 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Differentially Private Speaker Anonymization
Feb 23, 2022
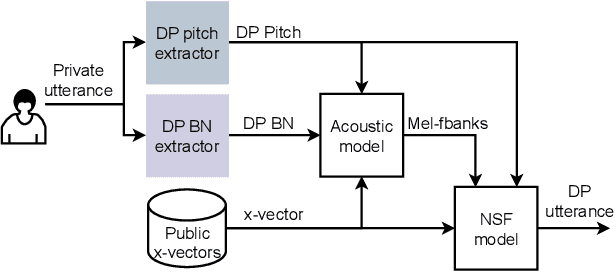
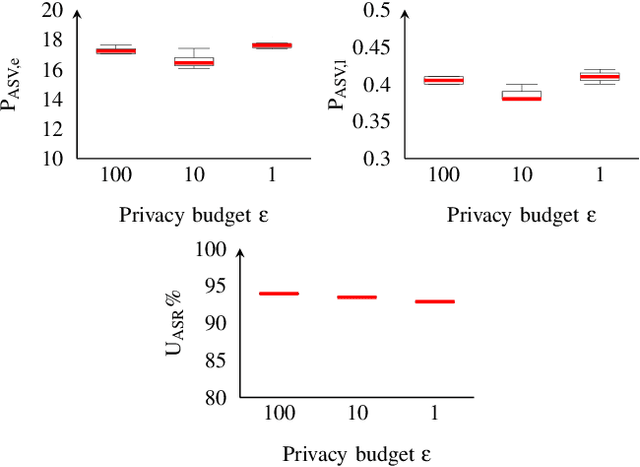
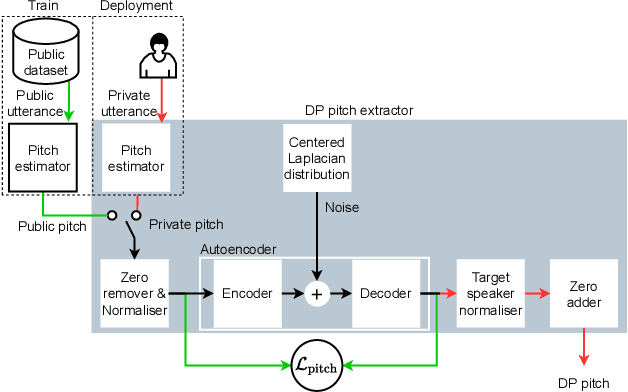
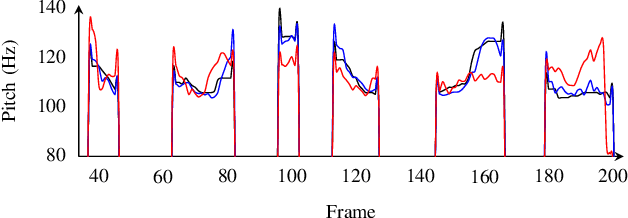
Sharing real-world speech utterances is key to the training and deployment of voice-based services. However, it also raises privacy risks as speech contains a wealth of personal data. Speaker anonymization aims to remove speaker information from a speech utterance while leaving its linguistic and prosodic attributes intact. State-of-the-art techniques operate by disentangling the speaker information (represented via a speaker embedding) from these attributes and re-synthesizing speech based on the speaker embedding of another speaker. Prior research in the privacy community has shown that anonymization often provides brittle privacy protection, even less so any provable guarantee. In this work, we show that disentanglement is indeed not perfect: linguistic and prosodic attributes still contain speaker information. We remove speaker information from these attributes by introducing differentially private feature extractors based on an autoencoder and an automatic speech recognizer, respectively, trained using noise layers. We plug these extractors in the state-of-the-art anonymization pipeline and generate, for the first time, differentially private utterances with a provable upper bound on the speaker information they contain. We evaluate empirically the privacy and utility resulting from our differentially private speaker anonymization approach on the LibriSpeech data set. Experimental results show that the generated utterances retain very high utility for automatic speech recognition training and inference, while being much better protected against strong adversaries who leverage the full knowledge of the anonymization process to try to infer the speaker identity.
