 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontend Token Enhancement for Token-Based Speech Recognition
Feb 04, 2026Discretized representations of speech signals are efficient alternatives to continuous features for various speech applications, including automatic speech recognition (ASR) and speech language models. However, these representations, such as semantic or phonetic tokens derived from clustering outputs of self-supervised learning (SSL) speech models, are susceptible to environmental noise, which can degrade backend task performance. In this work, we introduce a frontend system that estimates clean speech tokens from noisy speech and evaluate it on an ASR backend using semantic tokens. We consider four types of enhancement models based on their input/output domains: wave-to-wave, token-to-token, continuous SSL features-to-token, and wave-to-token. These models are trained independently of ASR backends. Experiments on the CHiME-4 dataset demonstrate that wave-to-token enhancement achieves the best performance among the frontends. Moreover, it mostly outperforms the ASR system based on continuous SSL features.
MOVER: Combining Multiple Meeting Recognition Systems
Aug 07, 2025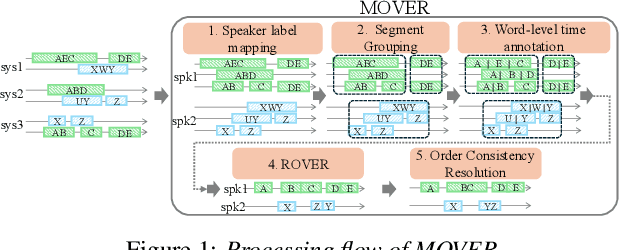
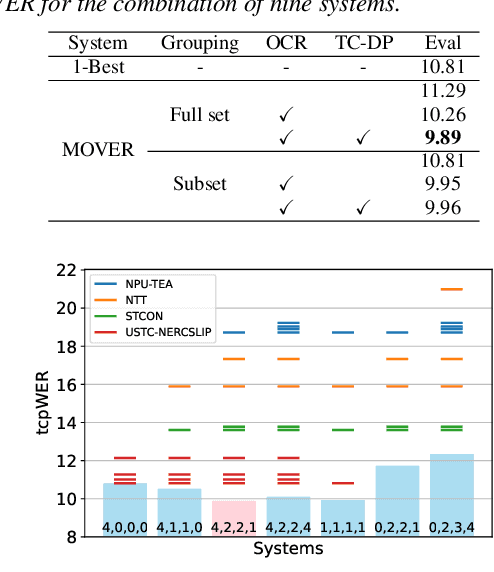
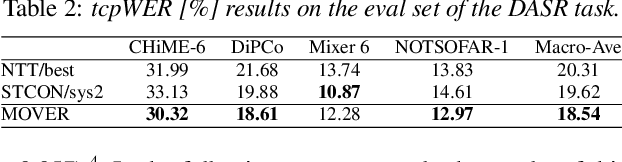
In this paper, we propose Meeting recognizer Output Voting Error Reduction (MOVER), a novel system combination method for meeting recognition tasks. Although there are methods to combine the output of diarization (e.g., DOVER) or automatic speech recognition (ASR) systems (e.g., ROVER), MOVER is the first approach that can combine the outputs of meeting recognition systems that differ in terms of both diarization and ASR. MOVER combines hypotheses with different time intervals and speaker labels through a five-stage process that includes speaker alignment, segment grouping, word and timing combination, etc. Experimental results on the CHiME-8 DASR task and the multi-channel track of the NOTSOFAR-1 task demonstrate that MOVER can successfully combine multiple meeting recognition systems with diverse diarization and recognition outputs, achieving relative tcpWER improvements of 9.55 % and 8.51 % over the state-of-the-art systems for both tasks.
Generic Speech Enhancement with Self-Supervised Representation Space Loss
Jul 10, 2025



Single-channel speech enhancement is utilized in various tasks to mitigate the effect of interfering signals. Conventionally, to ensure the speech enhancement performs optimally, the speech enhancement has needed to be tuned for each task. Thus, generalizing speech enhancement models to unknown downstream tasks has been challenging. This study aims to construct a generic speech enhancement front-end that can improve the performance of back-ends to solve multiple downstream tasks. To this end, we propose a novel training criterion that minimizes the distance between the enhanced and the ground truth clean signal in the feature representation domain of self-supervised learning models. Since self-supervised learning feature representations effectively express high-level speech information useful for solving various downstream tasks, the proposal is expected to make speech enhancement models preserve such information. Experimental validation demonstrates that the proposal improves the performance of multiple speech tasks while maintaining the perceptual quality of the enhanced signal.
* 22 pages, 3 figures. Accepted for Frontiers in signal processing
TS-SUPERB: A Target Speech Processing Benchmark for Speech Self-Supervised Learning Models
May 10, 2025



Self-supervised learning (SSL) models have significantly advanced speech processing tasks, and several benchmarks have been proposed to validate their effectiveness. However, previous benchmarks have primarily focused on single-speaker scenarios, with less exploration of target-speaker tasks in noisy, multi-talker conditions -- a more challenging yet practical case. In this paper, we introduce the Target-Speaker Speech Processing Universal Performance Benchmark (TS-SUPERB), which includes four widely recognized target-speaker processing tasks that require identifying the target speaker and extracting information from the speech mixture. In our benchmark, the speaker embedding extracted from enrollment speech is used as a clue to condition downstream models. The benchmark result reveals the importance of evaluating SSL models in target speaker scenarios, demonstrating that performance cannot be easily inferred from related single-speaker tasks. Moreover, by using a unified SSL-based target speech encoder, consisting of a speaker encoder and an extractor module, we also investigate joint optimization across TS tasks to leverage mutual information and demonstrate its effectiveness.
Microphone Array Signal Processing and Deep Learning for Speech Enhancement
Jan 13, 2025



