 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription and Discussion on DCASE 2026 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Apr 01, 2026This paper presents an overview of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2026 Challenge Task 4, Spatial Semantic Segmentation of Sound Scenes (S5). The S5 task focuses on the joint detection and separation of sound events in complex spatial audio mixtures, contributing to the foundation of immersive communication. First introduced in DCASE 2025, the S5 task continues in DCASE 2026 Task 4 with key changes to better reflect real-world conditions, including allowing mixtures to contain multiple sources of the same class and to contain no target sources. In this paper, we describe task setting, along with the corresponding updates to the evaluation metrics and dataset. The experimental results of the submitted systems are also reported and analyzed. The official access point for data and code is https://github.com/nttcslab/dcase2026_task4_baseline.
Who Spoke What When? Evaluating Spoken Language Models for Conversational ASR with Semantic and Overlap-Aware Metrics
Mar 24, 2026Conversational automatic speech recognition remains challenging due to overlapping speech, far-field noise, and varying speaker counts. While recent LLM-based systems perform well on single-speaker benchmarks, their robustness in multi-speaker settings is unclear. We systematically compare LLM-based and modular pipeline approaches along four axes: overlap robustness, semantic fidelity, speaker count, and single- versus multi-channel input. To capture meaning-altering errors that conventional metrics miss, we introduce tcpSemER, which extends tcpWER by replacing Levenshtein distance with embedding-based semantic similarity. We further decompose tcpWER into overlapping and non-overlapping components for finer-grained analysis. Experiments across three datasets show that LLM-based systems are competitive in two-speaker settings but degrade as speaker count and overlap increase, whereas modular pipelines remain more robust.
Joint Enhancement and Classification using Coupled Diffusion Models of Signals and Logits
Feb 17, 2026Robust classification in noisy environments remains a fundamental challenge in machine learning. Standard approaches typically treat signal enhancement and classification as separate, sequential stages: first enhancing the signal and then applying a classifier. This approach fails to leverage the semantic information in the classifier's output during denoising. In this work, we propose a general, domain-agnostic framework that integrates two interacting diffusion models: one operating on the input signal and the other on the classifier's output logits, without requiring any retraining or fine-tuning of the classifier. This coupled formulation enables mutual guidance, where the enhancing signal refines the class estimation and, conversely, the evolving class logits guide the signal reconstruction towards discriminative regions of the manifold. We introduce three strategies to effectively model the joint distribution of the input and the logit. We evaluated our joint enhancement method for image classification and automatic speech recognition. The proposed framework surpasses traditional sequential enhancement baselines, delivering robust and flexible improvements in classification accuracy under diverse noise conditions.
Frontend Token Enhancement for Token-Based Speech Recognition
Feb 04, 2026Discretized representations of speech signals are efficient alternatives to continuous features for various speech applications, including automatic speech recognition (ASR) and speech language models. However, these representations, such as semantic or phonetic tokens derived from clustering outputs of self-supervised learning (SSL) speech models, are susceptible to environmental noise, which can degrade backend task performance. In this work, we introduce a frontend system that estimates clean speech tokens from noisy speech and evaluate it on an ASR backend using semantic tokens. We consider four types of enhancement models based on their input/output domains: wave-to-wave, token-to-token, continuous SSL features-to-token, and wave-to-token. These models are trained independently of ASR backends. Experiments on the CHiME-4 dataset demonstrate that wave-to-token enhancement achieves the best performance among the frontends. Moreover, it mostly outperforms the ASR system based on continuous SSL features.
Loose coupling of spectral and spatial models for multi-channel diarization and enhancement of meetings in dynamic environments
Jan 22, 2026Sound capture by microphone arrays opens the possibility to exploit spatial, in addition to spectral, information for diarization and signal enhancement, two important tasks in meeting transcription. However, there is no one-to-one mapping of positions in space to speakers if speakers move. Here, we address this by proposing a novel joint spatial and spectral mixture model, whose two submodels are loosely coupled by modeling the relationship between speaker and position index probabilistically. Thus, spatial and spectral information can be jointly exploited, while at the same time allowing for speakers speaking from different positions. Experiments on the LibriCSS data set with simulated speaker position changes show great improvements over tightly coupled subsystems.
