 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of ABC Frontend Audio Systems for the NIST-SRE24
May 21, 2025We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
State-of-the-art Embeddings with Video-free Segmentation of the Source VoxCeleb Data
Oct 03, 2024



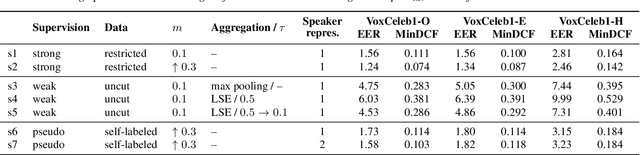
In this paper, we refine and validate our method for training speaker embedding extractors using weak annotations. More specifically, we use only the audio stream of the source VoxCeleb videos and the names of the celebrities without knowing the time intervals in which they appear in the recording. We experiment with hyperparameters and embedding extractors based on ResNet and WavLM. We show that the method achieves state-of-the-art results in speaker verification, comparable with training the extractors in a standard supervised way on the VoxCeleb dataset. We also extend it by considering segments belonging to unknown speakers appearing alongside the celebrities, which are typically being discarded. Overall, our approach can be used for directly training state-of-the-art embedding extractors or as an alternative to the VoxCeleb-like pipeline for dataset creation without needing image modality.
BUT CHiME-7 system description
Oct 18, 2023



This paper describes the joint effort of Brno University of Technology (BUT), AGH University of Krakow and University of Buenos Aires on the development of Automatic Speech Recognition systems for the CHiME-7 Challenge. We train and evaluate various end-to-end models with several toolkits. We heavily relied on Guided Source Separation (GSS) to convert multi-channel audio to single channel. The ASR is leveraging speech representations from models pre-trained by self-supervised learning, and we do a fusion of several ASR systems. In addition, we modified external data from the LibriSpeech corpus to become a close domain and added it to the training. Our efforts were focused on the far-field acoustic robustness sub-track of Task 1 - Distant Automatic Speech Recognition (DASR), our systems use oracle segmentation.
Improving Speaker Verification with Self-Pretrained Transformer Models
May 17, 2023



Recently, fine-tuning large pre-trained Transformer models using downstream datasets has received a rising interest. Despite their success, it is still challenging to disentangle the benefits of large-scale datasets and Transformer structures from the limitations of the pre-training. In this paper, we introduce a hierarchical training approach, named self-pretraining, in which Transformer models are pretrained and finetuned on the same dataset. Three pre-trained models including HuBERT, Conformer and WavLM are evaluated on four different speaker verification datasets with varying sizes. Our experiments show that these self-pretrained models achieve competitive performance on downstream speaker verification tasks with only one-third of the data compared to Librispeech pretraining, such as VoxCeleb1 and CNCeleb1. Furthermore, when pre-training only on the VoxCeleb2-dev, the Conformer model outperforms the one pre-trained on 94k hours of data using the same fine-tuning settings.
Parameter-efficient transfer learning of pre-trained Transformer models for speaker verification using adapters
Oct 28, 2022



Recently, the pre-trained Transformer models have received a rising interest in the field of speech processing thanks to their great success in various downstream tasks. However, most fine-tuning approaches update all the parameters of the pre-trained model, which becomes prohibitive as the model size grows and sometimes results in overfitting on small datasets. In this paper, we conduct a comprehensive analysis of applying parameter-efficient transfer learning (PETL) methods to reduce the required learnable parameters for adapting to speaker verification tasks. Specifically, during the fine-tuning process, the pre-trained models are frozen, and only lightweight modules inserted in each Transformer block are trainable (a method known as adapters). Moreover, to boost the performance in a cross-language low-resource scenario, the Transformer model is further tuned on a large intermediate dataset before directly fine-tuning it on a small dataset. With updating fewer than 4% of parameters, (our proposed) PETL-based methods achieve comparable performances with full fine-tuning methods (Vox1-O: 0.55%, Vox1-E: 0.82%, Vox1-H:1.73%).
