 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need a Transition Plane: Bridging Continuous Panoramic 3D Reconstruction with Perspective Gaussian Splatting
Apr 12, 2025Recently, reconstructing scenes from a single panoramic image using advanced 3D Gaussian Splatting (3DGS) techniques has attracted growing interest. Panoramic images offer a 360$\times$ 180 field of view (FoV), capturing the entire scene in a single shot. However, panoramic images introduce severe distortion, making it challenging to render 3D Gaussians into 2D distorted equirectangular space directly. Converting equirectangular images to cubemap projections partially alleviates this problem but introduces new challenges, such as projection distortion and discontinuities across cube-face boundaries. To address these limitations, we present a novel framework, named TPGS, to bridge continuous panoramic 3D scene reconstruction with perspective Gaussian splatting. Firstly, we introduce a Transition Plane between adjacent cube faces to enable smoother transitions in splatting directions and mitigate optimization ambiguity in the boundary region. Moreover, an intra-to-inter face optimization strategy is proposed to enhance local details and restore visual consistency across cube-face boundaries. Specifically, we optimize 3D Gaussians within individual cube faces and then fine-tune them in the stitched panoramic space. Additionally, we introduce a spherical sampling technique to eliminate visible stitching seams. Extensive experiments on indoor and outdoor, egocentric, and roaming benchmark datasets demonstrate that our approach outperforms existing state-of-the-art methods. Code and models will be available at https://github.com/zhijieshen-bjtu/TPGS.
Semi-Supervised 360 Layout Estimation with Panoramic Collaborative Perturbations
Mar 03, 2025The performance of existing supervised layout estimation methods heavily relies on the quality of data annotations. However, obtaining large-scale and high-quality datasets remains a laborious and time-consuming challenge. To solve this problem, semi-supervised approaches are introduced to relieve the demand for expensive data annotations by encouraging the consistent results of unlabeled data with different perturbations. However, existing solutions merely employ vanilla perturbations, ignoring the characteristics of panoramic layout estimation. In contrast, we propose a novel semi-supervised method named SemiLayout360, which incorporates the priors of the panoramic layout and distortion through collaborative perturbations. Specifically, we leverage the panoramic layout prior to enhance the model's focus on potential layout boundaries. Meanwhile, we introduce the panoramic distortion prior to strengthen distortion awareness. Furthermore, to prevent intense perturbations from hindering model convergence and ensure the effectiveness of prior-based perturbations, we divide and reorganize them as panoramic collaborative perturbations. Our experimental results on three mainstream benchmarks demonstrate that the proposed method offers significant advantages over existing state-of-the-art (SoTA) solutions.
Revisiting Monocular 3D Object Detection from Scene-Level Depth Retargeting to Instance-Level Spatial Refinement
Dec 26, 2024



Monocular 3D object detection is challenging due to the lack of accurate depth. However, existing depth-assisted solutions still exhibit inferior performance, whose reason is universally acknowledged as the unsatisfactory accuracy of monocular depth estimation models. In this paper, we revisit monocular 3D object detection from the depth perspective and formulate an additional issue as the limited 3D structure-aware capability of existing depth representations (\textit{e.g.}, depth one-hot encoding or depth distribution). To address this issue, we propose a novel depth-adapted monocular 3D object detection network, termed \textbf{RD3D}, that mainly comprises a Scene-Level Depth Retargeting (SDR) module and an Instance-Level Spatial Refinement (ISR) module. The former incorporates the scene-level perception of 3D structures, retargeting traditional depth representations to a new formulation: \textbf{Depth Thickness Field}. The latter refines the voxel spatial representation with the guidance of instances, eliminating the ambiguity of 3D occupation and thus improving detection accuracy. Extensive experiments on the KITTI and Waymo datasets demonstrate our superiority to existing state-of-the-art (SoTA) methods and the universality when equipped with different depth estimation models. The code will be available.