Reference Microphone Selection for Guided Source Separation based on the Normalized L-p Norm
Oct 31, 2025
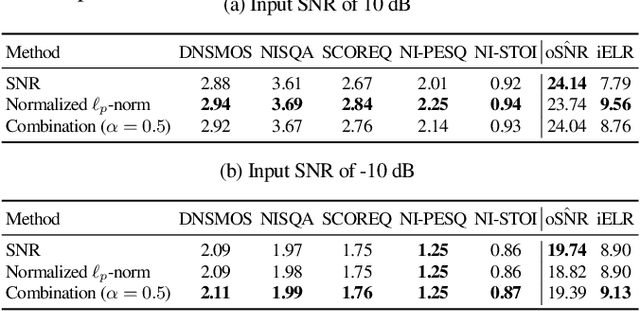

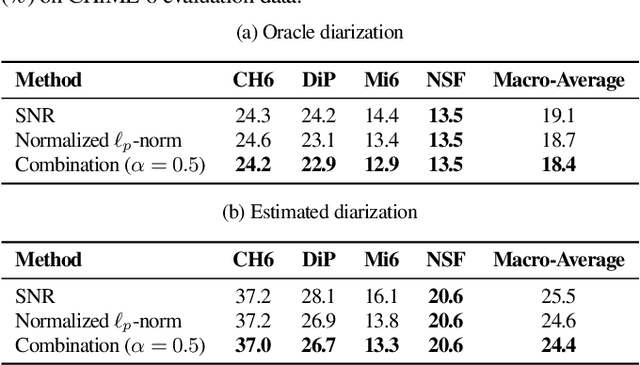
Guided Source Separation (GSS) is a popular front-end for distant automatic speech recognition (ASR) systems using spatially distributed microphones. When considering spatially distributed microphones, the choice of reference microphone may have a large influence on the quality of the output signal and the downstream ASR performance. In GSS-based speech enhancement, reference microphone selection is typically performed using the signal-to-noise ratio (SNR), which is optimal for noise reduction but may neglect differences in early-to-late-reverberant ratio (ELR) across microphones. In this paper, we propose two reference microphone selection methods for GSS-based speech enhancement that are based on the normalized $\ell_p$-norm, either using only the normalized $\ell_p$-norm or combining the normalized $\ell_p$-norm and the SNR to account for both differences in SNR and ELR across microphones. Experimental evaluation using a CHiME-8 distant ASR system shows that the proposed $\ell_p$-norm-based methods outperform the baseline method, reducing the macro-average word error rate.
FlexIO: Flexible Single- and Multi-Channel Speech Separation and Enhancement
Oct 24, 2025Speech separation and enhancement (SSE) has advanced remarkably and achieved promising results in controlled settings, such as a fixed number of speakers and a fixed array configuration. Towards a universal SSE system, single-channel systems have been extended to deal with a variable number of speakers (i.e., outputs). Meanwhile, multi-channel systems accommodating various array configurations (i.e., inputs) have been developed. However, these attempts have been pursued separately. In this paper, we propose a flexible input and output SSE system, named FlexIO. It performs conditional separation using prompt vectors, one per speaker as a condition, allowing separation of an arbitrary number of speakers. Multi-channel mixtures are processed together with the prompt vectors via an array-agnostic channel communication mechanism. Our experiments demonstrate that FlexIO successfully covers diverse conditions with one to five microphones and one to three speakers. We also confirm the robustness of FlexIO on CHiME-4 real data.