Effect of noise suppression losses on speech distortion and ASR performance
Nov 23, 2021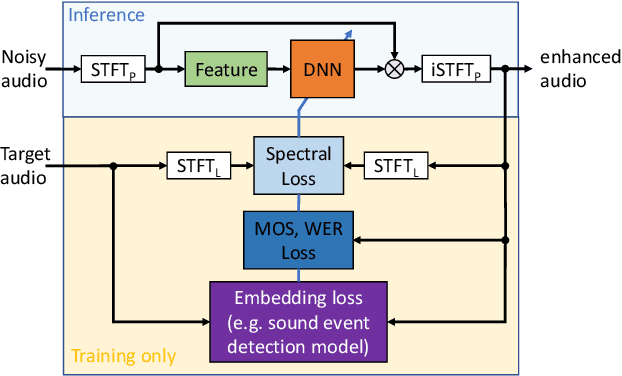
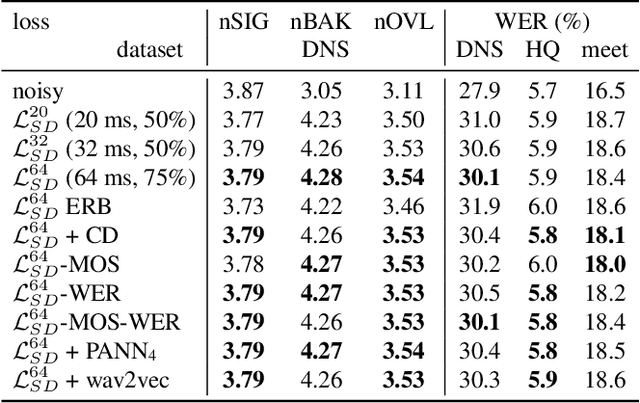
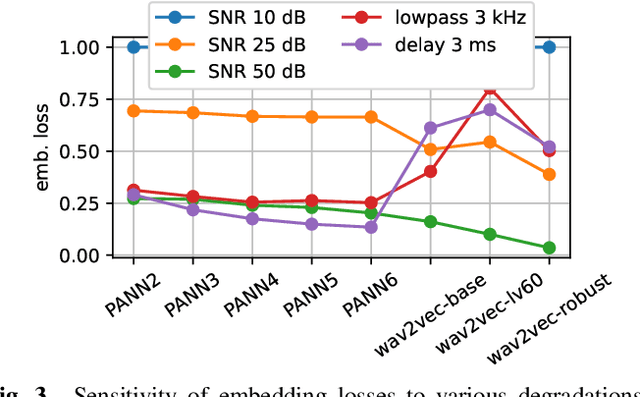
Deep learning based speech enhancement has made rapid development towards improving quality, while models are becoming more compact and usable for real-time on-the-edge inference. However, the speech quality scales directly with the model size, and small models are often still unable to achieve sufficient quality. Furthermore, the introduced speech distortion and artifacts greatly harm speech quality and intelligibility, and often significantly degrade automatic speech recognition (ASR) rates. In this work, we shed light on the success of the spectral complex compressed mean squared error (MSE) loss, and how its magnitude and phase-aware terms are related to the speech distortion vs. noise reduction trade off. We further investigate integrating pre-trained reference-less predictors for mean opinion score (MOS) and word error rate (WER), and pre-trained embeddings on ASR and sound event detection. Our analyses reveal that none of the pre-trained networks added significant performance over the strong spectral loss.
UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Jan 19, 2021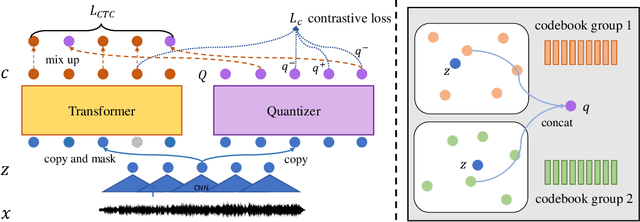
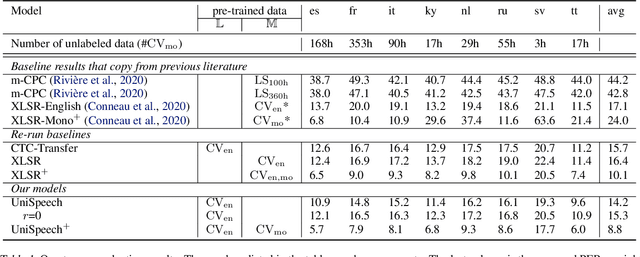

In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.