Analysis of impact of emotions on target speech extraction and speech separation
Aug 15, 2022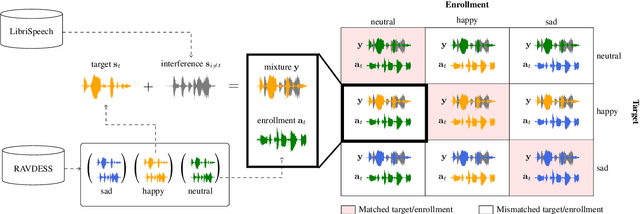
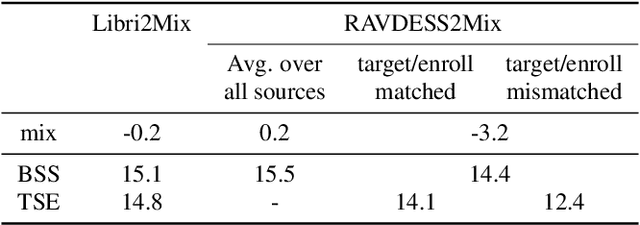
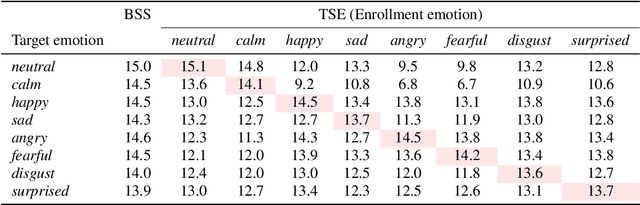
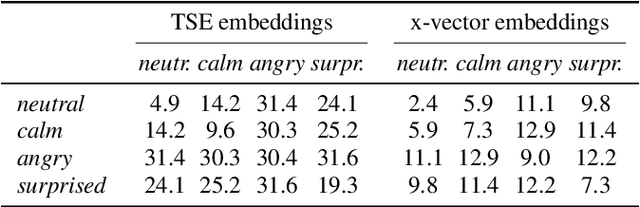
Recently, the performance of blind speech separation (BSS) and target speech extraction (TSE) has greatly progressed. Most works, however, focus on relatively well-controlled conditions using, e.g., read speech. The performance may degrade in more realistic situations. One of the factors causing such degradation may be intrinsic speaker variability, such as emotions, occurring commonly in realistic speech. In this paper, we investigate the influence of emotions on TSE and BSS. We create a new test dataset of emotional mixtures for the evaluation of TSE and BSS. This dataset combines LibriSpeech and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). Through controlled experiments, we can analyze the impact of different emotions on the performance of BSS and TSE. We observe that BSS is relatively robust to emotions, while TSE, which requires identifying and extracting the speech of a target speaker, is much more sensitive to emotions. On comparative speaker verification experiments we show that identifying the target speaker may be particularly challenging when dealing with emotional speech. Using our findings, we outline potential future directions that could improve the robustness of BSS and TSE systems toward emotional speech.
Training Speaker Embedding Extractors Using Multi-Speaker Audio with Unknown Speaker Boundaries
Mar 29, 2022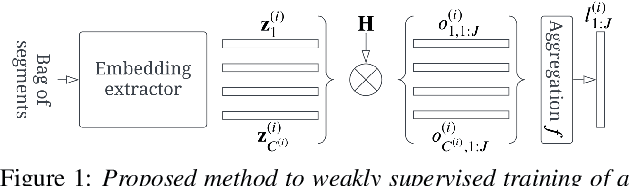
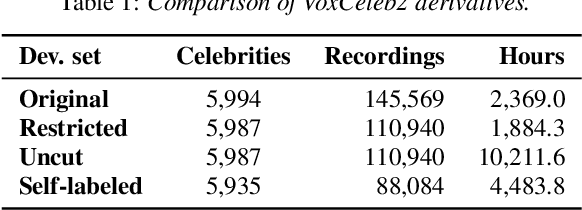
In this paper, we demonstrate a method for training speaker embedding extractors using weak annotation. More specifically, we are using the full VoxCeleb recordings and the name of the celebrities appearing on each video without knowledge of the time intervals the celebrities appear in the video. We show that by combining a baseline speaker diarization algorithm that requires no training or parameter tuning, a modified loss with aggregation over segments, and a two-stage training approach, we are able to train a competitive ResNet-based embedding extractor. Finally, we experiment with two different aggregation functions and analyze their behaviour in terms of their gradients.
Probabilistic Spherical Discriminant Analysis: An Alternative to PLDA for length-normalized embeddings
Mar 28, 2022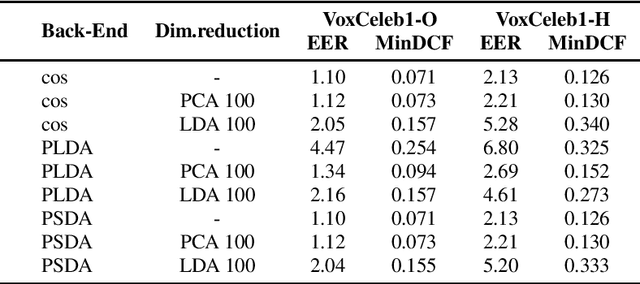
In speaker recognition, where speech segments are mapped to embeddings on the unit hypersphere, two scoring backends are commonly used, namely cosine scoring or PLDA. Both have advantages and disadvantages, depending on the context. Cosine scoring follows naturally from the spherical geometry, but for PLDA the blessing is mixed -- length normalization Gaussianizes the between-speaker distribution, but violates the assumption of a speaker-independent within-speaker distribution. We propose PSDA, an analogue to PLDA that uses Von Mises-Fisher distributions on the hypersphere for both within and between-class distributions. We show how the self-conjugacy of this distribution gives closed-form likelihood-ratio scores, making it a drop-in replacement for PLDA at scoring time. All kinds of trials can be scored, including single-enroll and multi-enroll verification, as well as more complex likelihood-ratios that could be used in clustering and diarization. Learning is done via an EM-algorithm with closed-form updates. We explain the model and present some first experiments.
