 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription and Discussion on DCASE 2026 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Apr 01, 2026This paper presents an overview of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2026 Challenge Task 4, Spatial Semantic Segmentation of Sound Scenes (S5). The S5 task focuses on the joint detection and separation of sound events in complex spatial audio mixtures, contributing to the foundation of immersive communication. First introduced in DCASE 2025, the S5 task continues in DCASE 2026 Task 4 with key changes to better reflect real-world conditions, including allowing mixtures to contain multiple sources of the same class and to contain no target sources. In this paper, we describe task setting, along with the corresponding updates to the evaluation metrics and dataset. The experimental results of the submitted systems are also reported and analyzed. The official access point for data and code is https://github.com/nttcslab/dcase2026_task4_baseline.
The Costs of Reproducibility in Music Separation Research: a Replication of Band-Split RNN
Mar 10, 2026Music source separation is the task of isolating the instrumental tracks from a music song. Despite its spectacular recent progress, the trend towards more complex architectures and training protocols exacerbates reproducibility issues. The band-split recurrent neural networks (BSRNN) model is promising in this regard, since it yields close to state-of-the-art results on public datasets, and requires reasonable resources for training. Unfortunately, it is not straightforward to reproduce since its full code is not available. In this paper, we attempt to replicate BSRNN as closely as possible to the original paper through extensive experiments, which allows us to conduct a critical reflection on this reproducibility issue. Our contributions are three-fold. First, this study yields several insights on the model design and training pipeline, which sheds light on potential future improvements. In particular, since we were unsuccessful in reproducing the original results, we explore additional variants that ultimately yield an optimized BSRNN model, whose performance largely improves that of the original. Second, we discuss reproducibility issues from both methodological and practical perspectives. We notably underline how substantial time and energy costs could have been saved upon availability of the full pipeline. Third, our code and pre-trained models are released publicly to foster reproducible research. We hope that this study will contribute to spread awareness on the importance of reproducible research in the music separation community, and help promoting more transparent and sustainable practices.
Posterior Transition Modeling for Unsupervised Diffusion-Based Speech Enhancement
Jul 03, 2025

We explore unsupervised speech enhancement using diffusion models as expressive generative priors for clean speech. Existing approaches guide the reverse diffusion process using noisy speech through an approximate, noise-perturbed likelihood score, combined with the unconditional score via a trade-off hyperparameter. In this work, we propose two alternative algorithms that directly model the conditional reverse transition distribution of diffusion states. The first method integrates the diffusion prior with the observation model in a principled way, removing the need for hyperparameter tuning. The second defines a diffusion process over the noisy speech itself, yielding a fully tractable and exact likelihood score. Experiments on the WSJ0-QUT and VoiceBank-DEMAND datasets demonstrate improved enhancement metrics and greater robustness to domain shifts compared to both supervised and unsupervised baselines.
Description and Discussion on DCASE 2025 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Jun 12, 2025

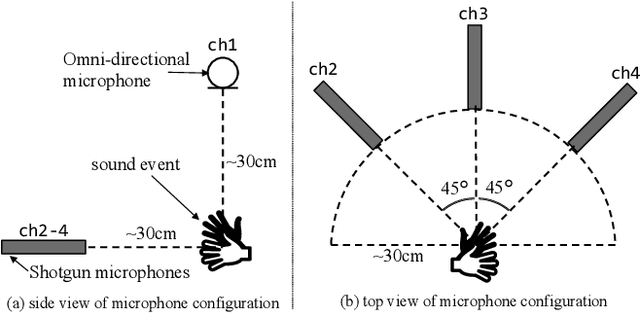
Spatial Semantic Segmentation of Sound Scenes (S5) aims to enhance technologies for sound event detection and separation from multi-channel input signals that mix multiple sound events with spatial information. This is a fundamental basis of immersive communication. The ultimate goal is to separate sound event signals with 6 Degrees of Freedom (6DoF) information into dry sound object signals and metadata about the object type (sound event class) and representing spatial information, including direction. However, because several existing challenge tasks already provide some of the subset functions, this task for this year focuses on detecting and separating sound events from multi-channel spatial input signals. This paper outlines the S5 task setting of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge Task 4 and the DCASE2025 Task 4 Dataset, newly recorded and curated for this task. We also report experimental results for an S5 system trained and evaluated on this dataset. The full version of this paper will be published after the challenge results are made public.
Tracking of Intermittent and Moving Speakers : Dataset and Metrics
Jun 11, 2025This paper presents the problem of tracking intermittent and moving sources, i.e, sources that may change position when they are inactive. This issue is seldom explored, and most current tracking methods rely on spatial observations for track identity management. They are either based on a previous localization step, or designed to perform joint localization and tracking by predicting ordered position estimates. This raises concerns about whether such methods can maintain reliable track identity assignment performance when dealing with discontinuous spatial tracks, which may be caused by a change of direction during silence. We introduce LibriJump, a novel dataset of acoustic scenes in the First Order Ambisonics format focusing on speaker tracking. The dataset contains speakers with changing positions during inactivity periods, thus simulating discontinuous tracks. To measure the identity assignment performance, we propose to use tracking association metrics adapted from the computer vision community. We provide experiments showing the complementarity of association metrics with previously used tracking metrics, given continuous and discontinuous spatial tracks.
Diffused Responsibility: Analyzing the Energy Consumption of Generative Text-to-Audio Diffusion Models
May 12, 2025