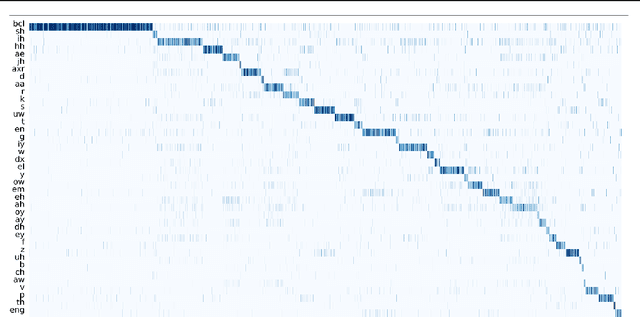
Hear "No Evil", See "Kenansville": Efficient and Transferable Black-Box Attacks on Speech Recognition and Voice Identification Systems
Oct 11, 2019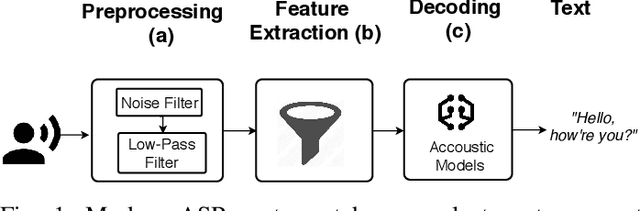
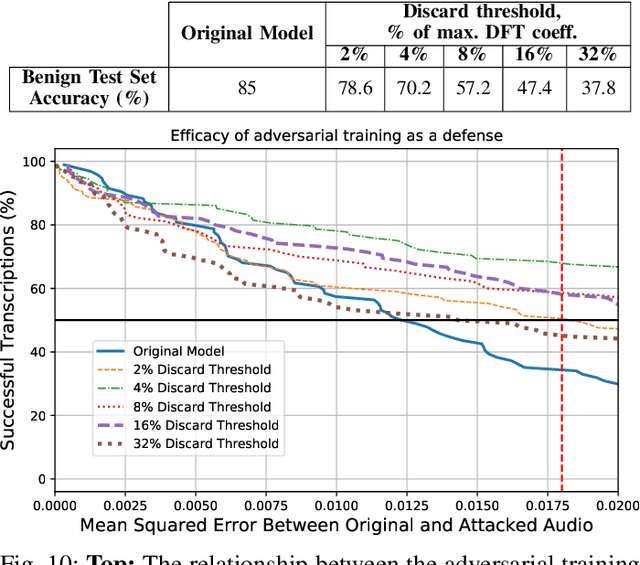
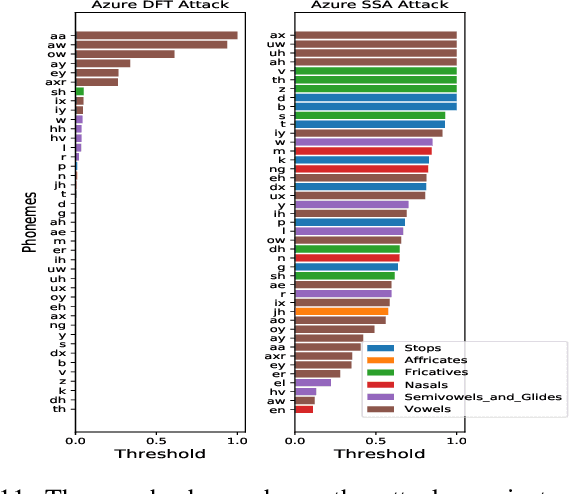
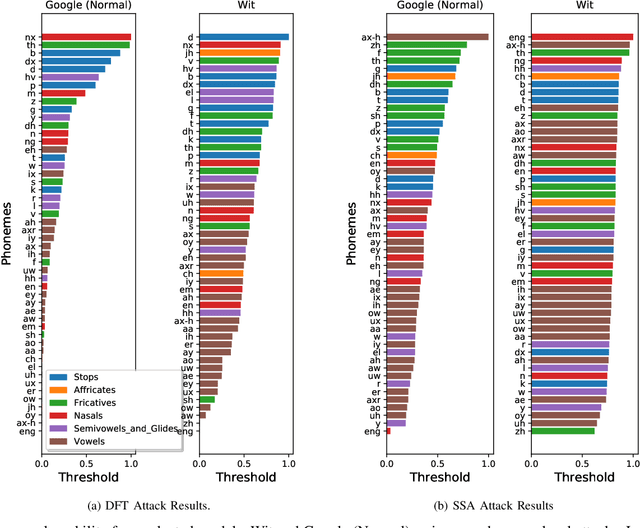
Automatic speech recognition and voice identification systems are being deployed in a wide array of applications, from providing control mechanisms to devices lacking traditional interfaces, to the automatic transcription of conversations and authentication of users. Many of these applications have significant security and privacy considerations. We develop attacks that force mistranscription and misidentification in state of the art systems, with minimal impact on human comprehension. Processing pipelines for modern systems are comprised of signal preprocessing and feature extraction steps, whose output is fed to a machine-learned model. Prior work has focused on the models, using white-box knowledge to tailor model-specific attacks. We focus on the pipeline stages before the models, which (unlike the models) are quite similar across systems. As such, our attacks are black-box and transferable, and demonstrably achieve mistranscription and misidentification rates as high as 100% by modifying only a few frames of audio. We perform a study via Amazon Mechanical Turk demonstrating that there is no statistically significant difference between human perception of regular and perturbed audio. Our findings suggest that models may learn aspects of speech that are generally not perceived by human subjects, but that are crucial for model accuracy. We also find