Revisiting 360 Depth Estimation with PanoGabor: A New Fusion Perspective
Aug 30, 2024



Depth estimation from a monocular 360 image is important to the perception of the entire 3D environment. However, the inherent distortion and large field of view (FoV) in 360 images pose great challenges for this task. To this end, existing mainstream solutions typically introduce additional perspective-based 360 representations (\textit{e.g.}, Cubemap) to achieve effective feature extraction. Nevertheless, regardless of the introduced representations, they eventually need to be unified into the equirectangular projection (ERP) format for the subsequent depth estimation, which inevitably reintroduces the troublesome distortions. In this work, we propose an oriented distortion-aware Gabor Fusion framework (PGFuse) to address the above challenges. First, we introduce Gabor filters that analyze texture in the frequency domain, thereby extending the receptive fields and enhancing depth cues. To address the reintroduced distortions, we design a linear latitude-aware distortion representation method to generate customized, distortion-aware Gabor filters (PanoGabor filters). Furthermore, we design a channel-wise and spatial-wise unidirectional fusion module (CS-UFM) that integrates the proposed PanoGabor filters to unify other representations into the ERP format, delivering effective and distortion-free features. Considering the orientation sensitivity of the Gabor transform, we introduce a spherical gradient constraint to stabilize this sensitivity. Experimental results on three popular indoor 360 benchmarks demonstrate the superiority of the proposed PGFuse to existing state-of-the-art solutions. Code can be available upon acceptance.
SGFormer: Spherical Geometry Transformer for 360 Depth Estimation
Apr 23, 2024



Panoramic distortion poses a significant challenge in 360 depth estimation, particularly pronounced at the north and south poles. Existing methods either adopt a bi-projection fusion strategy to remove distortions or model long-range dependencies to capture global structures, which can result in either unclear structure or insufficient local perception. In this paper, we propose a spherical geometry transformer, named SGFormer, to address the above issues, with an innovative step to integrate spherical geometric priors into vision transformers. To this end, we retarget the transformer decoder to a spherical prior decoder (termed SPDecoder), which endeavors to uphold the integrity of spherical structures during decoding. Concretely, we leverage bipolar re-projection, circular rotation, and curve local embedding to preserve the spherical characteristics of equidistortion, continuity, and surface distance, respectively. Furthermore, we present a query-based global conditional position embedding to compensate for spatial structure at varying resolutions. It not only boosts the global perception of spatial position but also sharpens the depth structure across different patches. Finally, we conduct extensive experiments on popular benchmarks, demonstrating our superiority over state-of-the-art solutions.
360 Layout Estimation via Orthogonal Planes Disentanglement and Multi-view Geometric Consistency Perception
Dec 26, 2023



Existing panoramic layout estimation solutions tend to recover room boundaries from a vertically compressed sequence, yielding imprecise results as the compression process often muddles the semantics between various planes. Besides, these data-driven approaches impose an urgent demand for massive data annotations, which are laborious and time-consuming. For the first problem, we propose an orthogonal plane disentanglement network (termed DOPNet) to distinguish ambiguous semantics. DOPNet consists of three modules that are integrated to deliver distortion-free, semantics-clean, and detail-sharp disentangled representations, which benefit the subsequent layout recovery. For the second problem, we present an unsupervised adaptation technique tailored for horizon-depth and ratio representations. Concretely, we introduce an optimization strategy for decision-level layout analysis and a 1D cost volume construction method for feature-level multi-view aggregation, both of which are designed to fully exploit the geometric consistency across multiple perspectives. The optimizer provides a reliable set of pseudo-labels for network training, while the 1D cost volume enriches each view with comprehensive scene information derived from other perspectives. Extensive experiments demonstrate that our solution outperforms other SoTA models on both monocular layout estimation and multi-view layout estimation tasks.