Text-to-audio models have recently emerged as a powerful technology for generating sound from textual descriptions. However, their high computational demands raise concerns about energy consumption and environmental impact. In this paper, we conduct an analysis of the energy usage of 7 state-of-the-art text-to-audio diffusion-based generative models, evaluating to what extent variations in generation parameters affect energy consumption at inference time. We also aim to identify an optimal balance between audio quality and energy consumption by considering Pareto-optimal solutions across all selected models. Our findings provide insights into the trade-offs between performance and environmental impact, contributing to the development of more efficient generative audio models.
Angular Distance Distribution Loss for Audio Classification
Oct 31, 2024Classification is a pivotal task in deep learning not only because of its intrinsic importance, but also for providing embeddings with desirable properties in other tasks. To optimize these properties, a wide variety of loss functions have been proposed that attempt to minimize the intra-class distance and maximize the inter-class distance in the embeddings space. In this paper we argue that, in addition to these two, eliminating hierarchies within and among classes are two other desirable properties for classification embeddings. Furthermore, we propose the Angular Distance Distribution (ADD) Loss, which aims to enhance the four previous properties jointly. For this purpose, it imposes conditions on the first and second order statistical moments of the angular distance between embeddings. Finally, we perform experiments showing that our loss function improves all four properties and, consequently, performs better than other loss functions in audio classification tasks.
A decade of DCASE: Achievements, practices, evaluations and future challenges
Oct 07, 2024This paper introduces briefly the history and growth of the Detection and Classification of Acoustic Scenes and Events (DCASE) challenge, workshop, research area and research community. Created in 2013 as a data evaluation challenge, DCASE has become a major research topic in the Audio and Acoustic Signal Processing area. Its success comes from a combination of factors: the challenge offers a large variety of tasks that are renewed each year; and the workshop offers a channel for dissemination of related work, engaging a young and dynamic community. At the same time, DCASE faces its own challenges, growing and expanding to different areas. One of the core principles of DCASE is open science and reproducibility: publicly available datasets, baseline systems, technical reports and workshop publications. While the DCASE challenge and workshop are independent of IEEE SPS, the challenge receives annual endorsement from the AASP TC, and the DCASE community contributes significantly to the ICASSP flagship conference and the success of SPS in many of its activities.
Diffusion-based Unsupervised Audio-visual Speech Enhancement
Oct 04, 2024

This paper proposes a new unsupervised audiovisual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF) noise model. First, the diffusion model is pre-trained on clean speech conditioned on corresponding video data to simulate the speech generative distribution. This pre-trained model is then paired with the NMF-based noise model to iteratively estimate clean speech. Specifically, a diffusion-based posterior sampling approach is implemented within the reverse diffusion process, where after each iteration, a speech estimate is obtained and used to update the noise parameters. Experimental results confirm that the proposed AVSE approach not only outperforms its audio-only counterpart but also generalizes better than a recent supervisedgenerative AVSE method. Additionally, the new inference algorithm offers a better balance between inference speed and performance compared to the previous diffusion-based method.
Domain-Invariant Representation Learning of Bird Sounds
Sep 16, 2024

Passive acoustic monitoring (PAM) is crucial for bioacoustic research, enabling non-invasive species tracking and biodiversity monitoring. Citizen science platforms like Xeno-Canto provide large annotated datasets from focal recordings, where the target species is intentionally recorded. However, PAM requires monitoring in passive soundscapes, creating a domain shift between focal and passive recordings, which challenges deep learning models trained on focal recordings. To address this, we leverage supervised contrastive learning to improve domain generalization in bird sound classification, enforcing domain invariance across same-class examples from different domains. We also propose ProtoCLR (Prototypical Contrastive Learning of Representations), which reduces the computational complexity of the SupCon loss by comparing examples to class prototypes instead of pairwise comparisons. Additionally, we present a new few-shot classification benchmark based on BirdSet, a large-scale bird sound dataset, and demonstrate the effectiveness of our approach in achieving strong transfer performance.