that certain English language phonemes (in particular, vowels) are significantly more susceptible to our attack. We show that the attacks are effective when mounted over cellular networks, where signals are subject to degradation due to transcoding, jitter, and packet loss.
VoiceMoji: A Novel On-Device Pipeline for Seamless Emoji Insertion in Dictation
Dec 22, 2021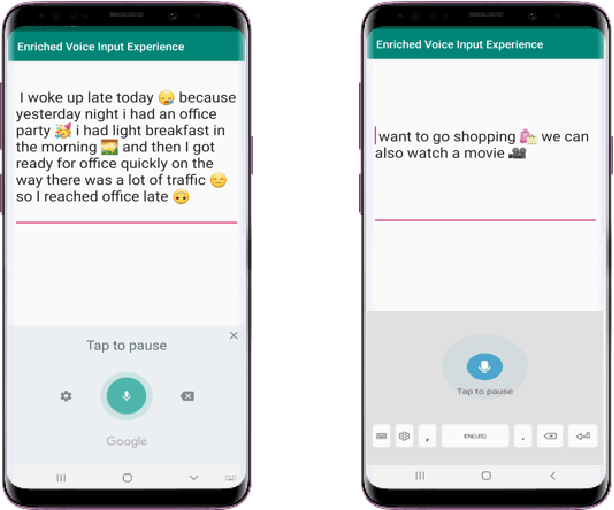
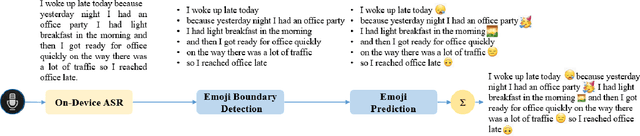

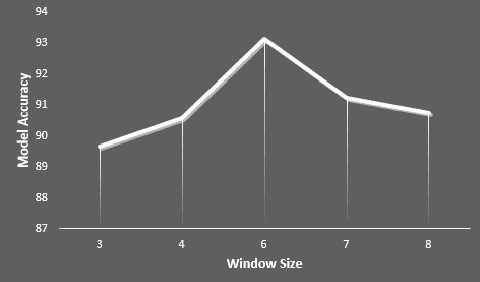
Most of the speech recognition systems recover only words in the speech and fail to capture emotions. Users have to manually add emoji(s) in text for adding tone and making communication fun. Though there is much work done on punctuation addition on transcribed speech, the area of emotion addition is untouched. In this paper, we propose a novel on-device pipeline to enrich the voice input experience. It involves, given a blob of transcribed text, intelligently processing and identifying structure where emoji insertion makes sense. Moreover, it includes semantic text analysis to predict emoji for each of the sub-parts for which we propose a novel architecture Attention-based Char Aware (ACA) LSTM which handles Out-Of-Vocabulary (OOV) words as well. All these tasks are executed completely on-device and hence can aid on-device dictation systems. To the best of our knowledge, this is the first work that shows how to add emoji(s) in the transcribed text. We demonstrate that our components achieve comparable results to previous neural approaches for punctuation addition and emoji prediction with 80% fewer parameters. Overall, our proposed model has a very small memory footprint of a mere 4MB to suit on-device deployment.
