 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoTactile: Learning Grasp Pressure for Everyday Objects from Egocentric Video
Jun 08, 2026Estimating full-hand grasp pressure from egocentric video is critical for immersive VR and robotic manipulation, yet dense tactile sensing often relies on intrusive hardware. Existing vision-based methods predominantly rely on planar surfaces or fingertip contacts, failing to generalize to complex 3D object interactions. Therefore, we introduce EgoTactile, a benchmark pairing egocentric video with full-hand pressure supervision for diverse everyday objects, incorporating a bare-hand transfer subset to enable generalization to natural scenarios. Leveraging this benchmark, we first establish EgoPressureFormer as a discriminative baseline. Beyond this, to explicitly address the uncertainty in partial observations, we propose EgoPressureDiff, a conditional diffusion framework that adapts a large-scale pre-trained video diffusion backbone. By combining rich world knowledge priors with a Physically-Informed Feature Rectification layer to inject semantic constraints, our approach effectively infers plausible contact patterns and resolves visual-physical ambiguities. Extensive experiments demonstrate that our method achieves superior performance on the benchmark and robust transferability to in-the-wild scenarios. Our project page is available at https://egotactile.github.io/.
Proposal Refinement for Few-Shot Object Detection
Jun 08, 2026Few-shot object detection has gained widely attention in recent years. Some excellent algorithms have been proposed to handle this task. However, most of these algorithms rely on the performance of few-shot classification. Unlike previous attempts, our work focuses on the problem of unbalanced distribution of region proposals between the novel classes and the base classes. In order to alleviate this unbalanced distribution, we propose the proposal refinement approach for different training phases. Specifically, refinement loss is designed for the base training phase to enhance sensitivity of the model to novel classes, and refinement branch is introduced as an auxiliary branch for RPN (Region Proposal Networks) to generate more novel proposals in the fine-tuning phase. By rebalancing the proposal distribution, the proposed approach outperforms the baselines methods by roughly 1\%$\sim$6\% on current benchmarks without increasing any inference time. Through extensive experiments, we prove that we establish a new state-of-the-art method for the few-shot object detection task.
EgoPressDiff: Multimodal Video Diffusion for Egocentric UV-Domain Hand-Pressure Estimation
Jun 05, 2026Estimating hand-surface contact pressure from an egocentric view is crucial for AR/VR devices, robotic imitation, and ergonomic analysis. Existing methods often discretize pressure signal and process frames independently, leading to quantization errors and temporal inconsistencies. We present \emph{EgoPressDiff}, a conditional video diffusion framework that generates UV-pressure maps from visual input. The core of our approach is a multi-modal conditioning strategy, introducing a PoseNet and a Vertex Encoder to efficiently extract features from hand pose and 3D mesh vertices. These signals, along with depth information, guide the generative process to ensure the pressure fields are physically grounded. To effectively fuse these heterogeneous features, we further propose a Distribution-Calibrated Spatial Layer, which aligns their statistical properties before combination. Evaluated on the EgoPressure ego-view setting, EgoPressDiff achieves state-of-the-art results, improving Volumetric IoU by over 34\% relative to prior baseline, while reducing MAE and maintaining high temporal accuracy. Our project page is at https://egopressdiff.github.io/.
FreeAnimate: Training-Free Human Image Animation with Preview-Guided Denoising
Jun 05, 2026Human Image Animation has seen significant advancements, primarily driven by diffusion models. However, existing methods typically demand substantial training data and resources to achieve high-quality results, limiting generalization and accessibility. In this work, we introduce \emph{FreeAnimate}, a training-free framework that leverages the inherent capabilities of image diffusion models to enable temporal consistency, identity preservation, and background stability. Our approach incorporates a novel preview generation strategy that provides temporal and structural priors from generated preview frames, effectively guiding pose alignment and background consistency without training. Additionally, FreeAnimate introduces Inversion-Boosted Attention and Reference-Anchored Self-Attention modules to guarantee temporal consistency and identity preservation. Experimental results demonstrate that FreeAnimate outperforms existing training-free competitors and training-based baseline methods, achieving generation quality comparable to state-of-the-art methods and offering robust generalization across diverse datasets. Our project page is at https://freeani.github.io/.