Disentangling Orthogonal Planes for Indoor Panoramic Room Layout Estimation with Cross-Scale Distortion Awareness
Mar 04, 2023Based on the Manhattan World assumption, most existing indoor layout estimation schemes focus on recovering layouts from vertically compressed 1D sequences. However, the compression procedure confuses the semantics of different planes, yielding inferior performance with ambiguous interpretability. To address this issue, we propose to disentangle this 1D representation by pre-segmenting orthogonal (vertical and horizontal) planes from a complex scene, explicitly capturing the geometric cues for indoor layout estimation. Considering the symmetry between the floor boundary and ceiling boundary, we also design a soft-flipping fusion strategy to assist the pre-segmentation. Besides, we present a feature assembling mechanism to effectively integrate shallow and deep features with distortion distribution awareness. To compensate for the potential errors in pre-segmentation, we further leverage triple attention to reconstruct the disentangled sequences for better performance. Experiments on four popular benchmarks demonstrate our superiority over existing SoTA solutions, especially on the 3DIoU metric. The code is available at \url{https://github.com/zhijieshen-bjtu/DOPNet}.
Language-Universal Adapter Learning with Knowledge Distillation for End-to-End Multilingual Speech Recognition
Feb 28, 2023



In this paper, we propose a language-universal adapter learning framework based on a pre-trained model for end-to-end multilingual automatic speech recognition (ASR). For acoustic modeling, the wav2vec 2.0 pre-trained model is fine-tuned by inserting language-specific and language-universal adapters. An online knowledge distillation is then used to enable the language-universal adapters to learn both language-specific and universal features. The linguistic information confusion is also reduced by leveraging language identifiers (LIDs). With LIDs we perform a position-wise modification on the multi-head attention outputs. In the inference procedure, the language-specific adapters are removed while the language-universal adapters are kept activated. The proposed method improves the recognition accuracy and addresses the linear increase of the number of adapters' parameters with the number of languages in common multilingual ASR systems. Experiments on the BABEL dataset confirm the effectiveness of the proposed framework. Compared to the conventional multilingual model, a 3.3% absolute error rate reduction is achieved. The code is available at: https://github.com/shen9712/UniversalAdapterLearning.
Neural Contourlet Network for Monocular 360 Depth Estimation
Aug 03, 2022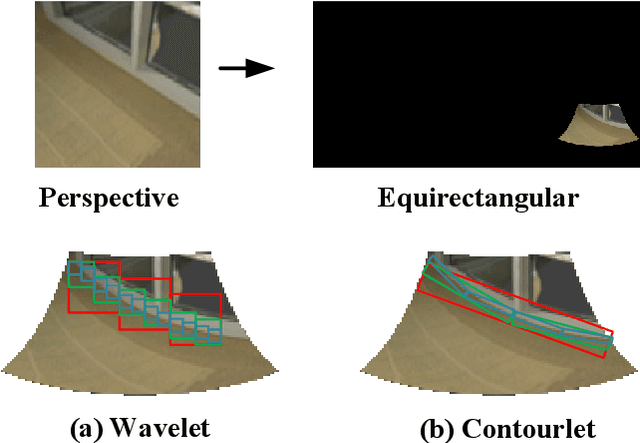


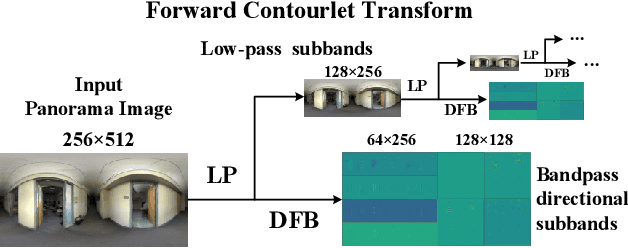
For a monocular 360 image, depth estimation is a challenging because the distortion increases along the latitude. To perceive the distortion, existing methods devote to designing a deep and complex network architecture. In this paper, we provide a new perspective that constructs an interpretable and sparse representation for a 360 image. Considering the importance of the geometric structure in depth estimation, we utilize the contourlet transform to capture an explicit geometric cue in the spectral domain and integrate it with an implicit cue in the spatial domain. Specifically, we propose a neural contourlet network consisting of a convolutional neural network and a contourlet transform branch. In the encoder stage, we design a spatial-spectral fusion module to effectively fuse two types of cues. Contrary to the encoder, we employ the inverse contourlet transform with learned low-pass subbands and band-pass directional subbands to compose the depth in the decoder. Experiments on the three popular panoramic image datasets demonstrate that the proposed approach outperforms the state-of-the-art schemes with faster convergence. Code is available at https://github.com/zhijieshen-bjtu/Neural-Contourlet-Network-for-MODE.