Multi-channel acoustic signal processing is a well-established and powerful tool to exploit the spatial diversity between a target signal and non-target or noise sources for signal enhancement. However, the textbook solutions for optimal data-dependent spatial filtering rest on the knowledge of second-order statistical moments of the signals, which have traditionally been difficult to acquire. In this contribution, we compare model-based, purely data-driven, and hybrid approaches to parameter estimation and filtering, where the latter tries to combine the benefits of model-based signal processing and data-driven deep learning to overcome their individual deficiencies. We illustrate the underlying design principles with examples from noise reduction, source separation, and dereverberation.
* Accepted for IEEE Signal Processing Magazine
Investigation of Speaker Representation for Target-Speaker Speech Processing
Oct 15, 2024



Target-speaker speech processing (TS) tasks, such as target-speaker automatic speech recognition (TS-ASR), target speech extraction (TSE), and personal voice activity detection (p-VAD), are important for extracting information about a desired speaker's speech even when it is corrupted by interfering speakers. While most studies have focused on training schemes or system architectures for each specific task, the auxiliary network for embedding target-speaker cues has not been investigated comprehensively in a unified cross-task evaluation. Therefore, this paper aims to address a fundamental question: what is the preferred speaker embedding for TS tasks? To this end, for the TS-ASR, TSE, and p-VAD tasks, we compare pre-trained speaker encoders (i.e., self-supervised or speaker recognition models) that compute speaker embeddings from pre-recorded enrollment speech of the target speaker with ideal speaker embeddings derived directly from the target speaker's identity in the form of a one-hot vector. To further understand the properties of ideal speaker embedding, we optimize it using a gradient-based approach to improve performance on the TS task. Our analysis reveals that speaker verification performance is somewhat unrelated to TS task performances, the one-hot vector outperforms enrollment-based ones, and the optimal embedding depends on the input mixture.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024



We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Interaural time difference loss for binaural target sound extraction
Aug 01, 2024

Binaural target sound extraction (TSE) aims to extract a desired sound from a binaural mixture of arbitrary sounds while preserving the spatial cues of the desired sound. Indeed, for many applications, the target sound signal and its spatial cues carry important information about the sound source. Binaural TSE can be realized with a neural network trained to output only the desired sound given a binaural mixture and an embedding characterizing the desired sound class as inputs. Conventional TSE systems are trained using signal-level losses, which measure the difference between the extracted and reference signals for the left and right channels. In this paper, we propose adding explicit spatial losses to better preserve the spatial cues of the target sound. In particular, we explore losses aiming at preserving the interaural level (ILD), phase (IPD), and time differences (ITD). We show experimentally that adding such spatial losses, particularly our newly proposed ITD loss, helps preserve better spatial cues while maintaining the signal-level metrics.
SpeakerBeam-SS: Real-time Target Speaker Extraction with Lightweight Conv-TasNet and State Space Modeling
Jul 01, 2024


Real-time target speaker extraction (TSE) is intended to extract the desired speaker's voice from the observed mixture of multiple speakers in a streaming manner. Implementing real-time TSE is challenging as the computational complexity must be reduced to provide real-time operation. This work introduces to Conv-TasNet-based TSE a new architecture based on state space modeling (SSM) that has been shown to model long-term dependency effectively. Owing to SSM, fewer dilated convolutional layers are required to capture temporal dependency in Conv-TasNet, resulting in the reduction of model complexity. We also enlarge the window length and shift of the convolutional (TasNet) frontend encoder to reduce the computational cost further; the performance decline is compensated by over-parameterization of the frontend encoder. The proposed method reduces the real-time factor by 78% from the conventional causal Conv-TasNet-based TSE while matching its performance.
Rethinking Processing Distortions: Disentangling the Impact of Speech Enhancement Errors on Speech Recognition Performance
Apr 23, 2024



It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with a single-channel speech enhancement (SE) front-end. This is generally attributed to the processing distortions caused by the nonlinear processing of single-channel SE front-ends. However, the causes of such degraded ASR performance have not been fully investigated. How to design single-channel SE front-ends in a way that significantly improves ASR performance remains an open research question. In this study, we investigate a signal-level numerical metric that can explain the cause of degradation in ASR performance. To this end, we propose a novel analysis scheme based on the orthogonal projection-based decomposition of SE errors. This scheme manually modifies the ratio of the decomposed interference, noise, and artifact errors, and it enables us to directly evaluate the impact of each error type on ASR performance. Our analysis reveals the particularly detrimental effect of artifact errors on ASR performance compared to the other types of errors. This provides us with a more principled definition of processing distortions that cause the ASR performance degradation. Then, we study two practical approaches for reducing the impact of artifact errors. First, we prove that the simple observation adding (OA) post-processing (i.e., interpolating the enhanced and observed signals) can monotonically improve the signal-to-artifact ratio. Second, we propose a novel training objective, called artifact-boosted signal-to-distortion ratio (AB-SDR), which forces the model to estimate the enhanced signals with fewer artifact errors. Through experiments, we confirm that both the OA and AB-SDR approaches are effective in decreasing artifact errors caused by single-channel SE front-ends, allowing them to significantly improve ASR performance.