MultiSV: Dataset for Far-Field Multi-Channel Speaker Verification
Nov 11, 2021
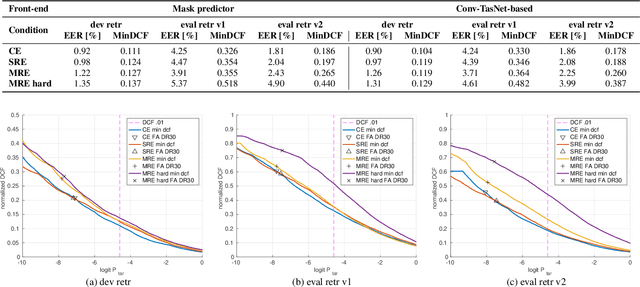
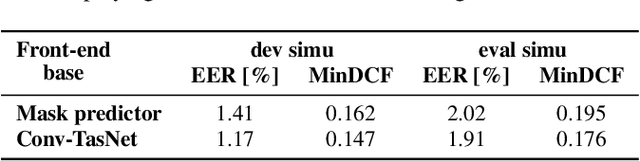
Motivated by unconsolidated data situation and the lack of a standard benchmark in the field, we complement our previous efforts and present a comprehensive corpus designed for training and evaluating text-independent multi-channel speaker verification systems. It can be readily used also for experiments with dereverberation, denoising, and speech enhancement. We tackled the ever-present problem of the lack of multi-channel training data by utilizing data simulation on top of clean parts of the Voxceleb dataset. The development and evaluation trials are based on a retransmitted Voices Obscured in Complex Environmental Settings (VOiCES) corpus, which we modified to provide multi-channel trials. We publish full recipes that create the dataset from public sources as the MultiSV corpus, and we provide results with two of our multi-channel speaker verification systems with neural network-based beamforming based either on predicting ideal binary masks or the more recent Conv-TasNet.
BUT VOiCES 2019 System Description
Jul 13, 2019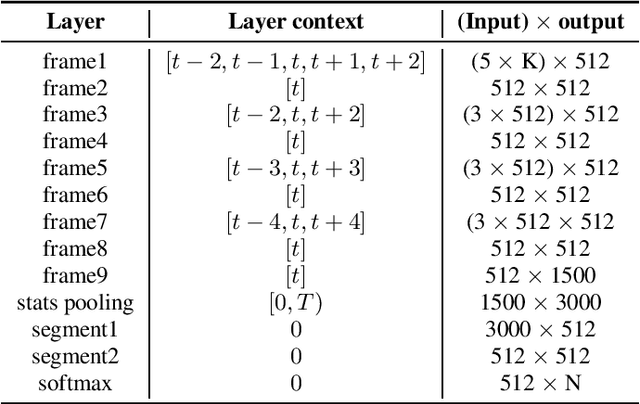
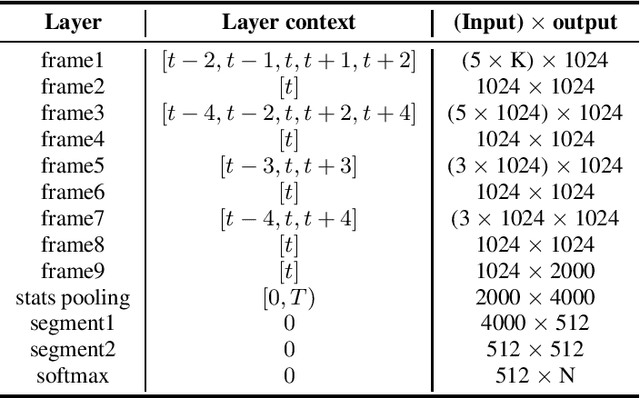
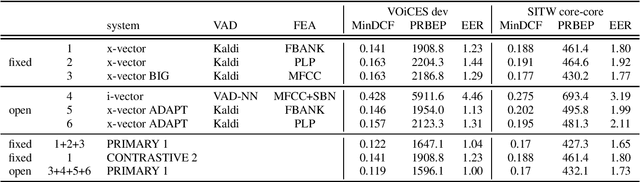
This is a description of our effort in VOiCES 2019 Speaker Recognition challenge. All systems in the fixed condition are based on the x-vector paradigm with different features and DNN topologies. The single best system reaches 1.2% EER and a fusion of 3 systems yields 1.0% EER, which is 15% relative improvement. The open condition allowed us to use external data which we did for the PLDA adaptation and achieved less than ~10% relative improvement. In the submission to open condition, we used 3 x-vector systems and also one i-vector based system.