Beyond Skeletons: Learning Animation Directly from Driving Videos with Same2X Training Strategy
Jun 05, 2026Human image animation aims to generate a video from a static reference image, guided by pose information extracted from a driving video. Existing approaches often rely on pose estimators to extract intermediate representations, but such signals are prone to errors under occlusion or complex poses. Building on these observations, we present DirectAnimator, a framework that bypasses pose extraction and directly learns from raw driving videos. We introduce a Driving Cue Triplet consisting of pose, face, and location cues that captures motion, expression, and alignment in a semantically rich yet stable form, and we fuse them through a CueFusion DiT block for reliable control during denoising. To make learning dependable when the driving and reference identities differ, we devise a Same2X training strategy that aligns cross-ID features with those learned from same-ID data, regularizing optimization and accelerating convergence. Extensive experiments demonstrate that DirectAnimator attains state-of-the-art visual quality and identity preservation while remaining robust to occlusions and complex articulation, and it does so with fewer computational resources. Our project page is at https://directanimator.github.io/.
Hyb-NeRF: A Multiresolution Hybrid Encoding for Neural Radiance Fields
Nov 21, 2023



Recent advances in Neural radiance fields (NeRF) have enabled high-fidelity scene reconstruction for novel view synthesis. However, NeRF requires hundreds of network evaluations per pixel to approximate a volume rendering integral, making it slow to train. Caching NeRFs into explicit data structures can effectively enhance rendering speed but at the cost of higher memory usage. To address these issues, we present Hyb-NeRF, a novel neural radiance field with a multi-resolution hybrid encoding that achieves efficient neural modeling and fast rendering, which also allows for high-quality novel view synthesis. The key idea of Hyb-NeRF is to represent the scene using different encoding strategies from coarse-to-fine resolution levels. Hyb-NeRF exploits memory-efficiency learnable positional features at coarse resolutions and the fast optimization speed and local details of hash-based feature grids at fine resolutions. In addition, to further boost performance, we embed cone tracing-based features in our learnable positional encoding that eliminates encoding ambiguity and reduces aliasing artifacts. Extensive experiments on both synthetic and real-world datasets show that Hyb-NeRF achieves faster rendering speed with better rending quality and even a lower memory footprint in comparison to previous state-of-the-art methods.
Multi-Channel Attentive Feature Fusion for Radio Frequency Fingerprinting
Mar 19, 2023



Radio frequency fingerprinting (RFF) is a promising device authentication technique for securing the Internet of things. It exploits the intrinsic and unique hardware impairments of the transmitters for RF device identification. In real-world communication systems, hardware impairments across transmitters are subtle, which are difficult to model explicitly. Recently, due to the superior performance of deep learning (DL)-based classification models on real-world datasets, DL networks have been explored for RFF. Most existing DL-based RFF models use a single representation of radio signals as the input. Multi-channel input model can leverage information from different representations of radio signals and improve the identification accuracy of the RF fingerprint. In this work, we propose a novel multi-channel attentive feature fusion (McAFF) method for RFF. It utilizes multi-channel neural features extracted from multiple representations of radio signals, including IQ samples, carrier frequency offset, fast Fourier transform coefficients and short-time Fourier transform coefficients, for better RF fingerprint identification. The features extracted from different channels are fused adaptively using a shared attention module, where the weights of neural features from multiple channels are learned during training the McAFF model. In addition, we design a signal identification module using a convolution-based ResNeXt block to map the fused features to device identities. To evaluate the identification performance of the proposed method, we construct a WiFi dataset, named WFDI, using commercial WiFi end-devices as the transmitters and a Universal Software Radio Peripheral (USRP) as the receiver. ...
Learning to Scale Temperature in Masked Self-Attention for Image Inpainting
Feb 13, 2023Recent advances in deep generative adversarial networks (GAN) and self-attention mechanism have led to significant improvements in the challenging task of inpainting large missing regions in an image. These methods integrate self-attention mechanism in neural networks to utilize surrounding neural elements based on their correlation and help the networks capture long-range dependencies. Temperature is a parameter in the Softmax function used in the self-attention, and it enables biasing the distribution of attention scores towards a handful of similar patches. Most existing self-attention mechanisms in image inpainting are convolution-based and set the temperature as a constant, performing patch matching in a limited feature space. In this work, we analyze the artifacts and training problems in previous self-attention mechanisms, and redesign the temperature learning network as well as the self-attention mechanism to address them. We present an image inpainting framework with a multi-head temperature masked self-attention mechanism, which provides stable and efficient temperature learning and uses multiple distant contextual information for high quality image inpainting. In addition to improving image quality of inpainting results, we generalize the proposed model to user-guided image editing by introducing a new sketch generation method. Extensive experiments on various datasets such as Paris StreetView, CelebA-HQ and Places2 clearly demonstrate that our method not only generates more natural inpainting results than previous works both in terms of perception image quality and quantitative metrics, but also enables to help users to generate more flexible results that are related to their sketch guidance.
