condition parameters, and these parameters need to be accurately predicted by another acoustic model. However, it is not yet clear how to train this acoustic model, which is problematic because the final quality of synthetic speech is significantly affected by the performance of the acoustic model. Significant degradation happens, especially when predicted acoustic features have mismatched characteristics compared to natural ones. In order to reduce the mismatched characteristics between natural and generated acoustic features, we propose frameworks that incorporate either a conditional generative adversarial network (GAN) or its variant, Wasserstein GAN with gradient penalty (WGAN-GP), into multi-speaker speech synthesis that uses the WaveNet vocoder. We also extend the GAN frameworks and use the discretized mixture logistic loss of a well-trained WaveNet in addition to mean squared error and adversarial losses as parts of objective functions. Experimental results show that acoustic models trained using the WGAN-GP framework using back-propagated discretized-mixture-of-logistics (DML) loss achieves the highest subjective evaluation scores in terms of both quality and speaker similarity.