Complementary Bi-directional Feature Compression for Indoor 360° Semantic Segmentation with Self-distillation
Jul 06, 2022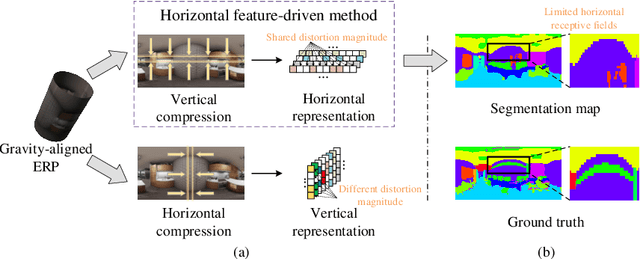
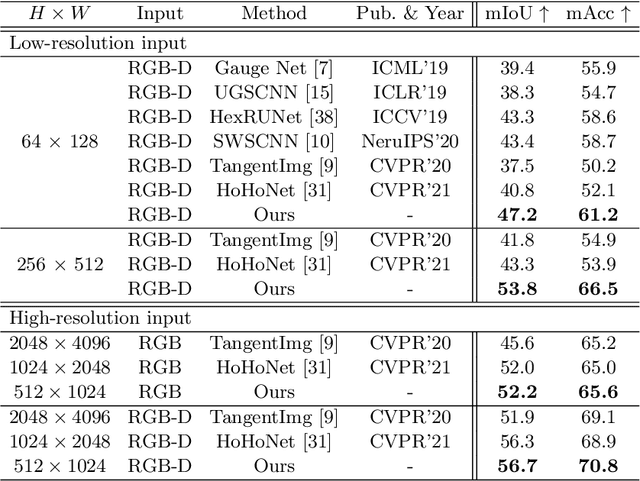
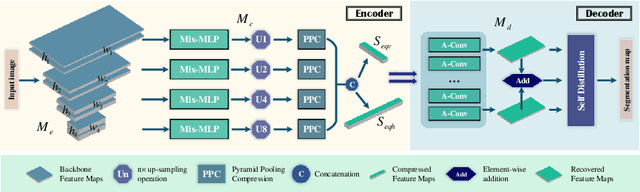
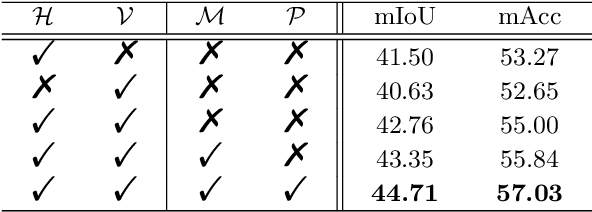
Recently, horizontal representation-based panoramic semantic segmentation approaches outperform projection-based solutions, because the distortions can be effectively removed by compressing the spherical data in the vertical direction. However, these methods ignore the distortion distribution prior and are limited to unbalanced receptive fields, e.g., the receptive fields are sufficient in the vertical direction and insufficient in the horizontal direction. Differently, a vertical representation compressed in another direction can offer implicit distortion prior and enlarge horizontal receptive fields. In this paper, we combine the two different representations and propose a novel 360{\deg} semantic segmentation solution from a complementary perspective. Our network comprises three modules: a feature extraction module, a bi-directional compression module, and an ensemble decoding module. First, we extract multi-scale features from a panorama. Then, a bi-directional compression module is designed to compress features into two complementary low-dimensional representations, which provide content perception and distortion prior. Furthermore, to facilitate the fusion of bi-directional features, we design a unique self distillation strategy in the ensemble decoding module to enhance the interaction of different features and further improve the performance. Experimental results show that our approach outperforms the state-of-the-art solutions with at least 10\% improvement on quantitative evaluations while displaying the best performance on visual appearance.