Collaborative 3D Object Detection for Automatic Vehicle Systems via Learnable Communications
May 24, 2022
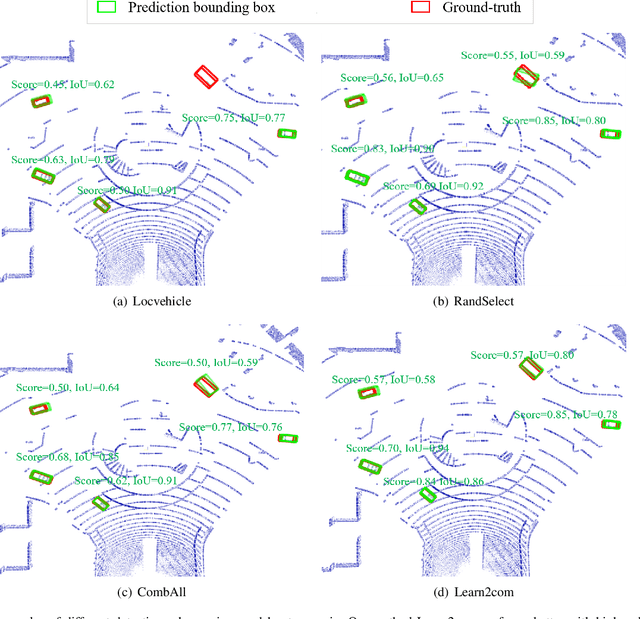
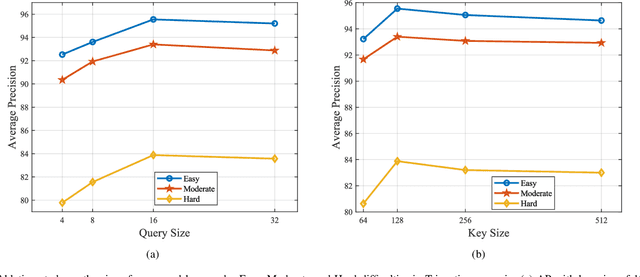
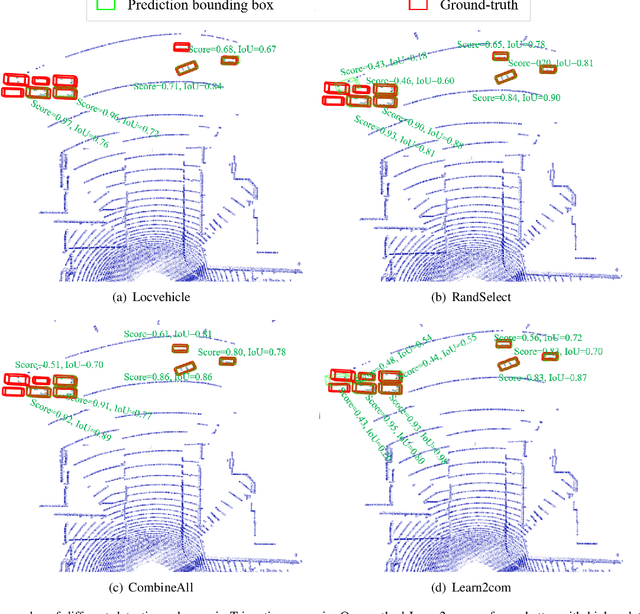
Accurate detection of objects in 3D point clouds is a key problem in autonomous driving systems. Collaborative perception can incorporate information from spatially diverse sensors and provide significant benefits for improving the perception accuracy of autonomous driving systems. In this work, we consider that the autonomous vehicle uses local point cloud data and combines information from neighboring infrastructures through wireless links for cooperative 3D object detection. However, information sharing among vehicle and infrastructures in predefined communication schemes may result in communication congestion and/or bring limited performance improvement. To this end, we propose a novel collaborative 3D object detection framework that consists of three components: feature learning networks that map point clouds into feature maps; an efficient communication block that propagates compact and fine-grained query feature maps from vehicle to support infrastructures and optimizes attention weights between query and key to refine support feature maps; a region proposal network that fuses local feature maps and weighted support feature maps for 3D object detection. We evaluate the performance of the proposed framework using a synthetic cooperative dataset created in two complex driving scenarios: a roundabout and a T-junction. Experiment results and bandwidth usage analysis demonstrate that our approach can save communication and computation costs and significantly improve detection performance under different detection difficulties in all scenarios.