MOVER: Combining Multiple Meeting Recognition Systems
Aug 07, 2025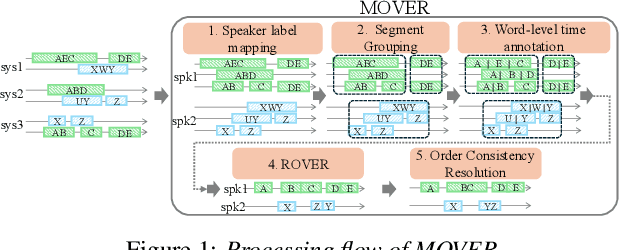
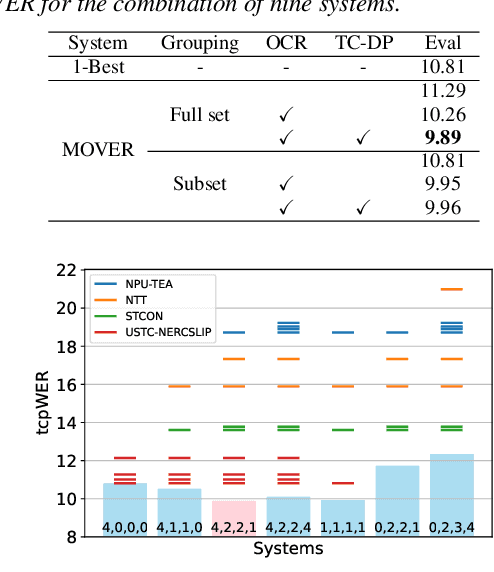
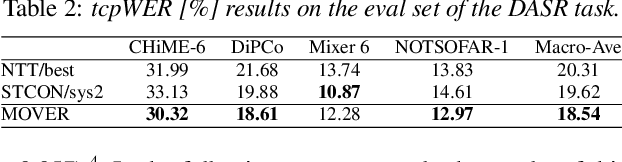
In this paper, we propose Meeting recognizer Output Voting Error Reduction (MOVER), a novel system combination method for meeting recognition tasks. Although there are methods to combine the output of diarization (e.g., DOVER) or automatic speech recognition (ASR) systems (e.g., ROVER), MOVER is the first approach that can combine the outputs of meeting recognition systems that differ in terms of both diarization and ASR. MOVER combines hypotheses with different time intervals and speaker labels through a five-stage process that includes speaker alignment, segment grouping, word and timing combination, etc. Experimental results on the CHiME-8 DASR task and the multi-channel track of the NOTSOFAR-1 task demonstrate that MOVER can successfully combine multiple meeting recognition systems with diverse diarization and recognition outputs, achieving relative tcpWER improvements of 9.55 % and 8.51 % over the state-of-the-art systems for both tasks.
Generic Speech Enhancement with Self-Supervised Representation Space Loss
Jul 10, 2025



Single-channel speech enhancement is utilized in various tasks to mitigate the effect of interfering signals. Conventionally, to ensure the speech enhancement performs optimally, the speech enhancement has needed to be tuned for each task. Thus, generalizing speech enhancement models to unknown downstream tasks has been challenging. This study aims to construct a generic speech enhancement front-end that can improve the performance of back-ends to solve multiple downstream tasks. To this end, we propose a novel training criterion that minimizes the distance between the enhanced and the ground truth clean signal in the feature representation domain of self-supervised learning models. Since self-supervised learning feature representations effectively express high-level speech information useful for solving various downstream tasks, the proposal is expected to make speech enhancement models preserve such information. Experimental validation demonstrates that the proposal improves the performance of multiple speech tasks while maintaining the perceptual quality of the enhanced signal.
* 22 pages, 3 figures. Accepted for Frontiers in signal processing
Mitigating Non-Target Speaker Bias in Guided Speaker Embedding
Jun 14, 2025Obtaining high-quality speaker embeddings in multi-speaker conditions is crucial for many applications. A recently proposed guided speaker embedding framework, which utilizes speech activities of target and non-target speakers as clues, drastically improved embeddings under severe overlap with small degradation in low-overlap cases. However, since extreme overlaps are rare in natural conversations, this degradation cannot be overlooked. This paper first reveals that the degradation is caused by the global-statistics-based modules, widely used in speaker embedding extractors, being overly sensitive to intervals containing only non-target speakers. As a countermeasure, we propose an extension of such modules that exploit the target speaker activity clues, to compute statistics from intervals where the target is active. The proposed method improves speaker verification performance in both low and high overlap ratios, and diarization performance on multiple datasets.