FAST-RIR: Fast neural diffuse room impulse response generator
Oct 07, 2021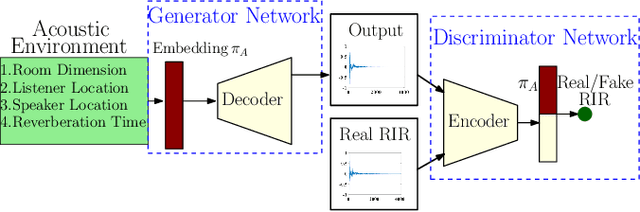
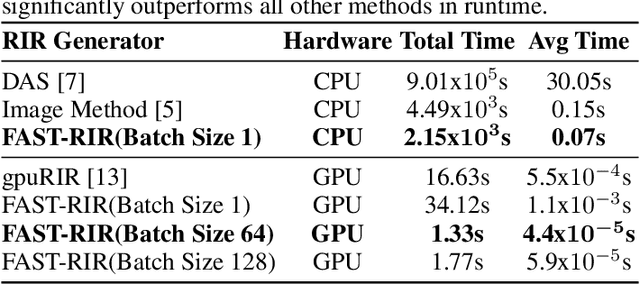

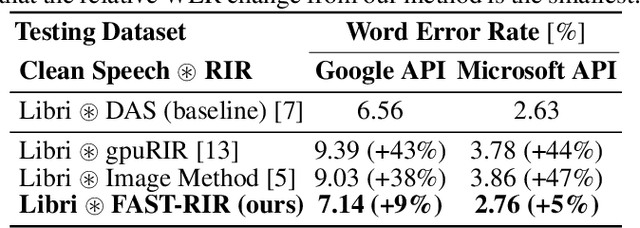
We present a neural-network-based fast diffuse room impulse response generator (FAST-RIR) for generating room impulse responses (RIRs) for a given acoustic environment. Our FAST-RIR takes rectangular room dimensions, listener and speaker positions, and reverberation time as inputs and generates specular and diffuse reflections for a given acoustic environment. Our FAST-RIR is capable of generating RIRs for a given input reverberation time with an average error of 0.02s. We evaluate our generated RIRs in automatic speech recognition (ASR) applications using Google Speech API, Microsoft Speech API, and Kaldi tools. We show that our proposed FAST-RIR with batch size 1 is 400 times faster than a state-of-the-art diffuse acoustic simulator (DAS) on a CPU and gives similar performance to DAS in ASR experiments. Our FAST-RIR is 12 times faster than an existing GPU-based RIR generator (gpuRIR). We show that our FAST-RIR outperforms gpuRIR by 2.5% in an AMI far-field ASR benchmark.
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
Oct 14, 2021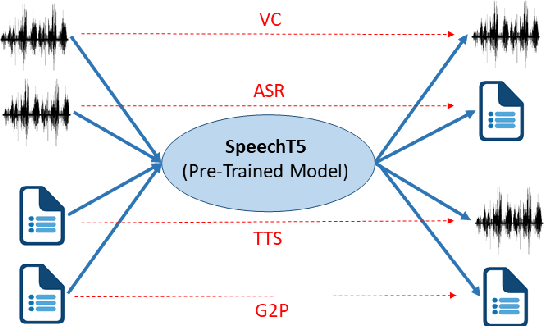
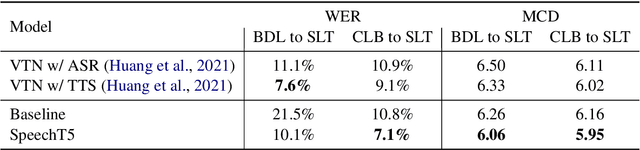
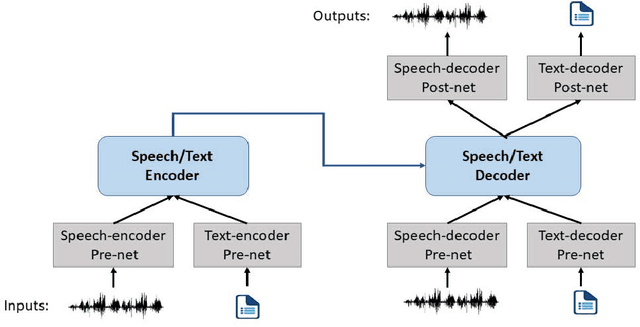
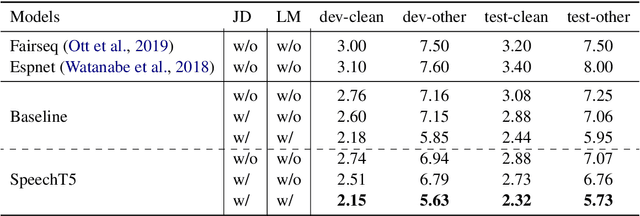
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-training natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the speech/text input through the pre-nets, the shared encoder-decoder network models the sequence to sequence transformation, and then the post-nets generate the output in the speech/text modality based on the decoder output. Particularly, SpeechT5 can pre-train on a large scale of unlabeled speech and text data to improve the capability of the speech and textual modeling. To align the textual and speech information into a unified semantic space, we propose a cross-modal vector quantization method with random mixing-up to bridge speech and text. Extensive evaluations on a wide variety of spoken language processing tasks, including voice conversion, automatic speech recognition, text to speech, and speaker identification, show the superiority of the proposed SpeechT5 framework.