Learning of Frequency-Time Attention Mechanism for Automatic Modulation Recognition
Nov 05, 2021
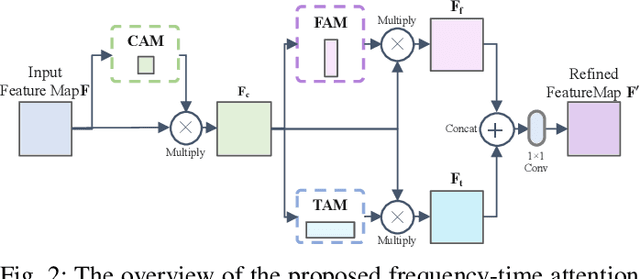
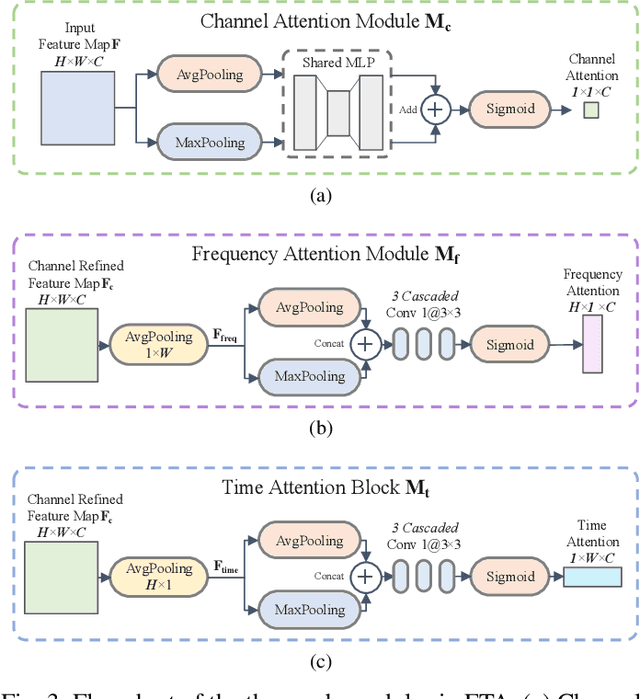
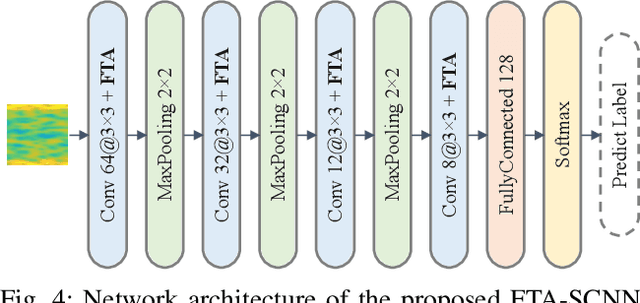
Recent learning-based image classification and speech recognition approaches make extensive use of attention mechanisms to achieve state-of-the-art recognition power, which demonstrates the effectiveness of attention mechanisms. Motivated by the fact that the frequency and time information of modulated radio signals are crucial for modulation mode recognition, this paper proposes a frequency-time attention mechanism for a convolutional neural network (CNN)-based modulation recognition framework. The proposed frequency-time attention module is designed to learn which channel, frequency and time information is more meaningful in CNN for modulation recognition. We analyze the effectiveness of the proposed frequency-time attention mechanism and compare the proposed method with two existing learning-based methods. Experiments on an open-source modulation recognition dataset show that the recognition performance of the proposed framework is better than those of the framework without frequency-time attention and existing learning-based methods.