End-to-end Continuous Speech Recognition using Attention-based Recurrent NN: First Results
Dec 04, 2014
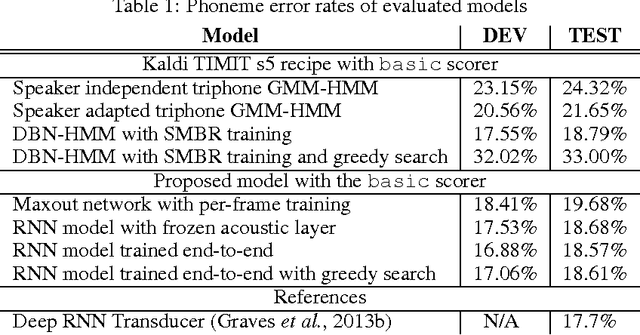
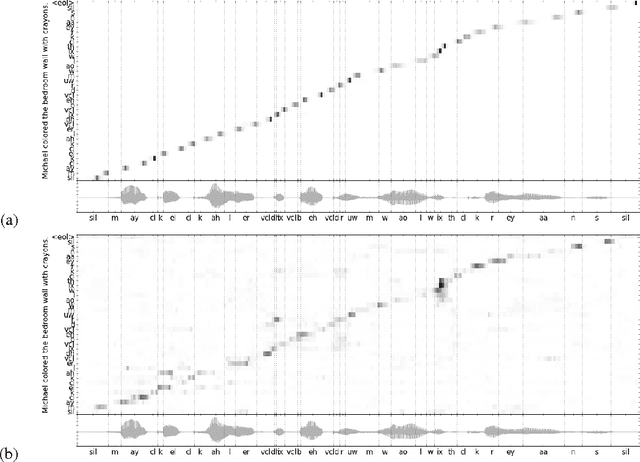
We replace the Hidden Markov Model (HMM) which is traditionally used in in continuous speech recognition with a bi-directional recurrent neural network encoder coupled to a recurrent neural network decoder that directly emits a stream of phonemes. The alignment between the input and output sequences is established using an attention mechanism: the decoder emits each symbol based on a context created with a subset of input symbols elected by the attention mechanism. We report initial results demonstrating that this new approach achieves phoneme error rates that are comparable to the state-of-the-art HMM-based decoders, on the TIMIT dataset.
Learning of Frequency-Time Attention Mechanism for Automatic Modulation Recognition
Nov 05, 2021
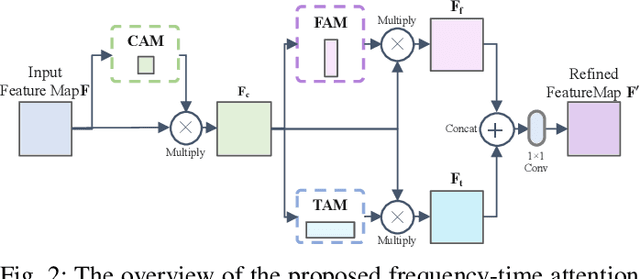
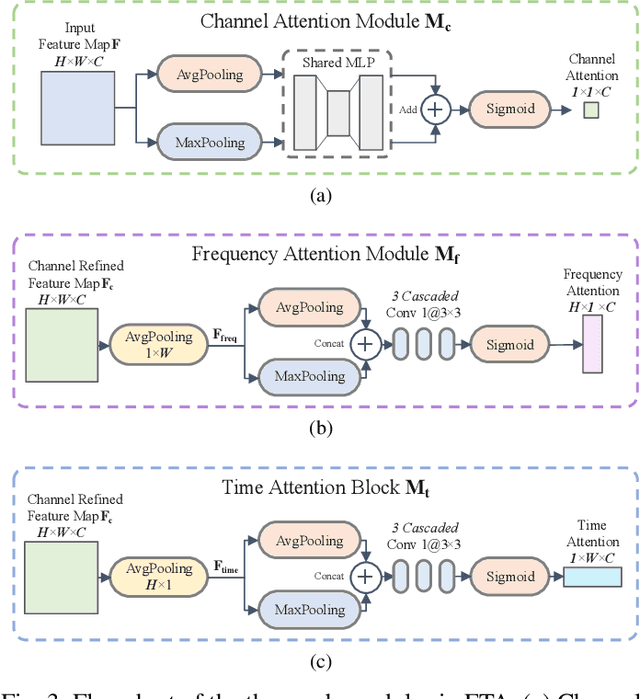
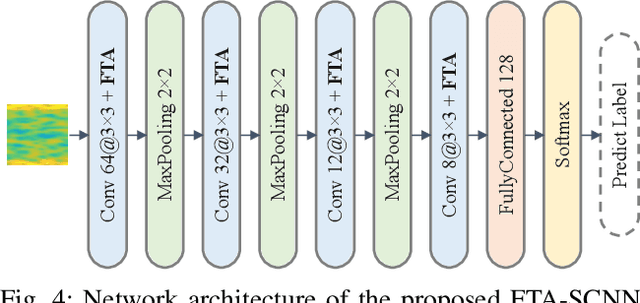
Recent learning-based image classification and speech recognition approaches make extensive use of attention mechanisms to achieve state-of-the-art recognition power, which demonstrates the effectiveness of attention mechanisms. Motivated by the fact that the frequency and time information of modulated radio signals are crucial for modulation mode recognition, this paper proposes a frequency-time attention mechanism for a convolutional neural network (CNN)-based modulation recognition framework. The proposed frequency-time attention module is designed to learn which channel, frequency and time information is more meaningful in CNN for modulation recognition. We analyze the effectiveness of the proposed frequency-time attention mechanism and compare the proposed method with two existing learning-based methods. Experiments on an open-source modulation recognition dataset show that the recognition performance of the proposed framework is better than those of the framework without frequency-time attention and existing learning-based methods.
Learning a Neural Diff for Speech Models
Aug 17, 2021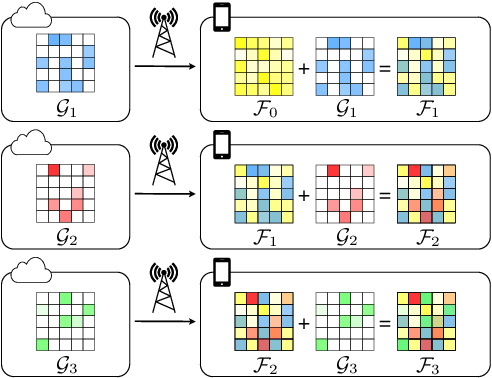
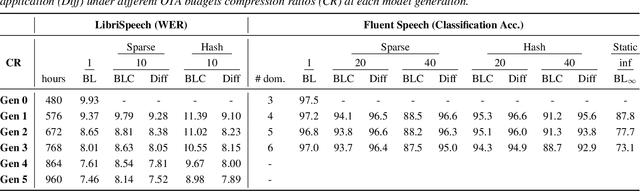
As more speech processing applications execute locally on edge devices, a set of resource constraints must be considered. In this work we address one of these constraints, namely over-the-network data budgets for transferring models from server to device. We present neural update approaches for release of subsequent speech model generations abiding by a data budget. We detail two architecture-agnostic methods which learn compact representations for transmission to devices. We experimentally validate our techniques with results on two tasks (automatic speech recognition and spoken language understanding) on open source data sets by demonstrating when applied in succession, our budgeted updates outperform comparable model compression baselines by significant margins.